






1. 购买了产品 A 和产品 B 却没有购买产品 C 的顾客

方法一:having聚合中使用sum(判断条件)进行筛选
select o.customer_id,customer_name
from Orders o,customers c
on o.customer_id=c.customer_id
group by o.customer_id
having sum(product_name='A')>0 and sum(product_name='B')>0 and sum(product_name='B')=0
方法二:where+子查询
SELECT customer_id,customer_name
FROM Customers
WHERE
customer_id IN(SELECT customer_id FROM Orders WHERE product_name='A')
AND
customer_id IN(SELECT customer_id FROM Orders WHERE product_name='B')
AND
customer_id NOT IN(SELECT customer_id FROM Orders WHERE product_name='C')
方法三:group_concat拼接+regexp筛选
with t as
(select c.*,group_concat(product_name order by product_name separator '') p
from customers c
left join orders o
on c.customer_id = o.customer_id
group by customer_id)
select customer_id,customer_name from t
where p regexp 'AB([^C]|$)'
#该正则表达式用于匹配以 "AB" 开头,并且后面的字符要么不是 "C",要么是字符串的结尾的字符串
- sum(判断条件)可以进行筛选符合条件的个数,直接加在having里
- group_concat是用来拼一个group中的所有值,可以order by 加顺序,和separator ''分隔符
- regexp中,
'AB'之前没有使用^,意味着'AB'可以出现在字符串的任何位置,而不仅仅是开头
2. 没有卖出的卖家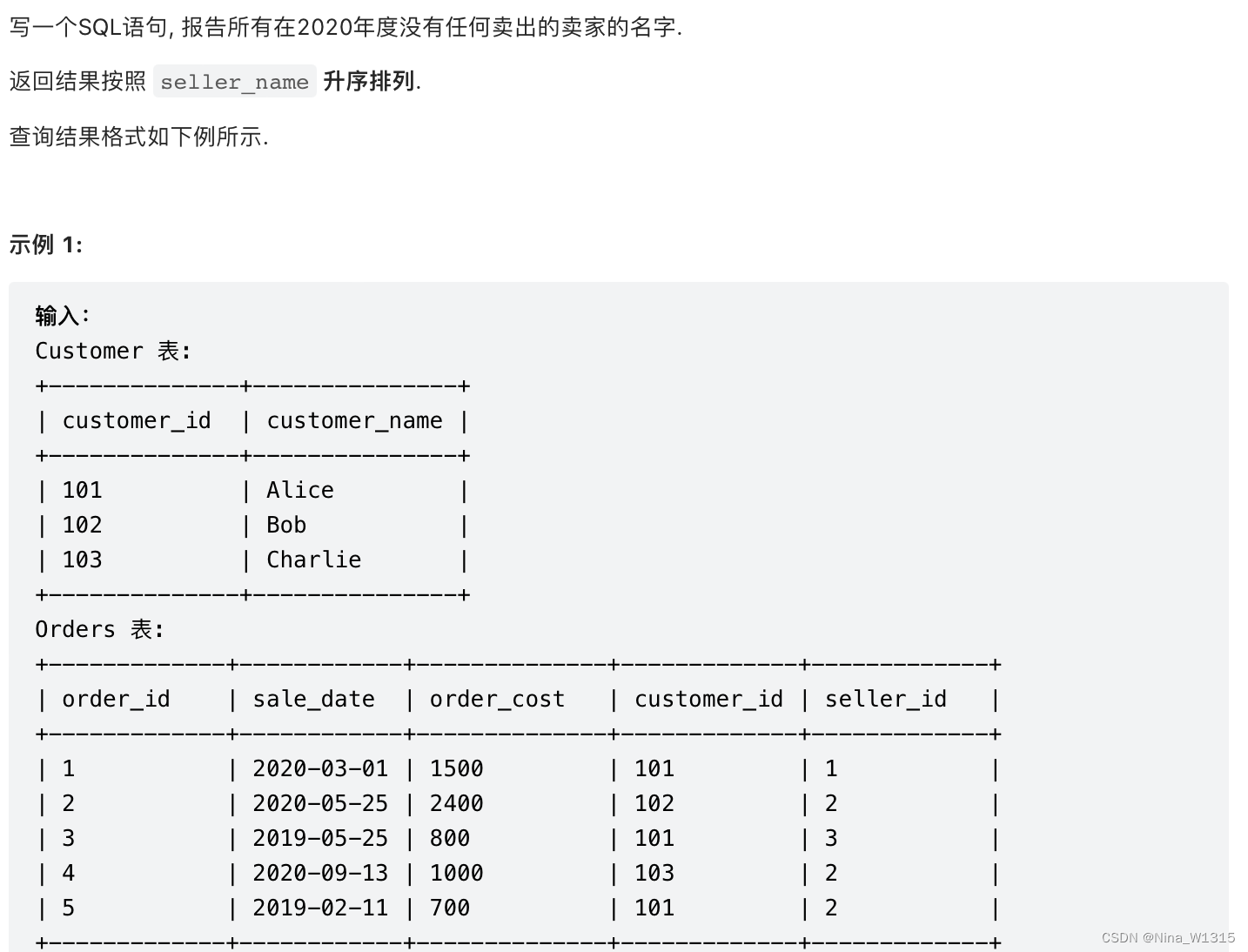

方法一:not in + where
select seller_name from Seller
where seller_id not in(
select seller_id
from Orders
where substr(sale_date,1,4)='2020')
order by seller_name
方法二:拼不上的就是无订单的
select
seller_name
from
Seller a
left join
Orders b
on a.seller_id=b.seller_id
and year(sale_date)=2020
where b.order_id is null
order by seller_name
#给seller名单匹配2020年的order_id,匹不上的就是没有2020年的订单
#错误代码
select seller_name from Seller
where seller_id in(
select seller_id
from Orders
group by seller_id
having sum(substr(sale_date,1,4)='2020')=0)
