






1. 上升的温度

select a.id
from Weather a join Weather b
on a.Temperature > b. Temperature
and datediff(a.recordDate,b.recordDate)=1- datediff(日期1, 日期2): 得到的结果是日期1与日期2相差的天数。 如果日期1比日期2大,结果为正;如果日期1比日期2小,结果为负。
- 满足on后面的两个条件的才会被join上
2. 每台机器的进程平均运行时间

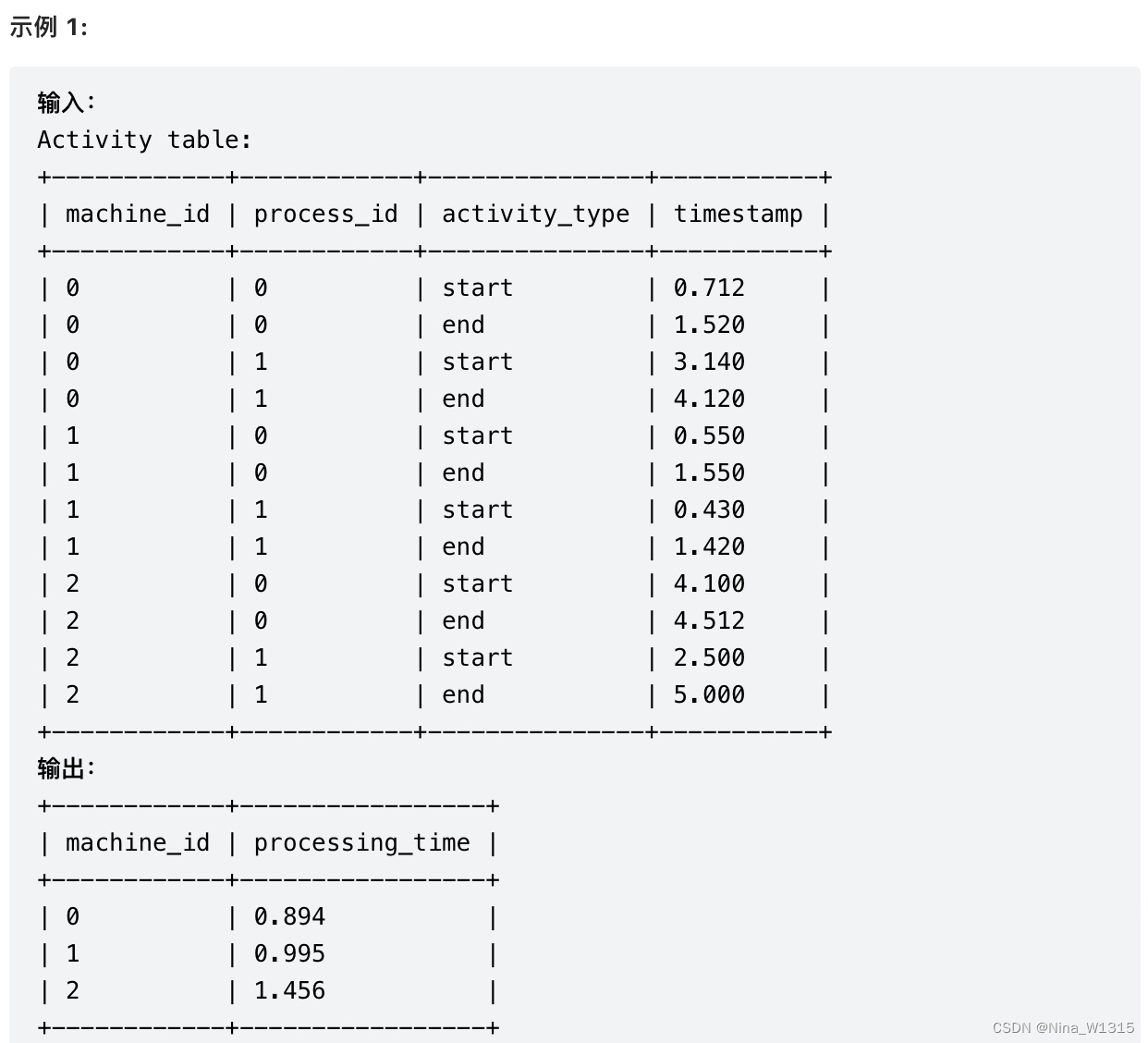
select
machine_id
,round(sum(if(activity_type = "start", -timestamp,timestamp))/count(distinct process_id),3) as processing_time
from Activity
group by machine_id- 注意IF函数的使用方法
SELECT column_name,
IF(condition, result1, result2) AS new_column
FROM table_name;- 注意count的聚合方法
3. 员工奖金
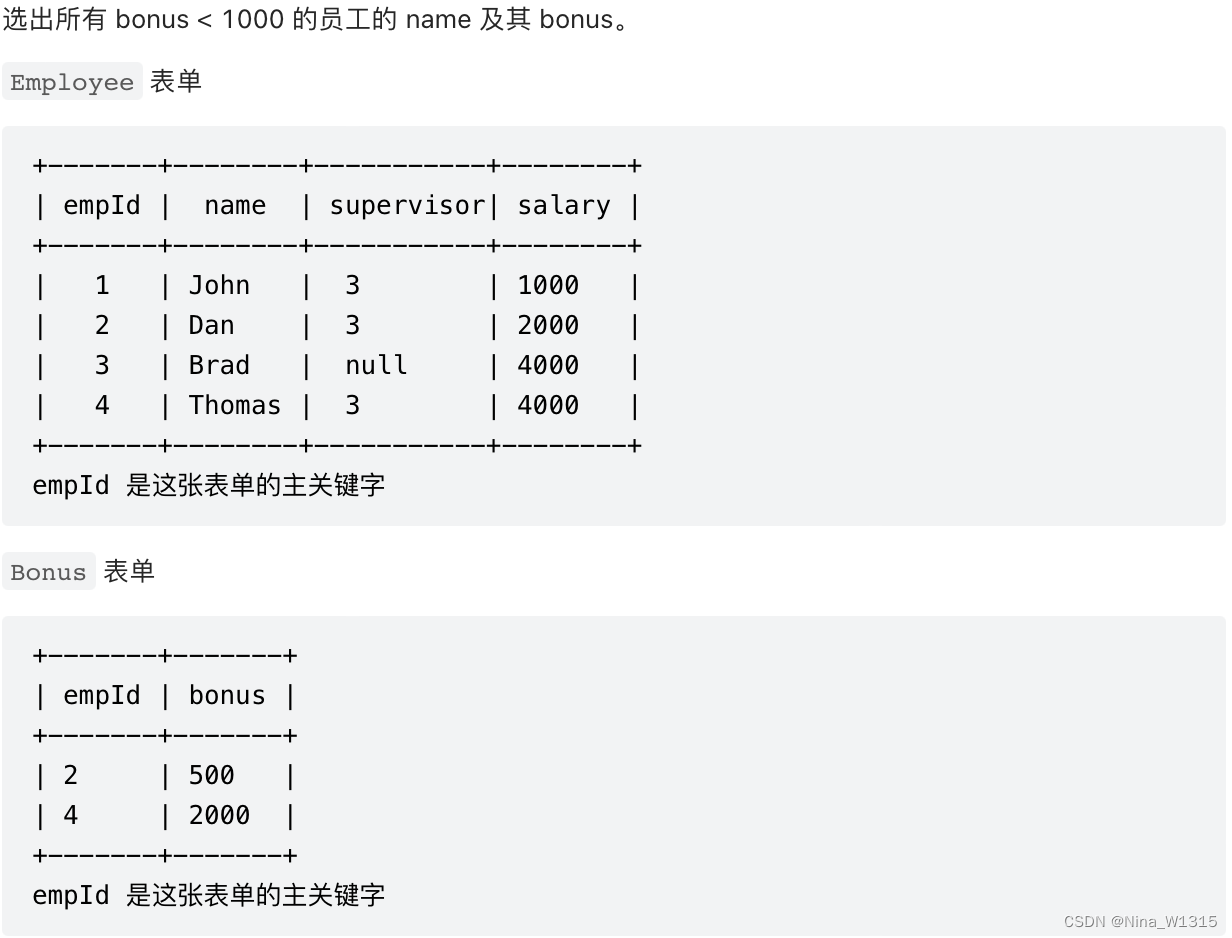

