






WordCount项目是用来干嘛的? 就是用来统计txt文档里面单词出现的个数
例如:txt文档内容如下

最后运行完WordCount程序之后出来的结果就是
hello 4
aaa 2
bbb 2
ccc 1
WordCount项目需要建三个类 Mapper类 Reducer类 Driver类
WordCountMapper
package nj.zg.kb23.demo1;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WordCountReduce extends Reducer<Text, IntWritable,Text, LongWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {
System.out.println("Reduce stage Key:"+key+"Values:"+values.toString());
int count = 0;
for (IntWritable intWritable :
values) {
count+=intWritable.get();
}
LongWritable longWritable = new LongWritable(count);
System.out.println("ReduceResult key:"+key+"resultValue:"+longWritable.get());
context.write(key,longWritable);
}
}
WordCountReducer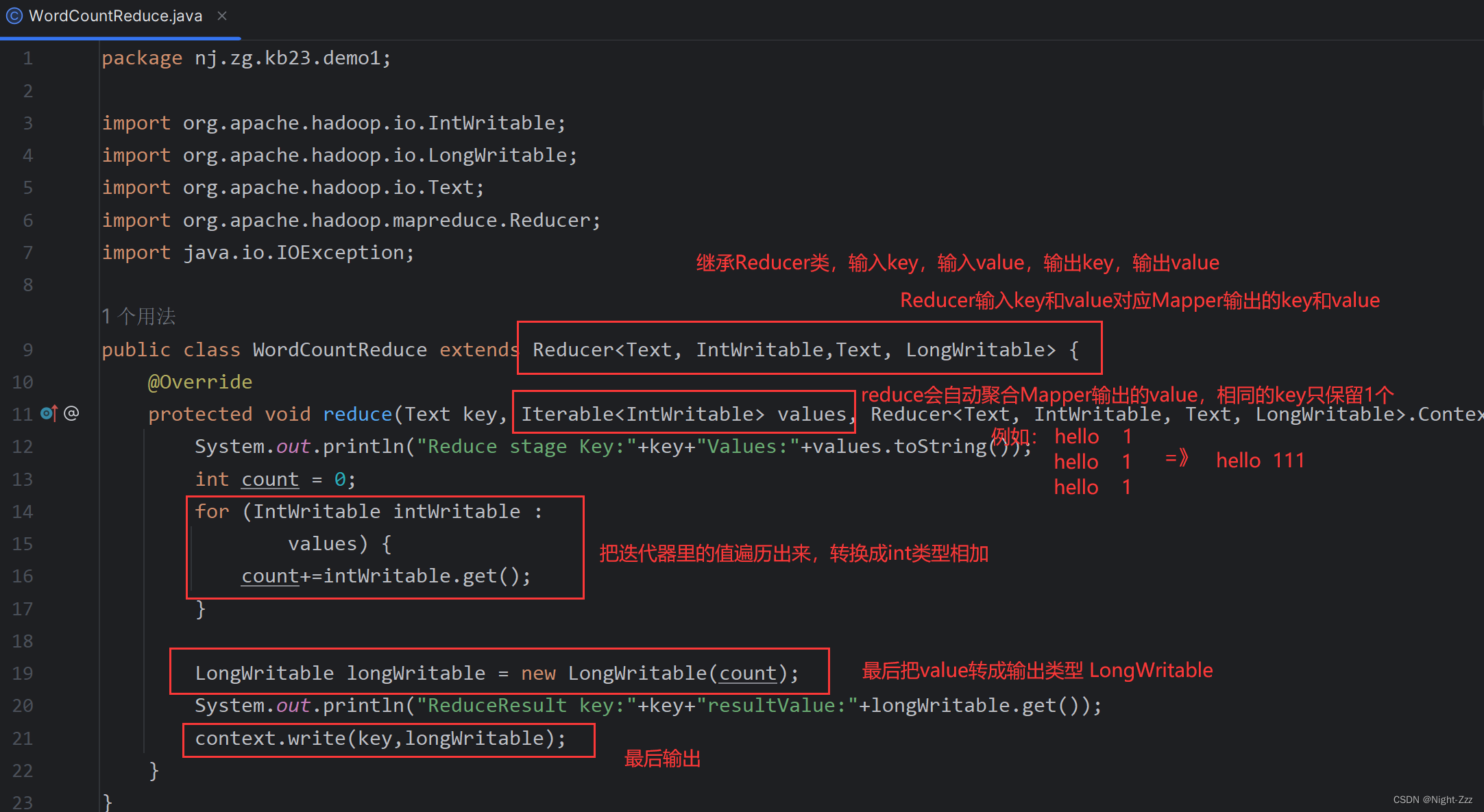
package nj.zg.kb23.demo1;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
//<0,hello java,hello,1>
//<0,hello java,java,1>
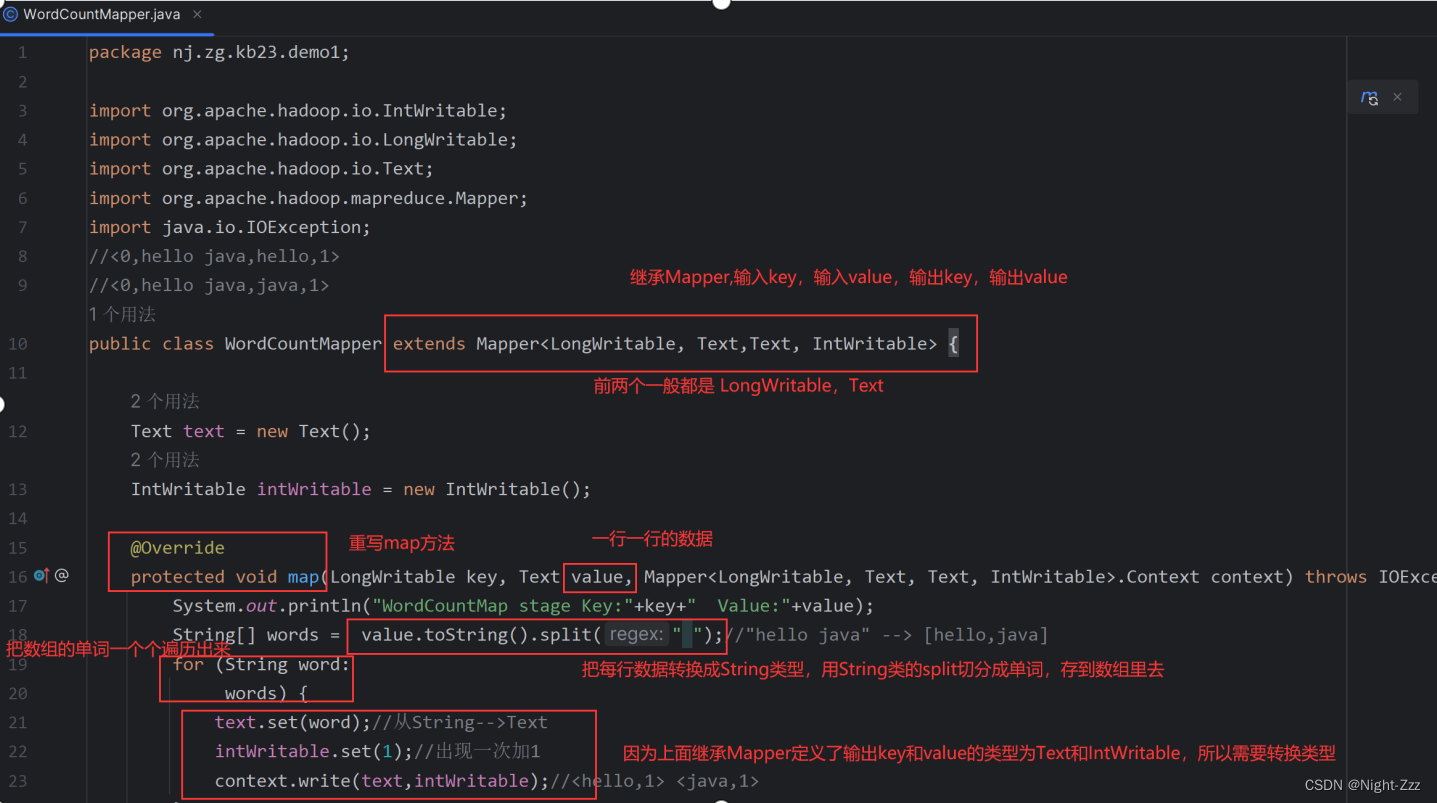
public class WordCountMapper extends Mapper<LongWritable, Text,Text, IntWritable> {
Text text = new Text();
IntWritable intWritable = new IntWritable();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
System.out.println("WordCountMap stage Key:"+key+" Value:"+value);
String[] words = value.toString().split(" ");//"hello java" --> [hello,java]
for (String word:
words) {
text.set(word);//从String-->Text
intWritable.set(1);//出现一次加1
context.write(text,intWritable);//<hello,1> <java,1>
}
}
}
WordCountDriver

