






1. 介绍
在所有已研究的生物特征中,虹膜特征在受限场景下获得的大型数据库中表现出非常低的错误匹配率[5,6]。
生物识别系统使用单一的生物特征,带有噪声信号、特征的可变性和欺骗攻击,导致不可接受的错误率,并且缺乏通用性。
关于信息源,多生物识别系统可分为五类:多传感器、多算法、多样本、多实例和多模型[9,10]。
从多实例系统获得的信息的融合可以在不同的级别上完成:传感器、特征、匹配分数和决策级别。从多个来源提取的特征的早期融合比与匹配者或匹配分数的晚期融合相比包含更具区别性的信息,并且已经被观察到提供了更好的识别率[7]。
生物盐化和不可逆变换是CBS的两个子类。不可逆变换比生物特征加盐更安全,因为即使密钥被泄露,也很难恢复原始生物特征模板。
2. 相关工作
2.1 Cancellable unibiometric schemes
2.2 Cancellable multibiometric schemes
3 The proposed methodology
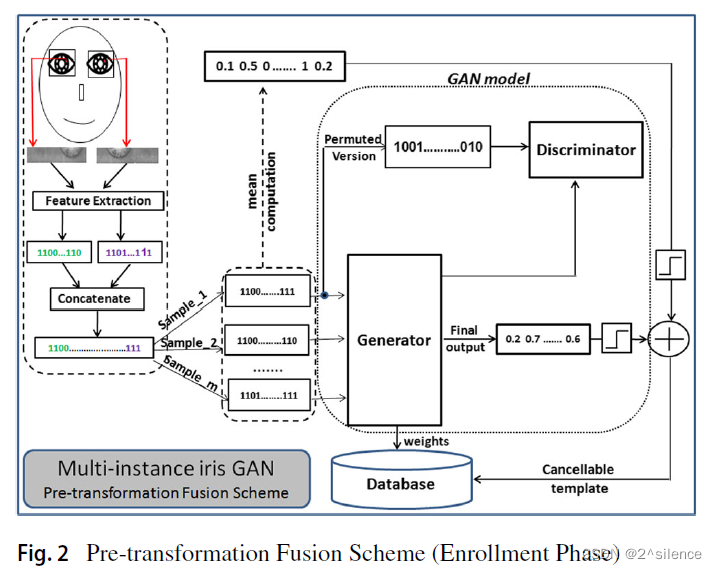
这两种方案的变换阶段都基于标准的GAN模型,该模型是一种无密钥的生物特征盐化方案。
在所提出的方案中,真实数据由生物测定数据的置换版本来表示,而随机数据由训练生物测定样本集来表示。
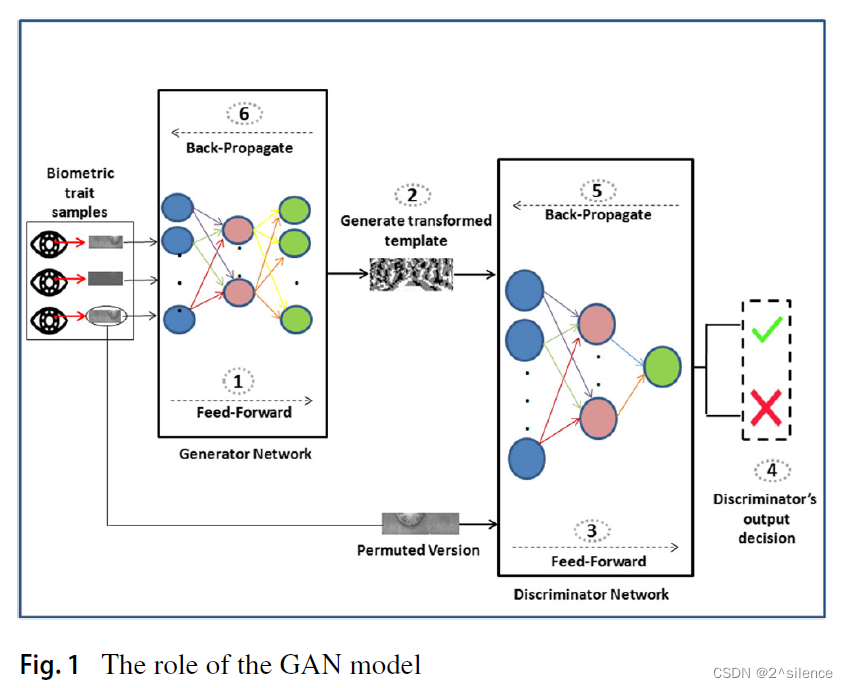
如图1所示,生成器网络为输入的生物特征样本创建候选转换模板,而鉴别器网络对它们进行评估。鉴别器网络的目的是区分输入生物测定样本和置换后的生物测定数据,而生成器网络的目的是创建接近置换后的生物测定数据的变换模板。基于鉴别器网络的决策,通过反向传播阶段更新竞争对手网络的权重。