select E.name,B.bonus from Employee E
left join Bonus B on E.empId=B.empId
where ifnull(B.bonus,0) < 1000- 注意ifnull()的使用:ifnull(a,b),如果a不是Null则是a,如果a是null则是b
4. 学生们参加各科测试的次数


# Write your MySQL query statement below
select
S1.student_id
,S1.student_name
,S2.subject_name
,count(E.subject_name) as attentded_exams
from Students S1
cross join Subjects S2 #全链接得到每个学生对应每个科目
left join Examinations E
on S1.student_id=E.student_id and e.subject_name=S2.subject_name
group by S1.student_id,S2.subject_name
order by S1.student_id,S2.subject_name
- 计数不能用count(*),这样空值也会记为1
-
count(条件)不管记录是否满足条件表达式,只要非NULL就加1
- 全连接subject表的意义:如果只用subject_name表就没办法得到学生没参加某个学科的考试的记录,就像bob,没参加physics,就不会出现。所以要先进行学生和学科的笛卡尔积,得到全匹配结果,然后在跟考试表关联得到具体次数
5. 查询结果的质量和占比
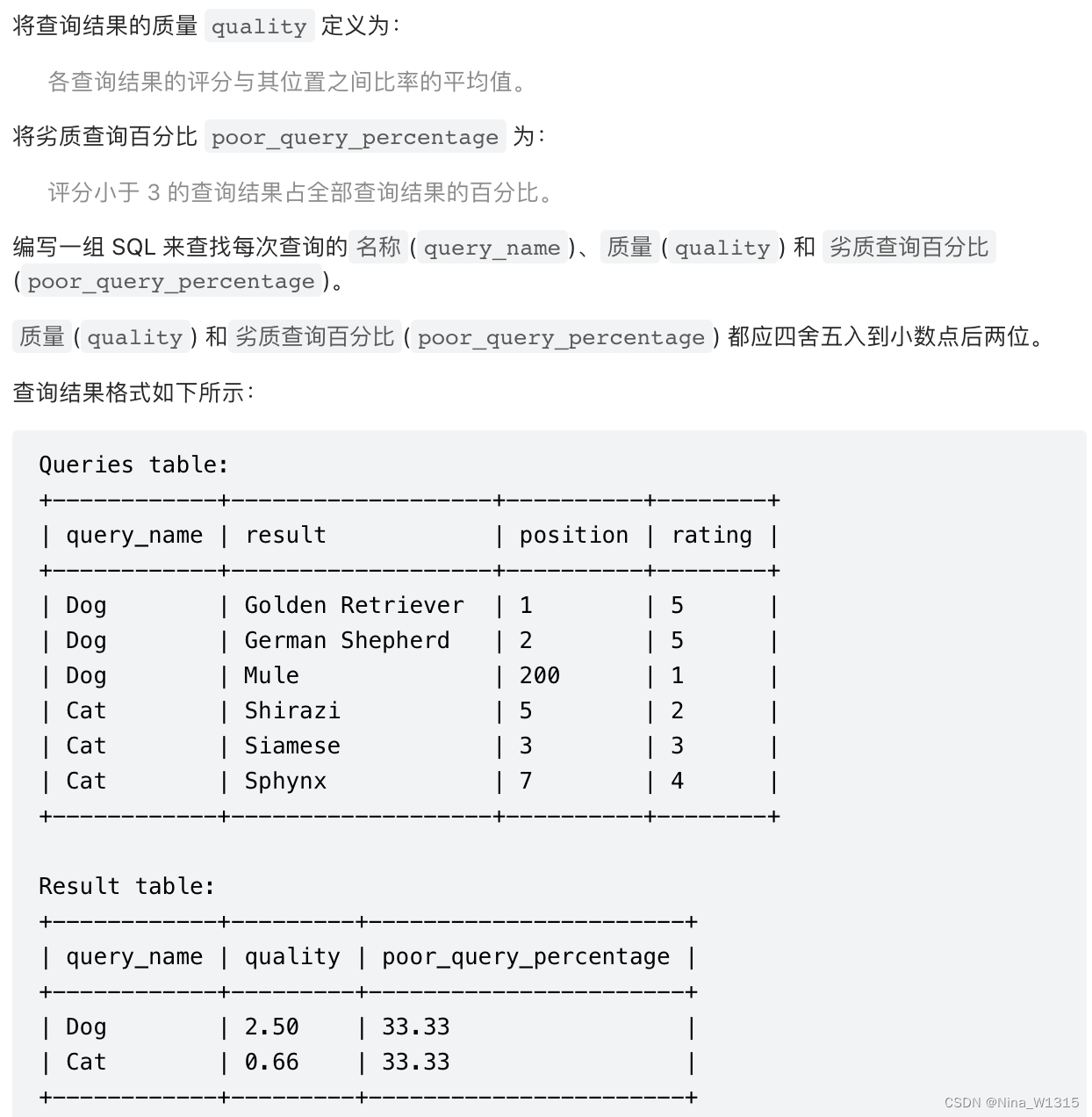
select query_name
,round(avg(rating / position), 2) as quality
,round(sum(if(rating <3, 1, 0))*100 / count(*),2)
as poor_query_percentage
from queries
group by query_name
- 注意IF的用法:if (条件,a,b),如果满足条件则为a,不满足为b
6. 即时食物配送 II