order by seller_name
# 这段代码会漏掉order表中无论哪一年都一笔订单没有的seller_id,改为:
select seller_name from Seller
where seller_id not in(
select seller_id
from Orders
group by seller_id
having sum(substr(sale_date,1,4)='2020')>0)
order by seller_name3. 两人之间的通话次数

select
if(from_id<to_id,from_id,to_id) person1
,if(from_id>to_id,from_id,to_id) person2
,count(*) as call_count
,sum(duration) as total_duration
from Calls
group by if(from_id<to_id,from_id,to_id),if(from_id>to_id,from_id,to_id)- 注意IF的判断条件使用方法
4. 可以放心投资的国家


select c2.name as country
from Calls c1,Person p,Country c2
where (p.id=c1.caller_id or p.id=c1.callee_id)
and c2.country_code=left(p.phone_number,3)
group by c2.name
having avg(duration)>(select avg(duration) from Calls)- 注意三表链接的用法(其中,and 的优先级高于or,所以or条件要括起来)
5. 树节点

select
id,
case
when p_id is null then 'Root'
when id not in
(select p_id from tree where p_id is not null) then 'Leaf'
else 'Inner'
end as type
from tree- 注意:不能直接when id not in (select p_id from tree) ,要查询的list里有null,但是not in判断的原理是=对比,但是null不能和任何 =, <, or <> 进行对比,只要对比,返回的都是false(not in中包含有null时,结果集一直为Empty set)
6. 游戏玩法分析 III
# 窗口函数sum()over()
select player_id,event_date
,sum(games_played) over(partition by player_id order by player_id,event_date rows between unbounded preceding and current row) games_played_so_far
from Activity
group by player_id,event_date
#把符合条件的匹上去进行sum
select a1.player_id,a1.event_date,sum(a2.games_played) games_played_so_far
from
activity a1,activity a2
where
a1.player_id=a2.player_id
and
a1.event_date>=a2.event_date
#把比a1日期小的所有值匹上去,然后进行sum()
group by a1.player_id,a1.event_date