所提方案的性能仅依赖于生物特征数据,而不依赖于变换密钥的值。
3.1 Pre-transformation fusion scheme


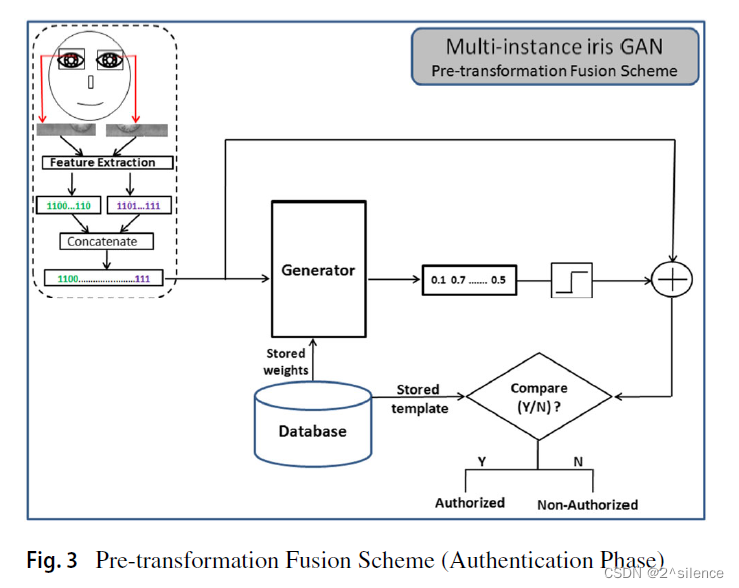
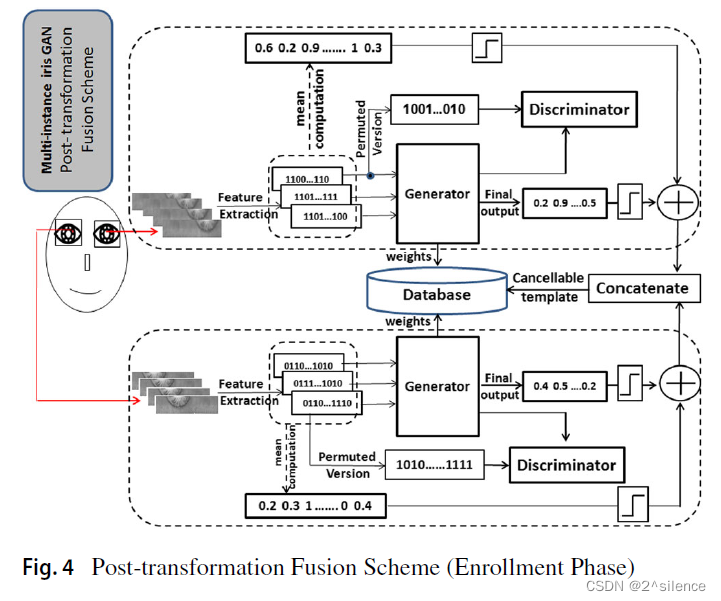
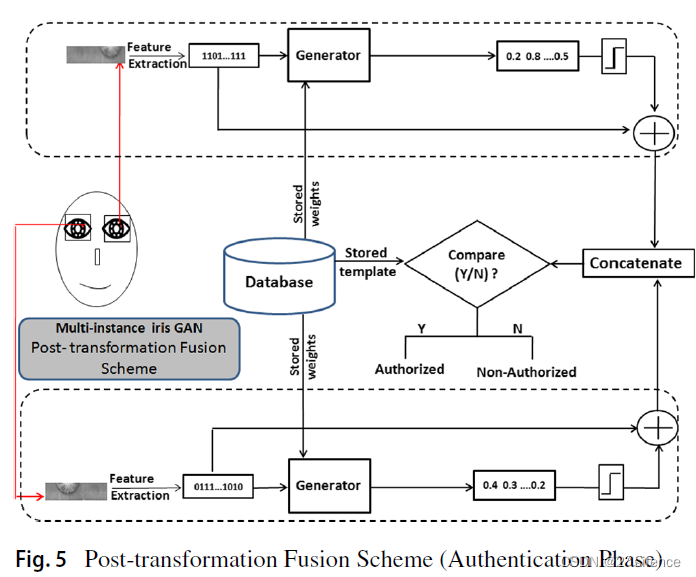
3.2 Post-transformation fusion scheme


4 Security analysis
4.1 Revocability, Diversity, and Unlinkability
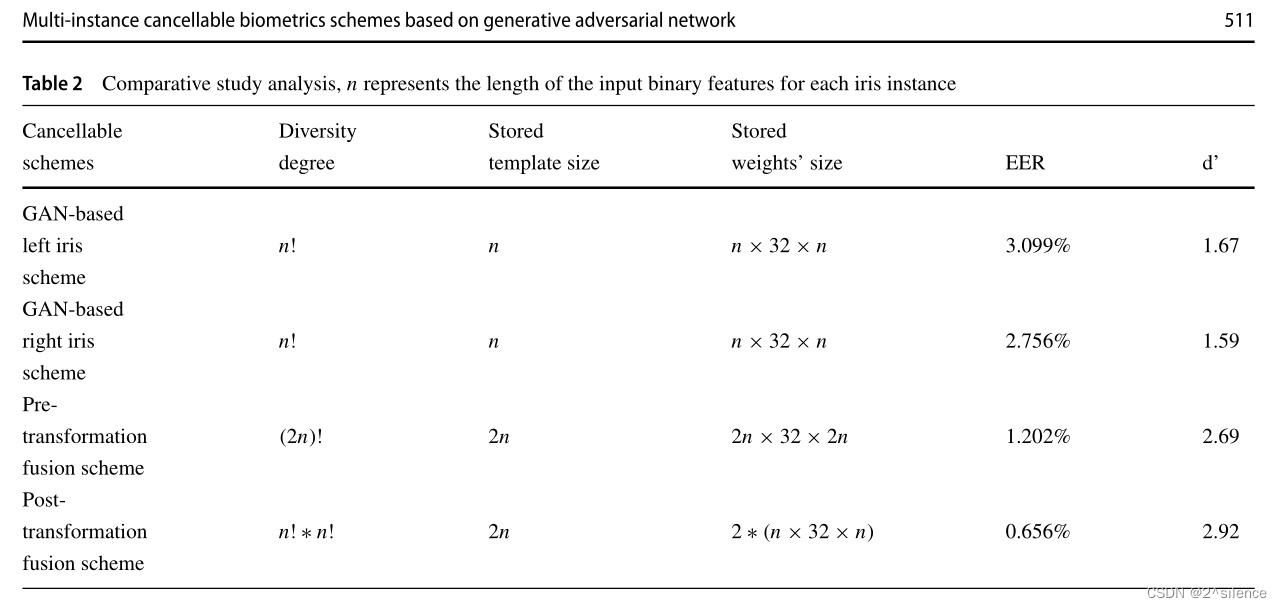
第一个方法是(2n)!,第二个方法是(n!*n!)