# 方法1:average+row_number
select
round(100* avg(order_date = customer_pref_delivery_date),2)
as immediate_percentage
from
(select *,row_number()over(partition by customer_id order by order_date)rk from Delivery)t
where rk=1
# 方法2: where in min()+sum(if)
select
round(
100*sum(if(order_date = customer_pref_delivery_date,1,0))/count(*)
,2) as immediate_percentage
from Delivery
where (customer_id,order_date) in
(select customer_id,min(order_date)
from Delivery
group by customer_id)
7. 查询近30天活跃用户数
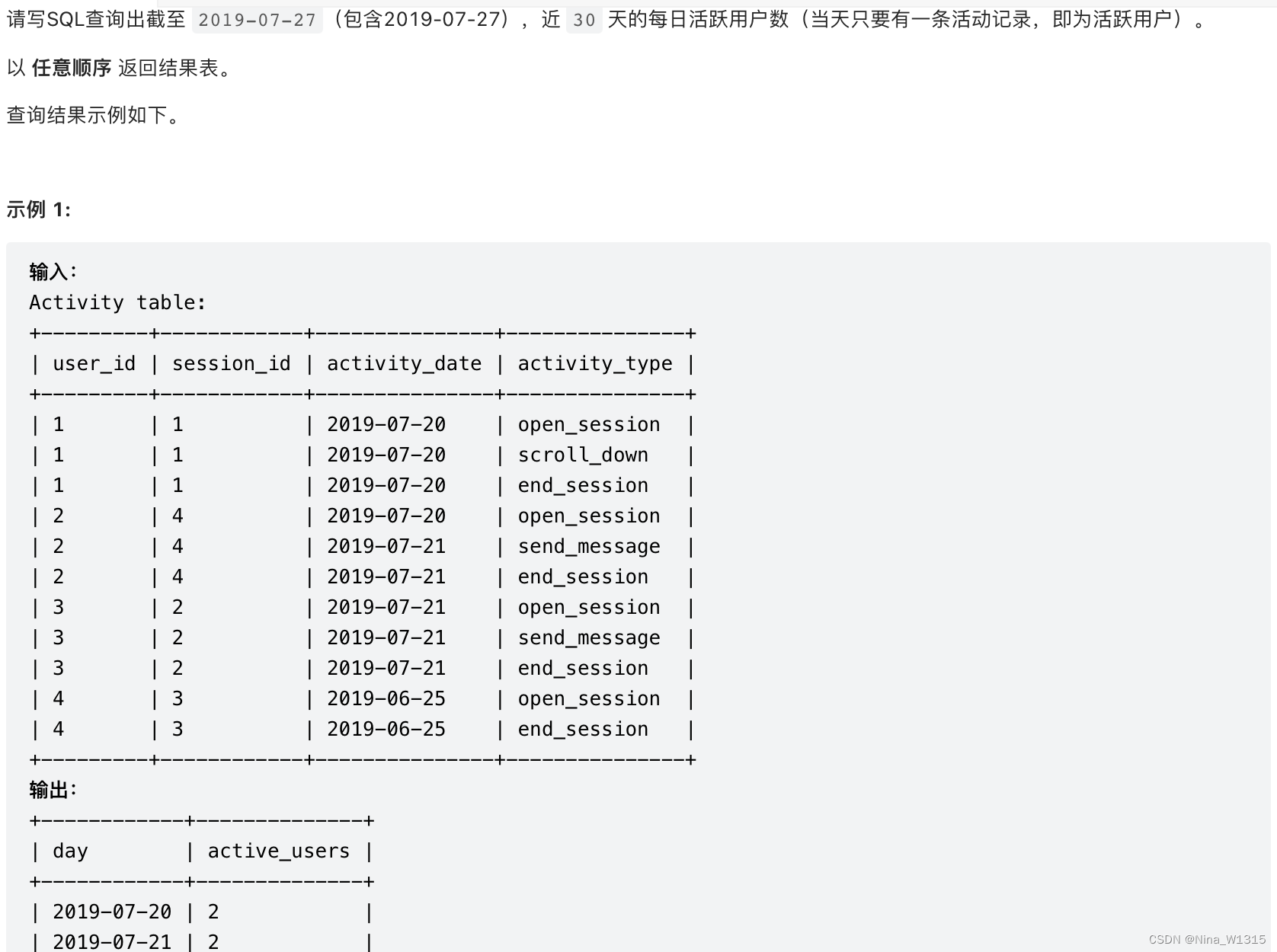
select activity_date as day
,count(distinct user_id) as active_users
from Activity
where activity_date > date_sub('2019-07-27', interval 30 day)
and activity_date <= '2019-07-27'
group by activity_date- 从指定日期/时间减去/加上一定的时间
- DATE_SUB(起始日期/时间,时间间隔)
- DATE_ADD('2023-05-27', INTERVAL 2 DAY)
- DATE_ADD(HOUR, -3, '2023-05-27 10:00:00')
- TIMESTAMPADD(HOUR, 3, '10:30:00') 给指定时间加上3小时
8. 销售分析III 
方法一:先聚合,找到最大最小值再限制
SELECT P.product_id, P.product_name
FROM Product P
JOIN Sales S ON P.product_id = S.product_id
GROUP BY P.product_id, P.product_name
HAVING MIN(S.sale_date) >= '2019-01-01' AND MAX(S.sale_date) <= '2019-03-31';
