







K-近邻法(K-Nearest Neighbors,KNN)是一种简单的分类和回归方法,它属于有监督的学习算法,亦是一种惰性学习或基于实例的学习算法。它的优点是易于实现,模型简单、直观,并且不需要训练,适用于动态数据;缺点是计算量大,特别是当训练样本量很大时,算法效率较低。
惰性学习:指算法直到输入预测数据后,才开始对训练数据集进行处理的学习方式。与之相反的是急切学习,它在训练阶段就已经构建好了具有泛化能力的模型。惰性学习在训练阶段只进行存储数据,而在预测阶段时,才利用存储数据对新的实例进行分类或回归。
基于实例的学习:与惰性学习相似。算法只有在预测时,才利用一些度量相似度的指标来找到与新实例最相似的训练实例,再基于这些训练实例作出预测。
目录
1.1 欧几里得距离(Euclidean distance)
基本原理
一个样本的类别或数值可以由其最近邻的一个或几个样本的类别或数值来预测。
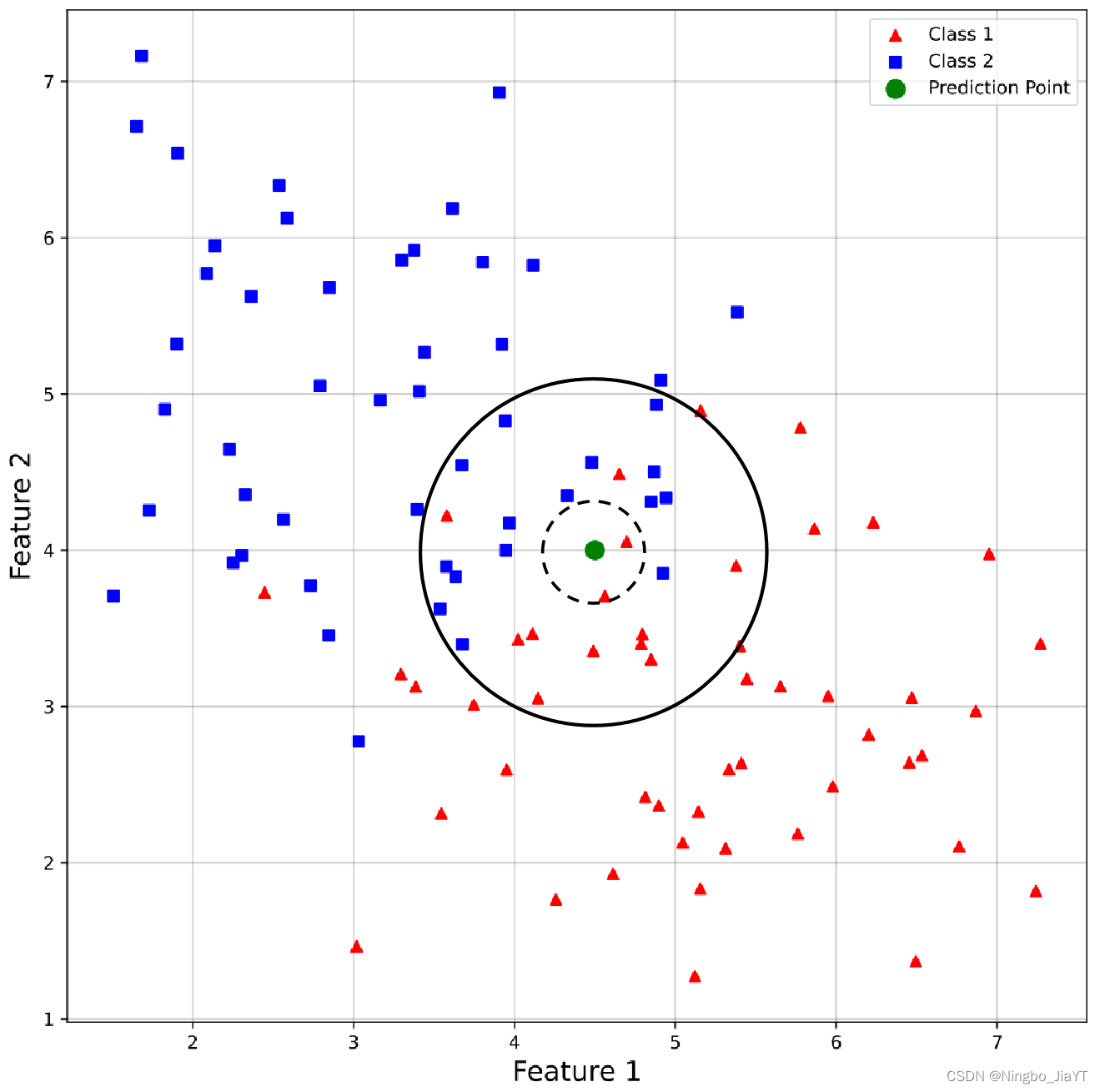
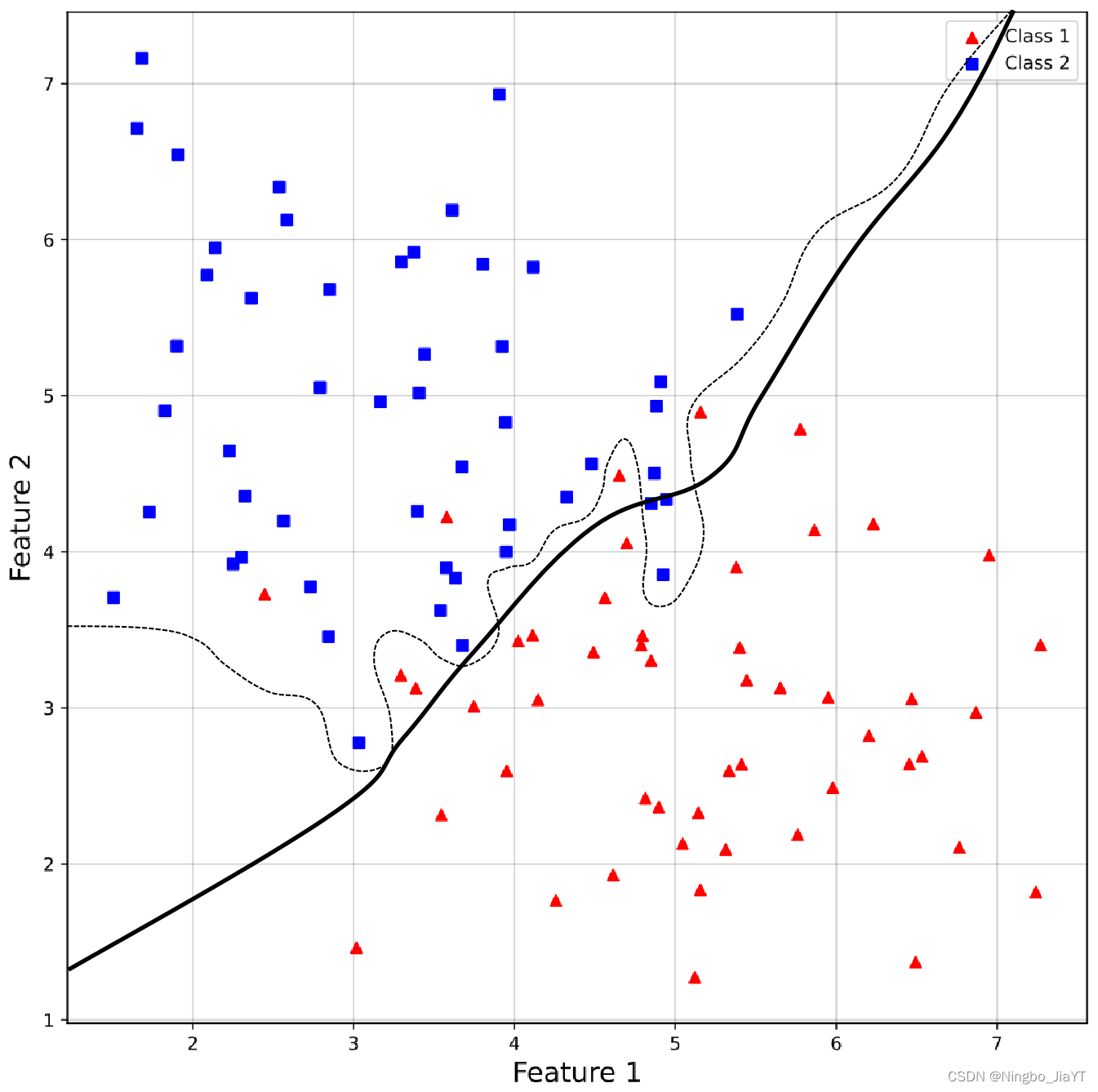
关键要素
1.距离度量
即使用指标度量样本与样本间的相似度。相似度越大,则距离越近。以下是常用的指标:
1.1 欧几里得距离(Euclidean distance)
最常用的距离度量指标之一,用于衡量多维空间中两点之间的直线距离。公式表示如下:
对于已知空间坐标的点 和点
,其欧式距离为:
其中,n表示n维空间,或n个特征。
1.2 汉明距离(Hamming distance)
在信息论中,衡量两个等长字符串的差异,即统计两个字符串对应位置不同字符的个数,或理解为将一个字符串变换成另外一个字符串所需要替换的字符个数。广泛应用于信息通信的错误检测和纠正、基因序列的相似度分析。
2.K值选择
即选择前K个最相似的样本。K值的选择对算法结果有很大影响。K值过小,模型容易过拟合,受噪声影响较大;K值过大,则可能包含太多其他类别的点,导致模型的预测准确率下降。
3.分类决策规则
在分类问题中,多采用投票法;在回归问题中,多取平均值作为预测结果。当遇到类别不平衡问题时,可以给予不同类别样本不同的权重。
工作步骤
1.特征缩放(包括归一化和标准化等);
2.计算待分类点与其他所有点之间的距离;
3.基于距离排序样本;
4.选出距离最近的前K个点;
5.决策。















 7451
7451

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