order by player_id,event_date7. 应该被禁止的 Leetflex 账户
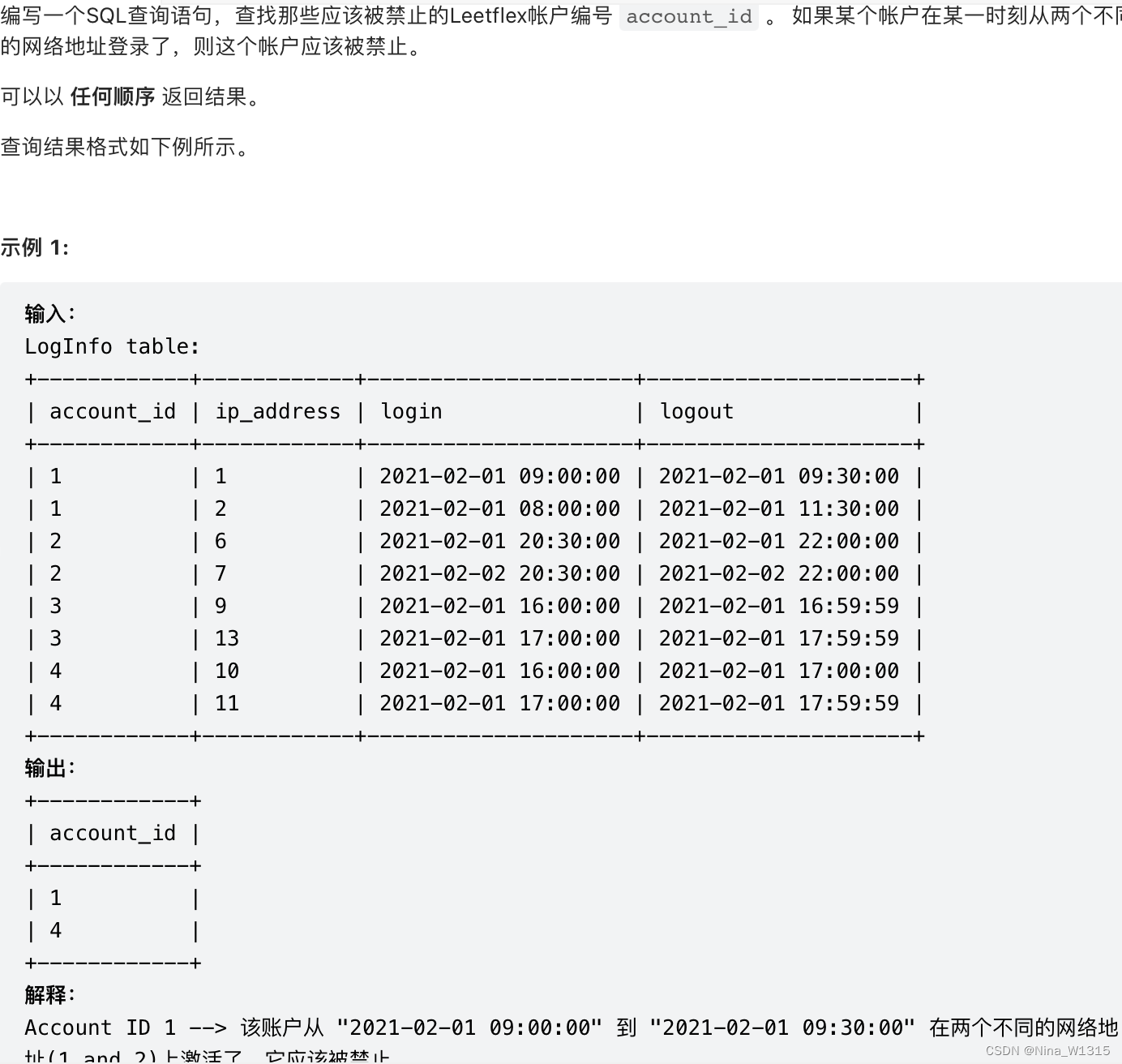
#账户相同,地址不同,时间重叠
select distinct a.account_id
from LogInfo a
inner join LogInfo b
on a.account_id = b.account_id
and a.ip_address != b.ip_address
#把符合条件的匹上去(账户相同,且地址不同)
and a.login between b.login and b.logout
#时间重叠即一个的登陆时间在另一个在线时间之内- 注意:可以匹配的时候把符合条件的匹配上去,然后对能匹配上去的进行后续操作
8. 每天的最大交易
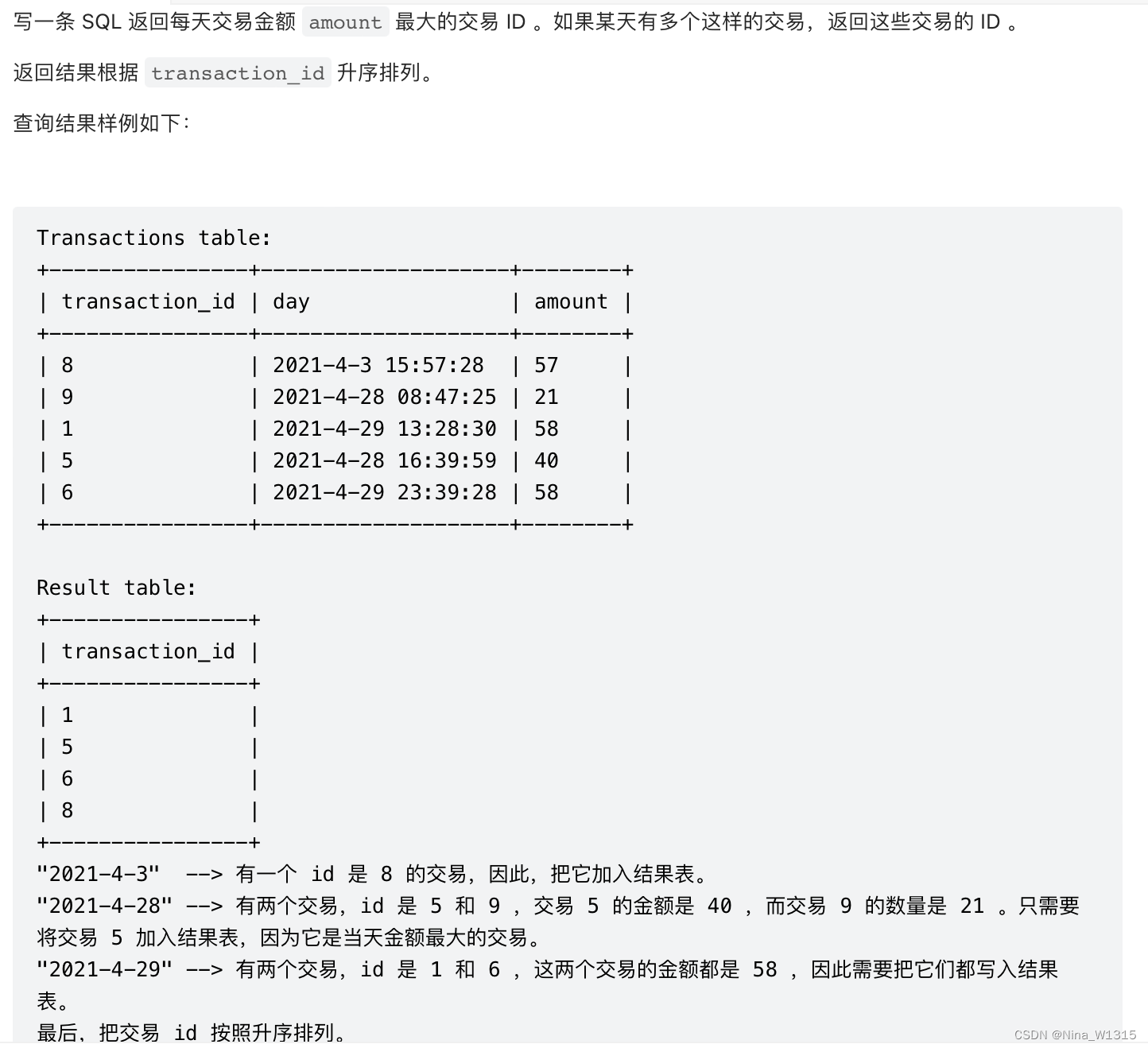
select transaction_id
from
(select transaction_id
,dense_rank() over(partition by concat(year(day),month(day),day(day)) order by amount desc)rk
from transactions
)t
where rk=1
order by transaction_id- 注意,日期提取更好方式还是:date(colunmn), 结果即为"2021-04-19"
9. 找到连续区间的开始和结束数字

select min(log_id) as start_id,max(log_id) as end_id
from
(select log_id
,rank() over(order by log_id asc) as rk