方法二:先聚合,然后用sum(条件)来计数
SELECT p.product_id,product_name FROM sales s,product p
WHERE s.product_id=p.product_id
GROUP BY p.product_id
HAVING SUM(sale_date < '2019-01-01')=0
AND SUM(sale_date>'2019-03-31')=0;9. 员工的直属部门
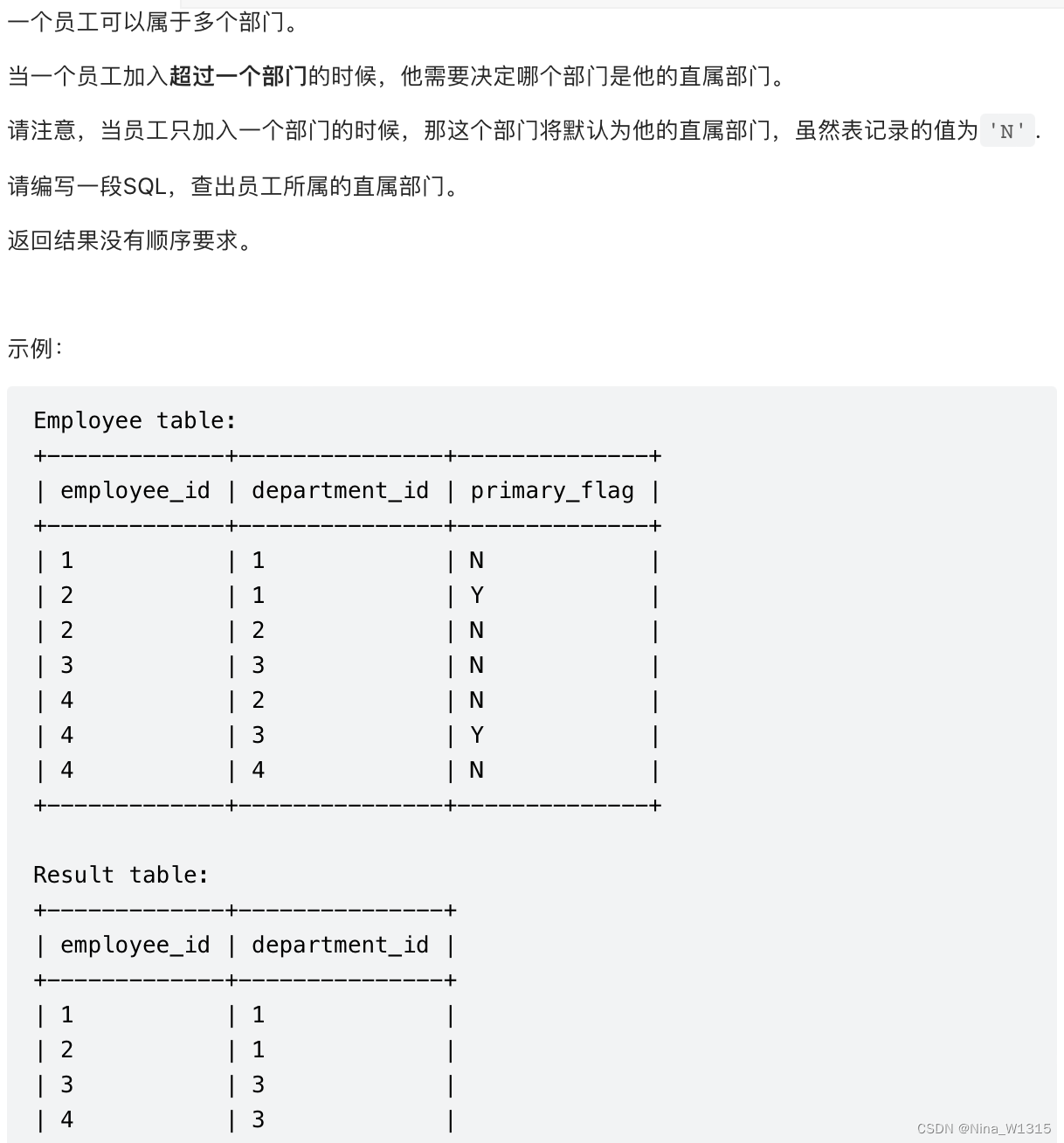
1. 创建一张公用表t,选出flag=Y或计数项cnt=1的员工
with t as(
select *,count(1) over(partition by employee_id) cnt
from Employee
)
select employee_id,department_id from t where primary_flag='Y' or cnt=1- 注意窗口函数不是只能排序,还可以进行其它聚合
2. 根据员工id以flag进行组内排序选出rk为1的即可
with t as(
select *,row_number() over(partition by employee_id order by primary_flag) rk
from Employee
)
select employee_id,department_id from t where rk = 1
[注意]在本题目的SQL架构中,可以看到 Create table If Not Exists Employee (employee_id int, department_id int, primary_flag ENUM('Y','N')) ,这意味着 primary_flag是一个ENUM类型的数据,而ENUM类型的数据本身是具有顺序的,如 ENUM('Y','N') 代表Y是1,N是2,依次类推。所以在对 primary_flag这个字段排序时,不会按照值本身的alphabet顺序(n在前,y在后),而是按照写入数据的顺序(y在前,n在后)3. 用union把只有1个部门的员工和属于主要部门的员工做联合
select employee_id,department_id from Employee
group by 1 having count(1) = 1
union
select employee_id,department_id from Employee
where primary_flag = 'Y'10. 连续出现的数字