package nj.zg.kb23.demo1;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
//获取配置
Configuration conf = new Configuration();
//获取job对象
Job job = Job.getInstance(conf);
//设置job方法的驱动类
job.setJarByClass(WordCountDriver.class);
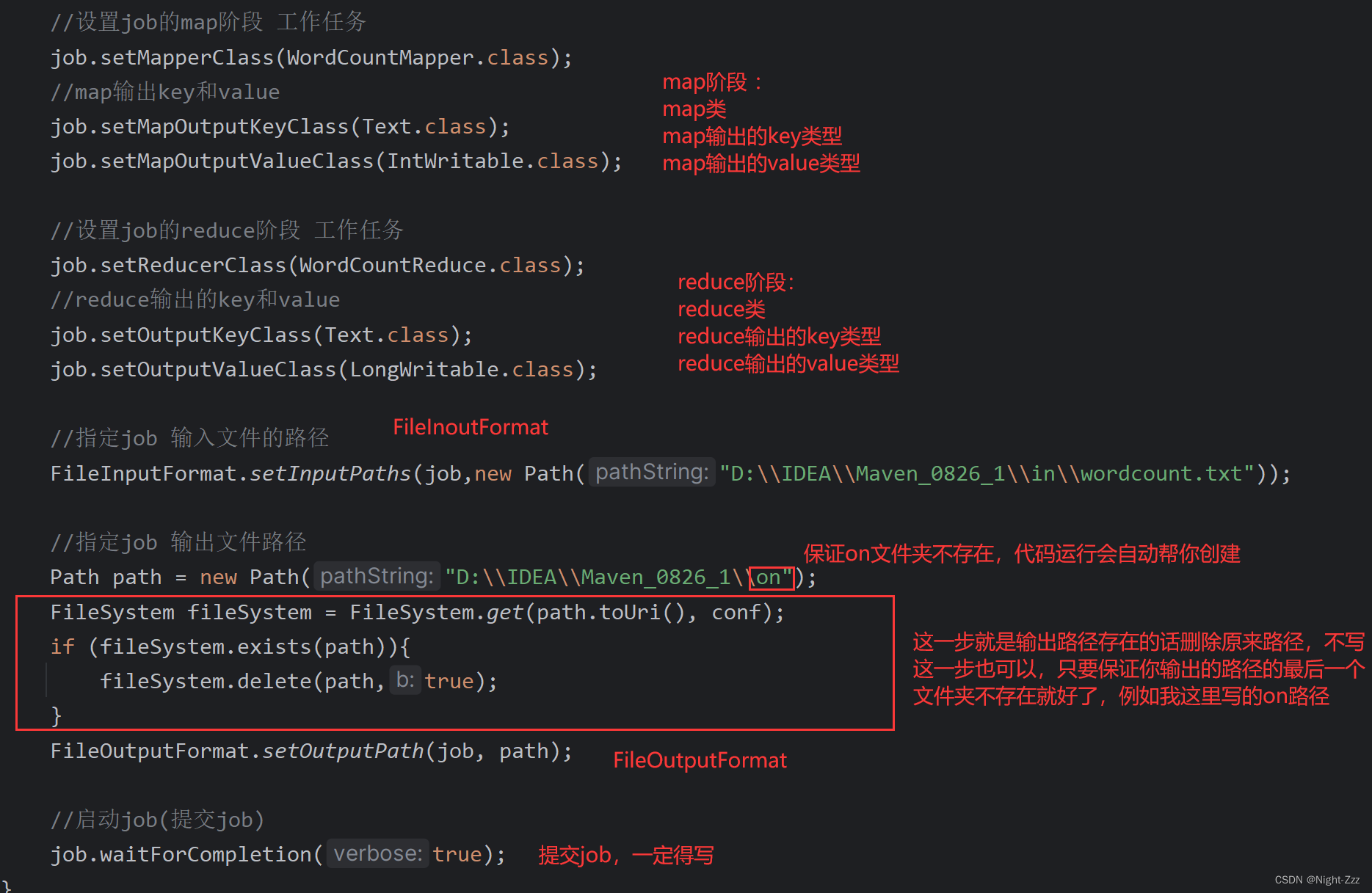
//设置job的map阶段 工作任务
job.setMapperClass(WordCountMapper.class);
//map输出key和value
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//设置job的reduce阶段 工作任务
job.setReducerClass(WordCountReduce.class);
//reduce输出的key和value
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//指定job 输入文件的路径
FileInputFormat.setInputPaths(job,new Path("D:\\IDEA\\Maven_0826_1\\in\\wordcount.txt"));
//指定job 输出文件路径
Path path = new Path("D:\\IDEA\\Maven_0826_1\\on");
FileSystem fileSystem = FileSystem.get(path.toUri(), conf);
if (fileSystem.exists(path)){
fileSystem.delete(path,true);
}
FileOutputFormat.setOutputPath(job, path);
//启动job(提交job)
job.waitForCompletion(true);
}
}
需要注意的是,Driver的输入路径需要指向你需要统计的txt文档,输出路径的最后一级目录不能存在,上面就是on目录不能存在,程序会自动帮你创建,如果运行程序之前就存在,就会报错















 3492
3492











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