4.2 Irreversibility
仅用存储的网络权值恢复神经网络模型的输入或输出在计算上是困难的。XOR不可逆。
4.3 Resistance against different types of attacks
如上所述,对于所提出的两种方案,存储的参数对任何攻击者都是无用的。因此,前像生物特征的数学构造是不可能的。对于第一个提出的方案,攻击者需要等于的最大尝试次数来生成公开的系统生物特征。另一方面,在第二提议的方案中,为每个模型生成这些特征需要等于
的最大尝试次数。
如上所述,所提出的两个方案使得同一个人能够跨各种生物测定系统具有不同的不可链接的可取消模板。通过应用输入特征实例的不同排列并通过随机初始化GAN网络的权重来实现去链接性。
由于攻击者更容易猜测每个独立虹膜实例的输入,而不是猜测冗长的串联虹膜实例,因此第一个方案比第二个方案更能抵抗暴力攻击。
5 Experiments
5.1 Experimental setup
CASIA-V3-Internal iris dataset
每幅图像都被分割、归一化,并用LIBRON MASK码[26]编码成二进制虹膜编码。首先,利用圆形Hough变换和线性Hough变换进行虹膜分割和定位。然后,对虹膜部分进行归一化处理,并利用道格曼的橡皮板模型进行分割。最后,用一维Log-Gabor滤波器对归一化后的虹膜部分进行编码,然后进行量化,得到按位虹膜模板。
对于每个受试者,虹膜模板被重塑成一个二进制虹膜码矢量,该二进制虹膜码矢量被输入到生成器和鉴别器网络。为每个图像提取的虹膜码矢量具有9600比特的大小。产生器网络的输入层和输出层具有相同数量的神经元,而鉴别器网络的输出层包含单个神经元。对于第一种方案,在训练阶段随机选择相同数量的(左和右)虹膜码向量。另一方面,对于第二种方案,分别为左模型和右模型随机选择一组左和右虹膜码向量。