select distinct num as ConsecutiveNums
from
(select num
,lead(num,1) over (order by id) as next1
,lead(num,2) over (order by id) as next2
from Logs)t
where num = next1 and next1 = next2LEAD()函数用于获取当前行的后一行的值。LAG()函数用于获取当前行的前一行的值。- where条件中不能直接写a=b=c,只能两两比较
11. 指定日期的产品价格
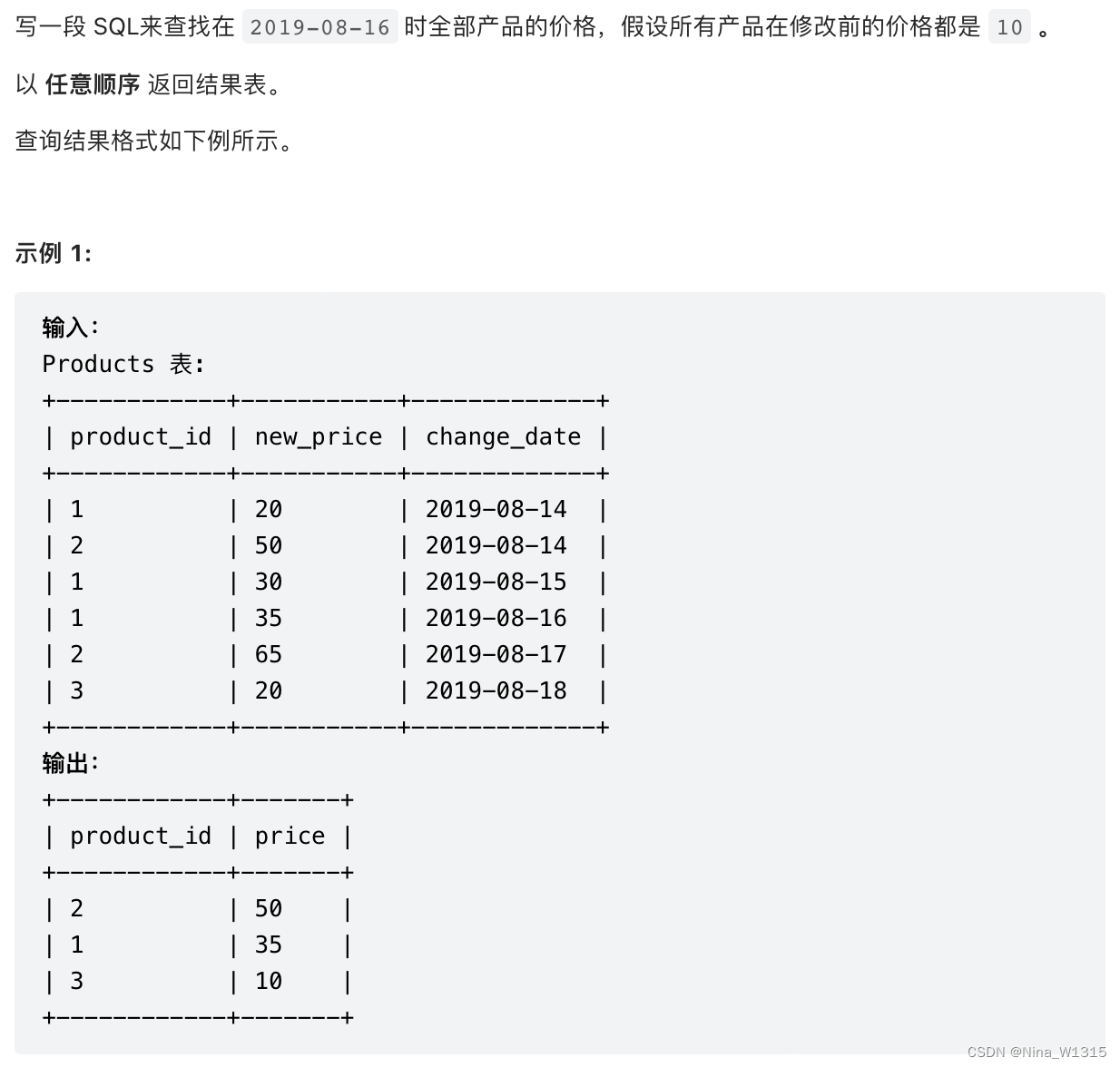
方法一:两部分处理分UNION再rk筛选
select product_id
,case
when rk=1 then new_price
else 10
end as price
from
(select product_id,new_price,change_date
,row_number() over (partition by product_id order by change_date desc)rk
from Products
where change_date<="2019-08-16"
UNION
select product_id,new_price,change_date
,0 as rk
from Products
where change_date>"2019-08-16")t
group by product_id
方法二:匹不上的用ifnull分类处理
select distinct p1.product_id, ifnull(p2.new_price,10) pirce
from Product p1
left join
(select *,row_number() over(partition by product_id order by change_date desc)rk)
from Products
where change_date <= "2019-08-16")p2
on p1.product_id = p2.product_id and rk = 1 - 注意方法二中rk=1的使用,可以吧rk=1当作匹配条件放在on里,rk=1的才会被匹配
12. 按分类统计薪水