from logs)a
group by (log_id-rk)
#被分到同一组的说明是连续的(因为和rank的增长速度相同)- 注意这个分析思路,如何找到连续?另外给个序号,和序号差值相同的组为连续组
10. 每位顾客最经常订购的商品

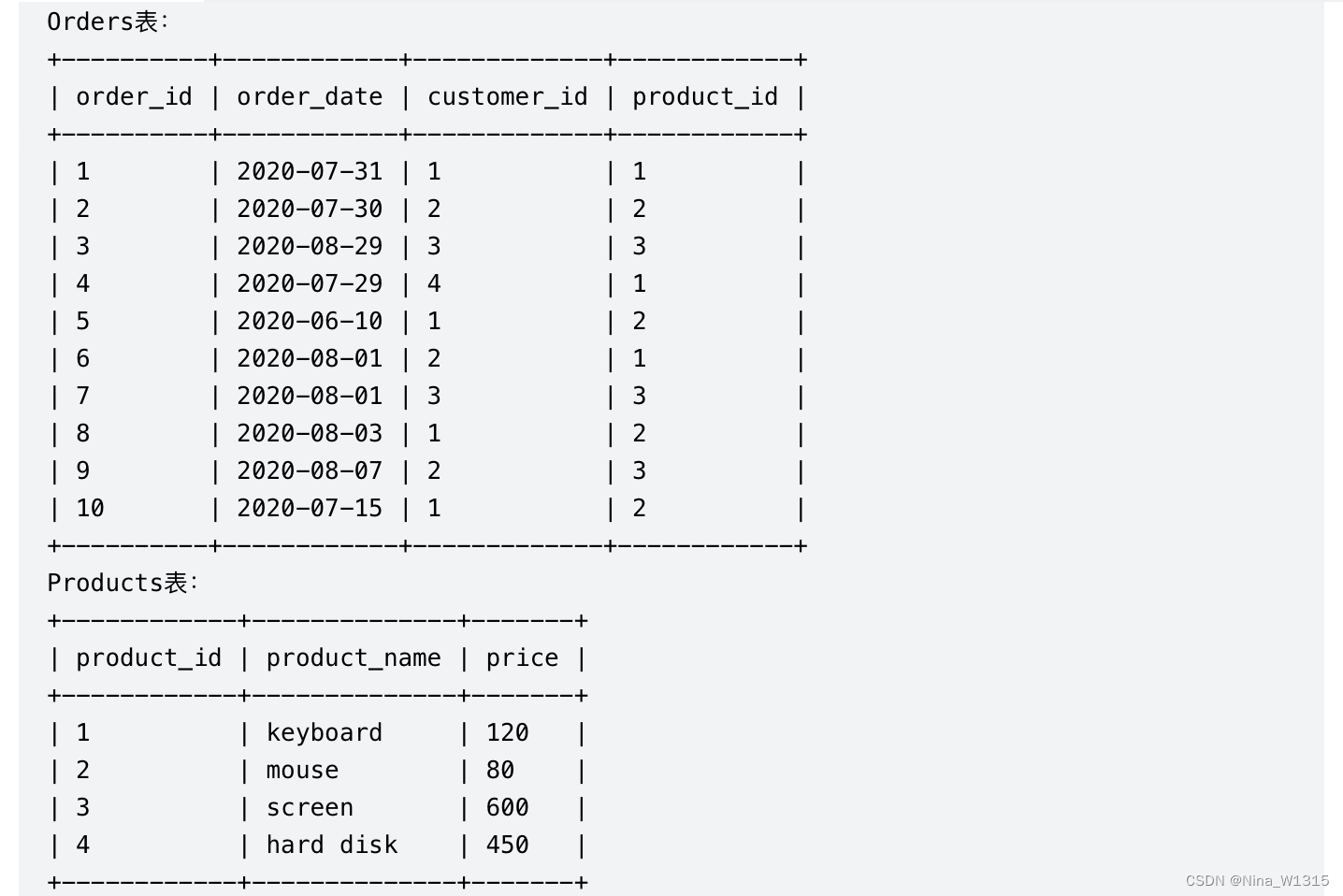
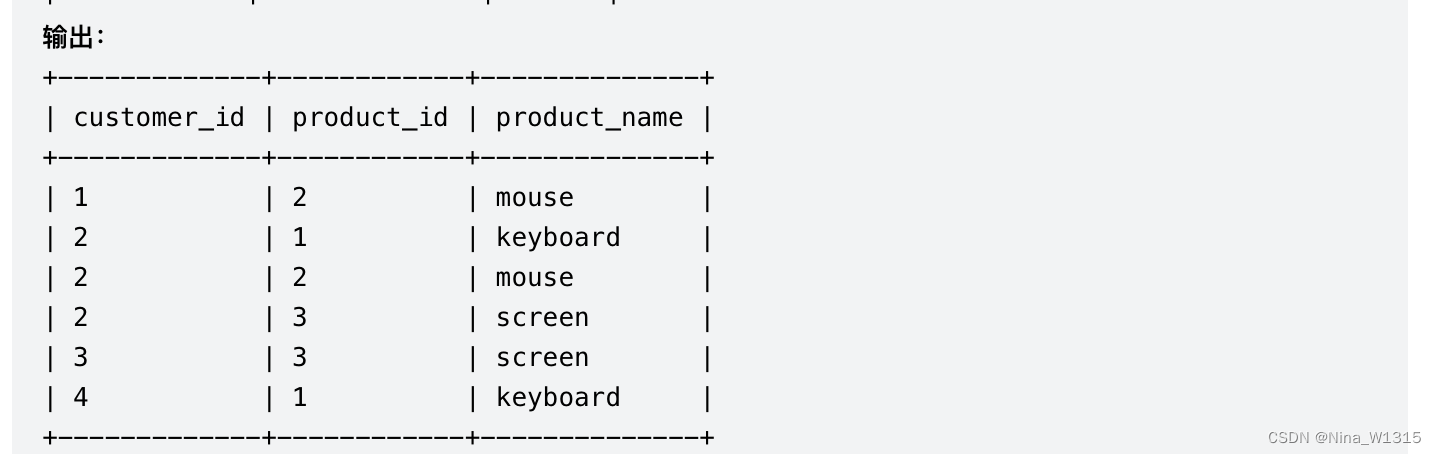
select t.customer_id,t.product_id,p.product_name
from
(select customer_id,product_id
,rank() over(partition by customer_id order by count(product_id) desc) rk
from orders
group by customer_id,product_id)t
inner join products p
on p.product_id=t.product_id
where rk=1- 注意:分组与窗口函数排序的问题,如果窗口函数语句里order by 后有聚合函数,则需要先在底下定义group by的需要聚合的组
11. 访问日期之间最大的空档期
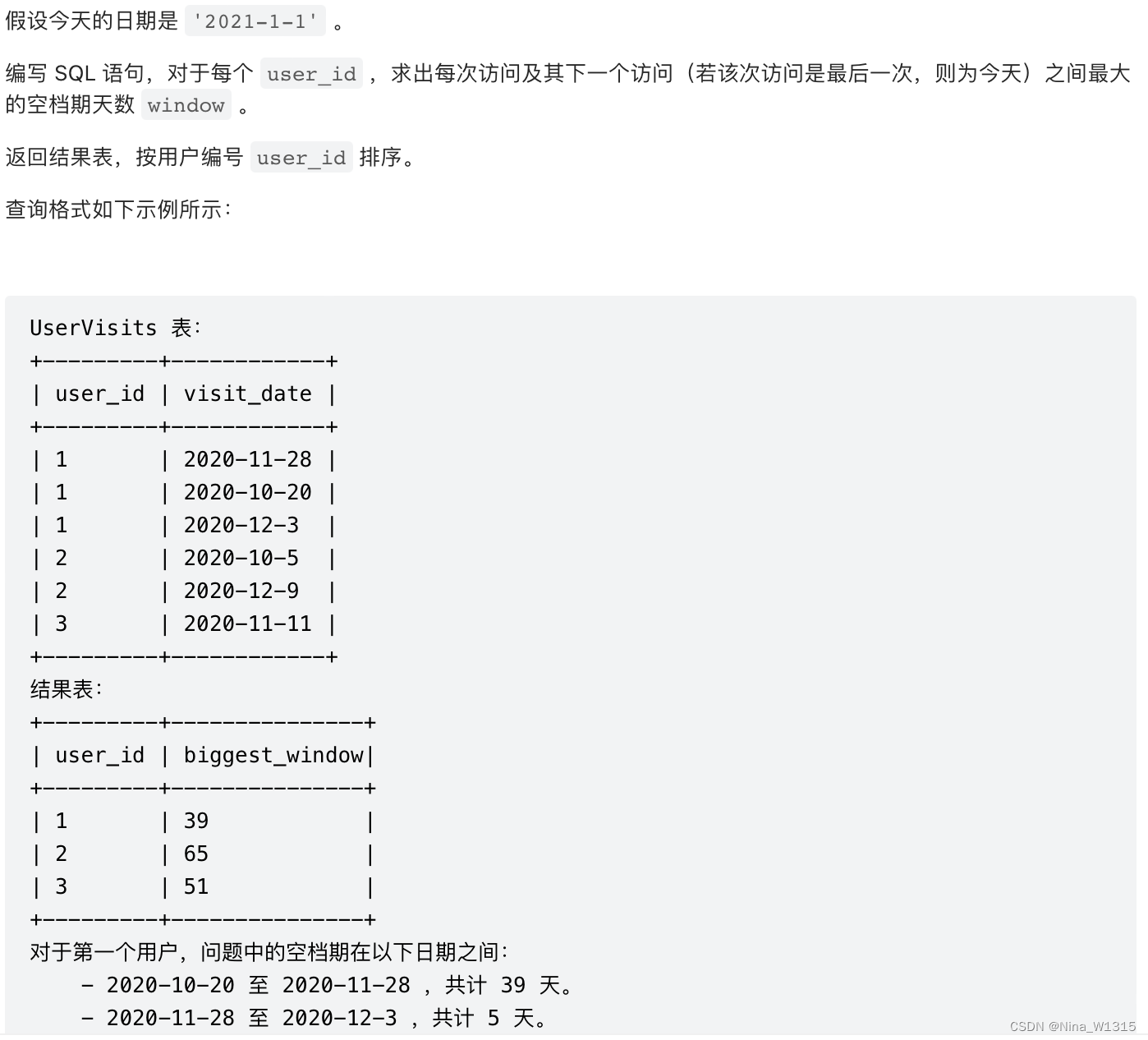
select user_id, max(windows) as biggest_window
from
(select user_id,
datediff(lead(visit_date, 1, "2021-01-01") over (partition by user_id order by visit_date asc), visit_date) as windows