所有网络权重都已随机初始化。为了公平比较,两种方案的训练周期数和学习速率值都是固定的。从安全的角度来看,生成的可取消模板应该与输入的生物特征完全不同。因此,训练周期的数量和学习速率被最小化,以限制GaN识别能力,以创建类似于输入生物特征的可取消模板。表1说明了所用的实验参数。
5.2 Performance evaluation
FP表示错误接受的数量,TN表示正确拒绝的数量,FN表示错误拒绝的数量,TP表示正确接收的数量。
FAR和FRR可以通过类间分布和类内分布之间的重叠量来计算。通过比较来自不同类的所生成的虹膜模板来生成类间分布,而通过比较来自相同类的所生成的虹膜模板来生成类内分布。汉明距离HD被定义为大小为N的两个模板之间的不一致比特之和,由公式(14)定义:
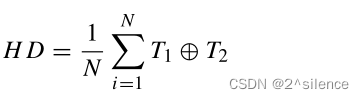
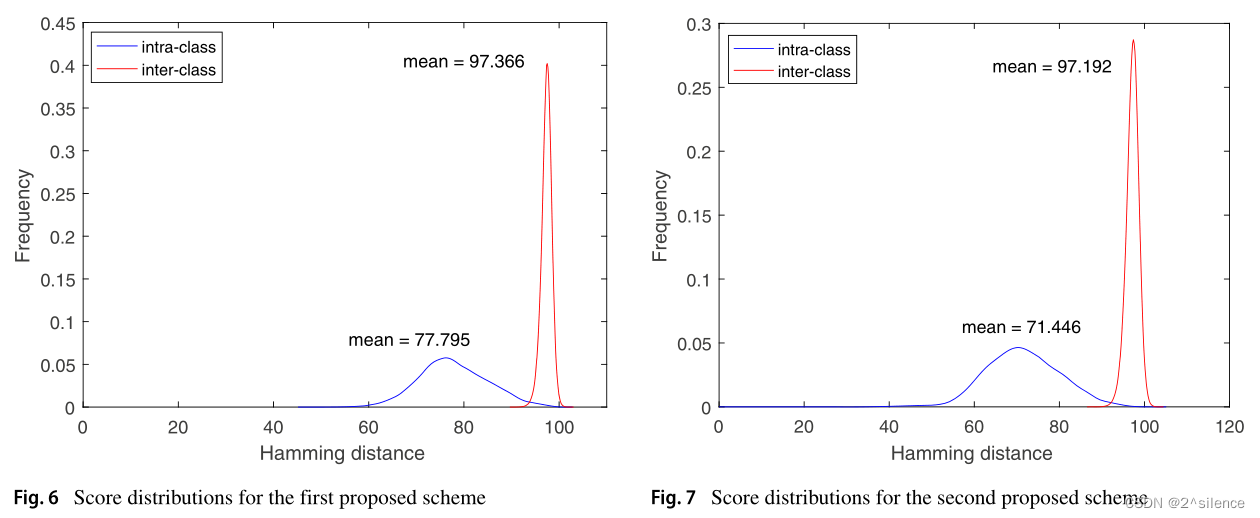
这表明第一个模型中两个分布之间的重叠大于第二个模型中两个分布之间的重叠。分布之间的重叠区域表示模型中关于FAR和FRR的误差比例。
与第一种方案相比,第二种模型在内部分布和内部分布之间有更好的分离。因此,第二个方案的性能比第一个好。
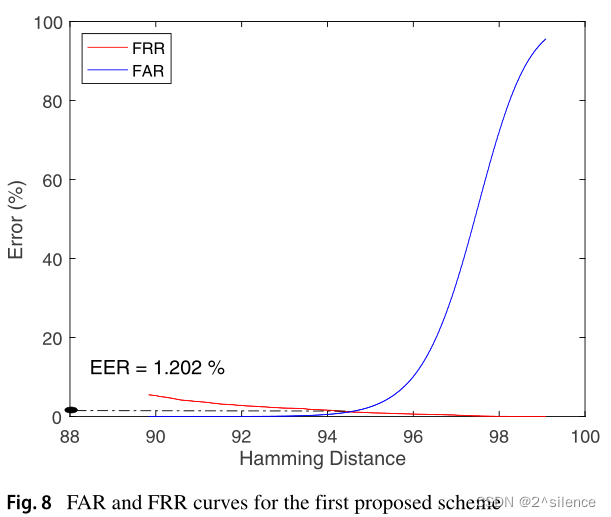
阈值用于如(4)所定义的接受或拒绝测试的虹膜模板:

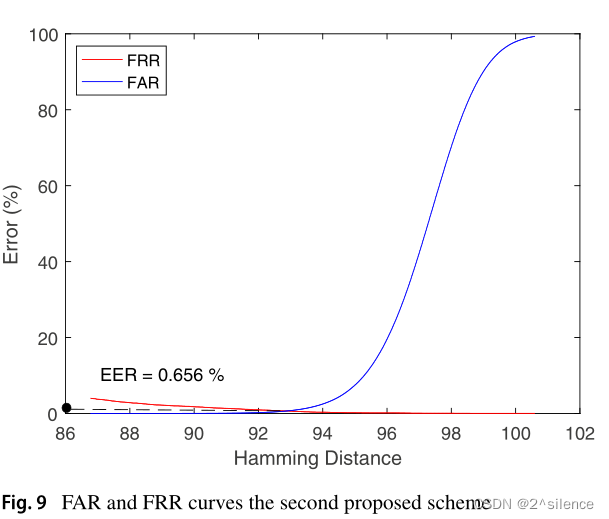
如图所示,阈值(θ)约为93,而相应的EER值约为0.7%。这表明与第一个提出的方案相比,该方案具有良好的识别精度。
通过另一个实验,与依赖于无变换(无保护/原始)虹膜编码的单一生物识别系统相比,研究了所提出的方案的识别准确率。