with a as #目前所有收入的分类结果,每个account_id是什么category
(select account_id,
case
when income > 50000 then "High Salary"
when income <20000 then "Low Salary"
else "Average Salary"
end as category
from Accounts),
b as #得到一列包含所有类别的列表
(select "Low Salary" as category
union
select "Average Salary" as category
union
select "High Salary" as category),
c as #统计a的每个category有多少account_id
(select category,count(*) as accounts_count from a
group by category)
select b.category,ifnull(c.accounts_count,0) accounts_count
#现有的统计匹配所有类别,匹配不上的用ifnull填充0
from b
left join c
on b.category = c.category- 注意:直接用group by的话无法显示为0的类别,所以要join全量类别列表,然后把匹配不上的用ifnull填充0
- 注意b表直接生成值的方法select 1 as "XX"
13. 餐馆营业额变化增长

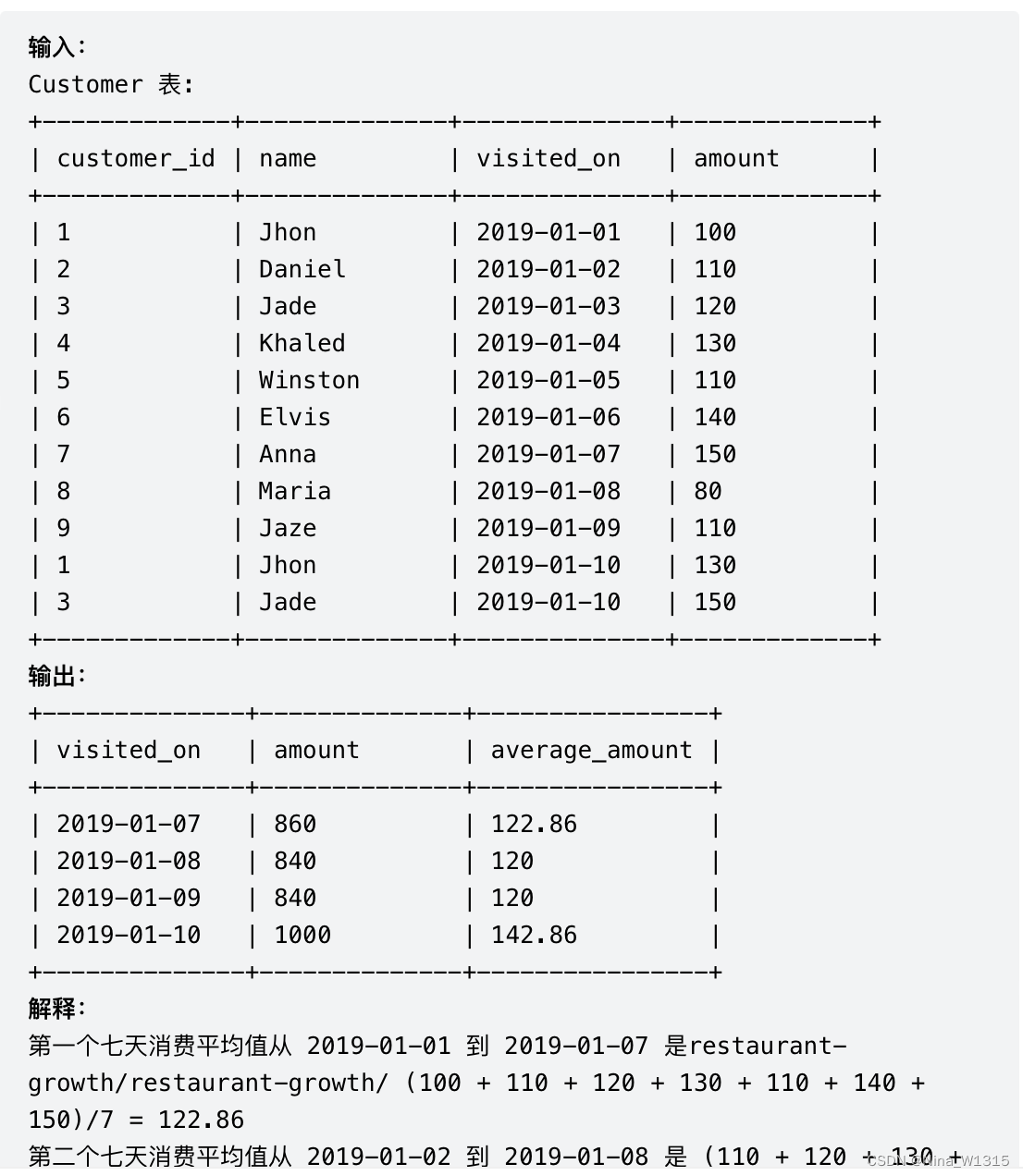
#2.两个窗口函数取向前滚动6天的sum和avg
select visited_on,sum_amount as amount,round(average_amount,2)
from
(select
visited_on
,sum(amount) over(order by visited_on rows 6 preceding) as sum_amount
,avg(amount) over(order by visited_on rows 6 preceding) as average_amount
from
#1. 把每天的金额先汇总
(select visited_on,sum(amount) as amount from Customer
group by visited_on)t1
)t2
#3.框定需要向前累加的日期范围用datediff,和最小日期差至少6天及以上才能累加
where datediff(visited_on,(select min(visited_on) from Customer))>=6- 向前向后几天滚动累加聚合的问题可以使用窗口函数
- rows n preceding 是包括当前行和之前n行的累加
- following在聚合时不包含当前行,与current联用
1. ROWS
// 当前行与后面所有行的累加