from UserVisits) as temp
group by user_id;- 注意lead(visit_date,1,'2021-01-01')的用法,表示在以
user_id分组并按visit_date升序排序的结果集中,获取每行的下一行的visit_date值。如果当前行没有下一行(即当前行是最后一行),则使用默认值 "2021-01-01" - 注意datediff获取最大时间差的用法,可以直接嵌在窗口函数外
12. 向公司CEO汇报工作的所有人
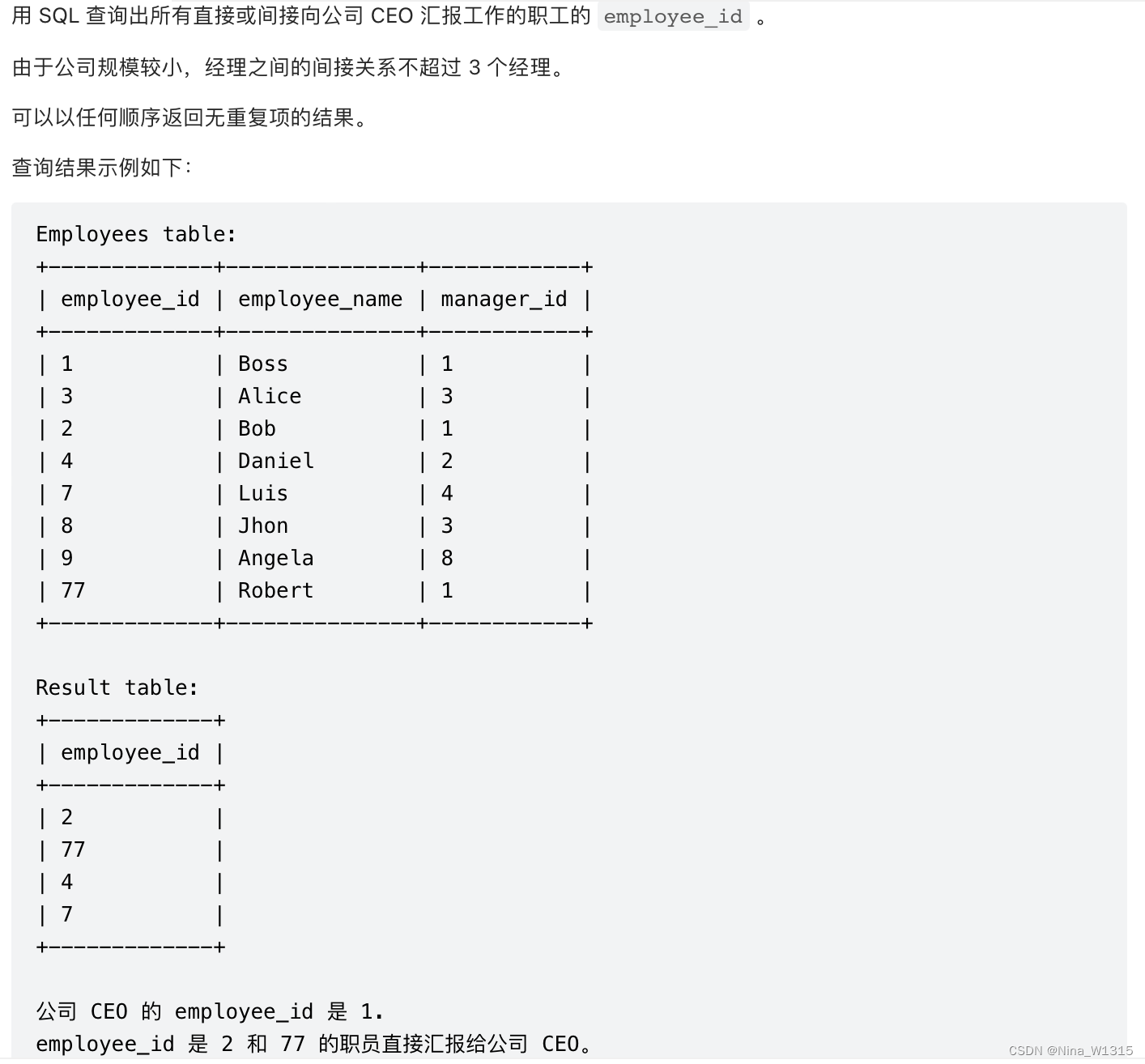
select distinct e1.employee_id
from Employees e1,Employees e2, Employees e3
where e1.manager_id=e2.employee_id and e2.manager_id=e3.employee_id
and e3.manager_id=1 and e1.employee_id !=1- 注意三表联立取关联线路的方法
13. 报告系统状态的连续日期

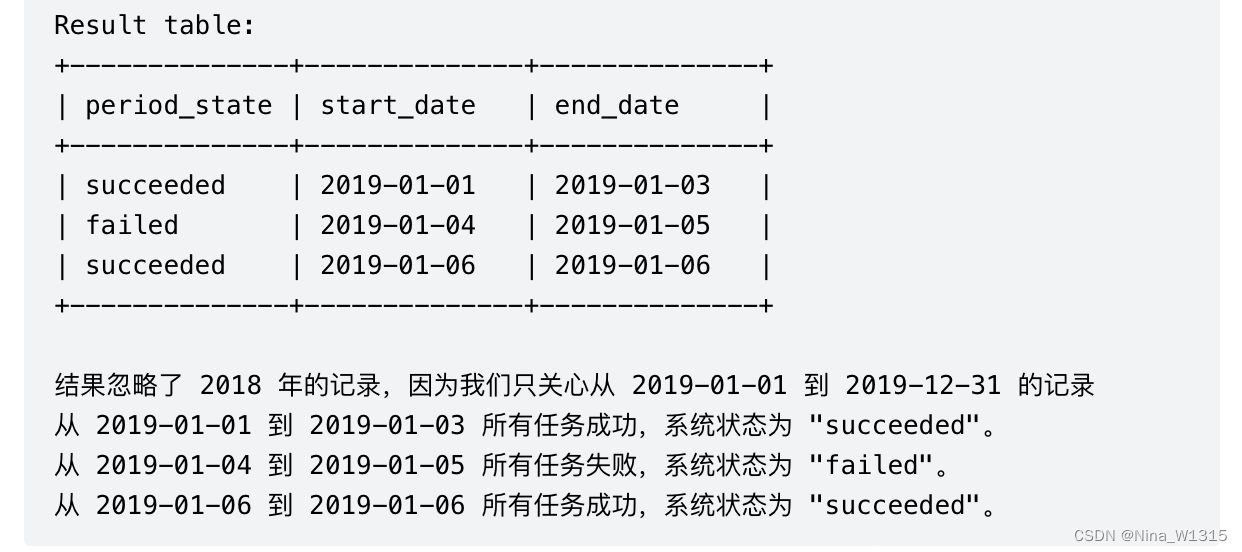
select state as period_state, min(date) as start_date,max(date) as end_date
from(
select
*
,row_number() over(partition by state order by date asc) rk1 #组内排序
,row_number() over(order by date asc) rk2 #编号
from
(select fail_date as date,'failed' as state from failed
union all
select success_date as date,'succeeded' as state from succeeded)t1
)t2
where date >="2019-01-01"
and date <= "2019-12-31"
group by state,rk2-rk1
#t2运行结果:
["date", "state", "rk1", "rk2"],
# ["2018-12-28", "failed", 1, 1],
# ["2018-12-29", "failed", 2, 2],
# ["2018-12-30", "succeeded", 1, 3],
# ["2018-12-31", "succeeded", 2, 4],
["2019-01-01", "succeeded", 3, 5],
["2019-01-02", "succeeded", 4, 6],
["2019-01-03", "succeeded", 5, 7],
["2019-01-04", "failed", 3, 8],
["2019-01-05", "failed", 4, 9],
["2019-01-06", "succeeded", 6, 10]]}- 注意重新构表的方法t1:select failed_date as date, "failed" as state from frailed
- 按照所有时间顺序给个编号rk2(代表连续),再给个state组内排序
- 按照相同state和相同rk2-rk1(连续)来分组(统一状态且连续),找到组内最大和最小值















 3766
3766











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