如图10所示,与单一生物识别方案相比,所提出的方案显示出良好的性能。第一种方案、第二种方案、基于单生物特征的左虹膜方案和基于单生物特征的右虹膜方案的EER值分别为1.26%、0.66%、2.67%和2.25%。
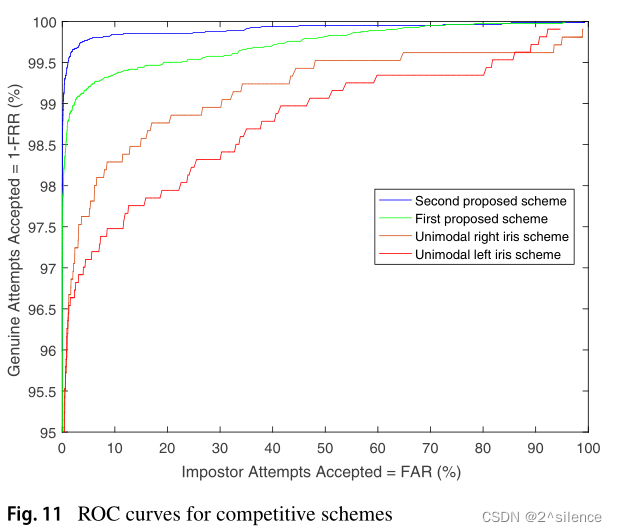
为了进一步分析所提出的方案,将所提方案的识别精度与采用所提出的GAN模型的单生物识别系统的识别精度进行了比较。图11显示了竞争方案的ROC曲线。虽然与第二种方案相比,第一种方案的识别精度略有下降,但这两种方案的性能都优于基于GaN的单生物识别方案。第一种方案、第二种方案、基于GaN的右虹膜方案和基于GaN的左虹膜方案的识别准确率分别为98.8%、99.3%、97.2%和96.9%。
最后,将所提出的方案与基于GaN的生物识别方案进行了比较。
表2根据以下因素总结了比较研究:多样性程度、存储的可取消模板的大小、存储的发电机网络权重的大小以及识别精度(以EER和d‘值衡量)。这里,d‘表示指示真实分布和冒名顶替者分布之间的分离的可判断性度量,其由(5)定义:

其中μi和μg是平均值,和
分别是冒名顶替者(内部)和真实(内部)分布的方差。因此,最大的
值表示更高的识别性能。
可以得出的结论是,与基于GAN的统一生物识别方案相比,所提出的方案更安全,并且产生的可取消模板具有更高的多样性程度。此外,与基于GaN的单一生物识别方案相比,所提出的方案提高了识别准确率。我们还注意到,在产生的可取消模板的多样性程度方面,第一个方案比第二个方案更好。然而,后者获得了比前者更高的识别精度。
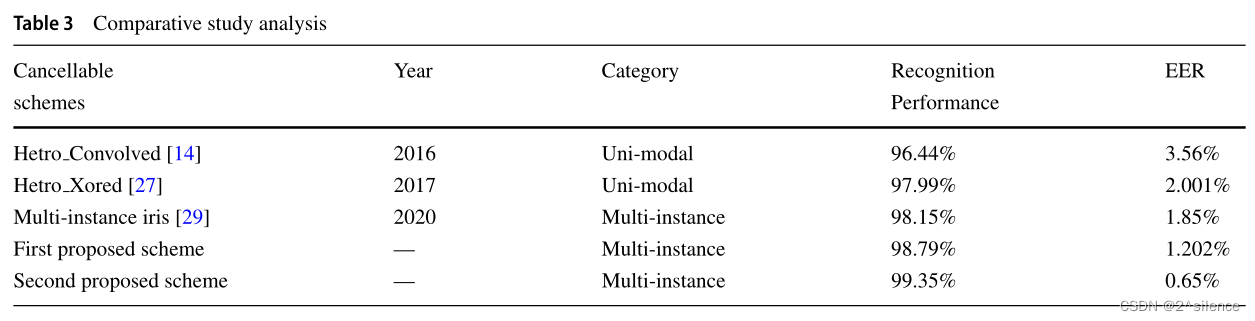
5.3 Comparison analysis

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