sum(sales_volume) over(partition by id rows between current row and unbounded following) sum_sales//前面所有行与当前行的累加
sum(sales_volume) over(partition by id rows between unbounded preceding and current row) sum_sales
//当前行与后两行的累加
sum(sales_volume) over(partition by id rows between current row and 2 following) sum_sales
//前一行与当前行的累加
sum(sales_volume) over(partition by id rows between 1 preceding and current row) sum_sales
等价于:
sum(sales_volume) over(partition by id rows 1 preceding) sum_sales//前一行的值+当前行的值+后一行的值
sum(id) over(partition by category rows between 1 preceding and 1 following) rank from t
//取当前行及前两条及后两条来参与计算,一般用于移动平均值
rows between 2 preceding and 2 following
//起始行到末尾行
rows between unbounded preceding and unbounded following
2. RANGE
rows表示 行,就是前n行,后n行
而range表示的是 具体的值,比这个值小n的行,比这个值大n的行
range between是以当前值为锚点进行计算
range between 4 preceding AND 7 following
//表示:如果当前值为10的话就取前后的值在6到17之间的数据。
SUM(salary) OVER(PARTITION BY dept_id ORDER BY hire_date RANGE BETWEEN UNBOUNDED PRECEDING AND 365/*value_expr*/ PRECEDING)
//窗口范围为该分区内小于本记录hire_date-365天的所有的薪资累计ROWS:是按物理行来进行窗口级别里再次进行范围选择的。
RANGE:是按逻辑行来进行窗口级别里再次进行范围选择的。RANGE时,相同行会被合并成同一条数据再进行计算,相同行窗口计算时的结果也是相同的。
是否是相同行,是根据ORDER BY排序时的结果决定的。
有ORDER BY时:同行是说在ORDER BY排序时不唯一的行。【即具有相同数值的行】
不同行是说ORDER BY排序时具有不同的数值的行。
没有ORDER BY:那么就是当前分区的所有行都包含在框架中,因为所有行都会成为当前行的相同行。【特别要注意最后一句的意思】
14. 2016年的投资
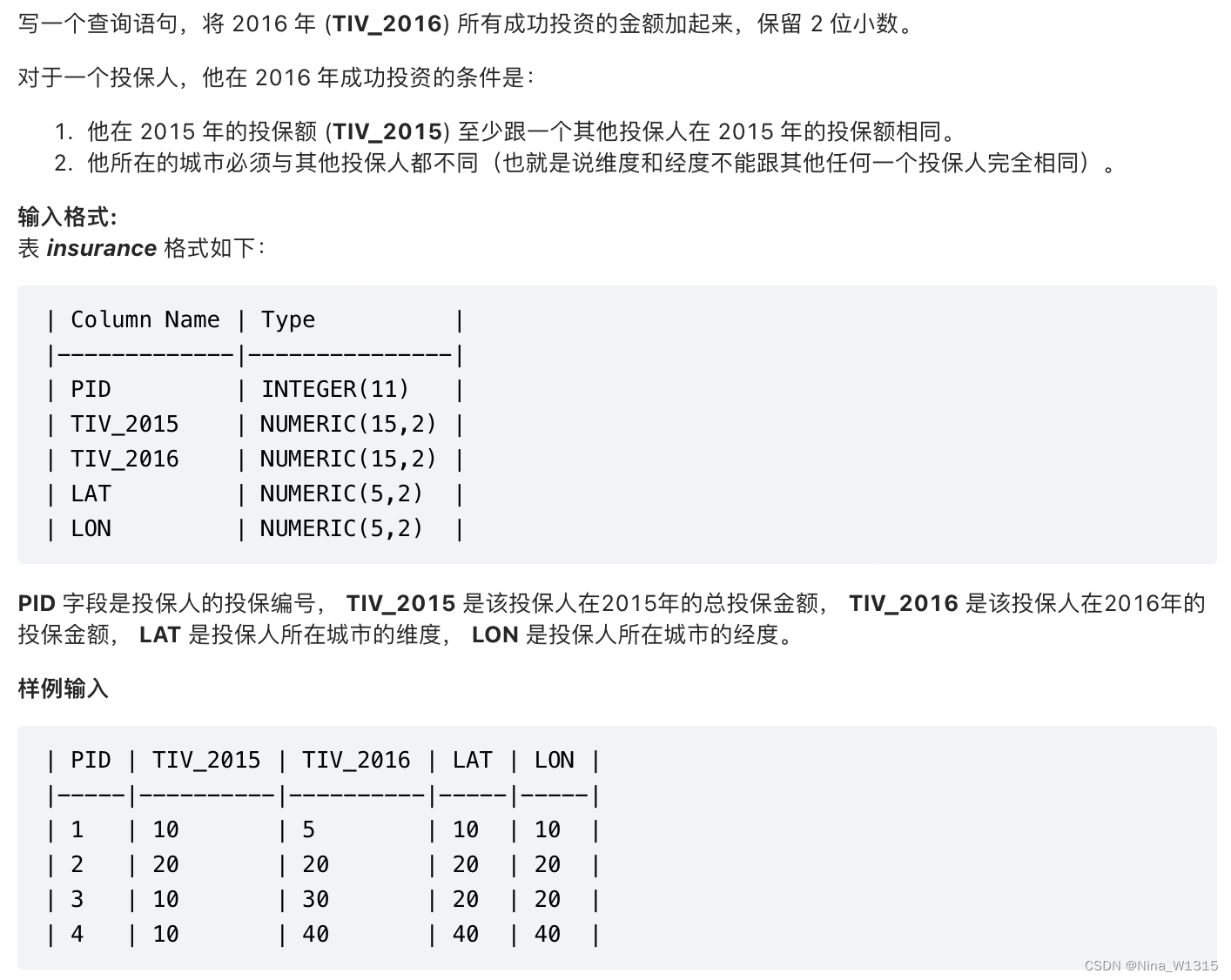

#concat的用法,组合两个值或两个字符成字符串
select round(sum(TIV_2016),2) TIV_2016 from insurance
where TIV_2015 in (select TIV_2015 from insurance group by TIV_2015 having count(*)>1)
and
concat(lat,lon) in (select concat(lat,lon) from insurance group by concat(lat,lon) having count(*)=1)
# concat(lat,lon)的结果是“1010”,“4040”
#窗口函数用法
select round(sum(TIV_2016),2) as TIV_2016
from
(select
*
,count(PID) over(partition by TIV_2015) as num_tiv
#按TIV_2015分类统计
,count(PID) over(partition by lat,lon) as num_city
#按lat,lon组合分类统计
from insurance)t
where t.num_tiv > 1 and t.num_city = 1- 注意concat(column1,column2)组合成 "column1,column2"
- 注意窗口函数,按某个分类count的用法,或按某两个列值组合分类count的用法
15. 删除重复的电子邮箱

DELETE from Person
where id in
(SELECT id
from
(SELECT id,email,row_number() over(partition by email order by id) as rk
from Person)t1
where rk > 1);- 注意删除数据的用法
16. 第二高的薪水

select ifnull(
(select salary
from
(select distinct salary
,dense_rank() over(order by salary desc) rk
from Employee)t
where rk = 2)
,null) as SecondHighestSalary
select IFNULL(
(select distinct(Salary)
from Employee
order by Salary desc
limit 1,1)
,null) as SecondHighestSalary- 注意ifnull()的使用也可以套在最外面
- 注意limit n,m的使用
17. 按日期分组销售产品

select
sell_date,
# 获取“不同的”产品数【count(distinct product)】
count(distinct product) as num_sold,
# “不同的”【distinct product】产品按照字典排序【order by product】 & “,”分割【separator ','】
group_concat(distinct product order by product separator ',') as products
from Activities
group by sell_date
order by sell_date;- 注意group concat()的用法:将分组中括号里对应的字符串进行连接.如果分组中括号里的参数xxx有多行,那么就会将这多行的字符串连接,每个字符串之间会有特定的符号进行分隔
18. 查找拥有有效邮箱的用户

方法一
select * from Users
where right(mail,13)= "@leetcode.com"
and patindex('[A-Za-z]%,mail')=1
and substr(mail,1,length(mail)-13) not like "%[^A-Za-z0-9._-]%"
方法二
select * from Users where mail rlike '^[a-z|A-Z][0-9|a-z|A-Z|_|.|/|-]*@leetcode\\.com$';
方法三
select * from users
where mail REGEXP '^[a-zA-Z][0-9a-zA-Z\-\_\\.]*@leetcode\\.com$'
#.点符号需要两次转译\\- 注意正则式的用法:
-
REGEXP 就是 regular expression 正则表达式 的意思
^ 表示以后面的字符为开头
[] 表示括号内任意字符
- 表示连续
* 表示重复前面任意字符任意次数
\ 用来转义后面的特殊字符,以表示字符原本的样子,而不是将其作为特殊字符使用
$ 表示以前面的字符为结尾
-















 246
246











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









