







总览篇第4篇到第10篇主要是围绕着模型来介绍的,具体讲述的是机器学习模型的构建和学习的过程;本文是总览篇的最后一篇文章,介绍特征工程,准确来说特征工程是独立与机器学习存在的一个主题,但却是机器学习应用中不可缺少的一环。特征工程在2006年深度学习大热之前,是与“模型”处于同等地位的内容,随着深度学习的兴起,特征工程一部分工作由深度学习的深度网络完成,使特征工程的地位明显降低,然而特征工程真的就因此不重要了吗?并不是,特征工程在当今时代仍然发挥着重要的作用,甚至可以说是无处不在。
文章首发于我的博客,转载请保留链接 😉
一、特征工程是什么
特征工程是一个过程,一个“利用数据相关领域知识来创造让机器学习算法能运作的特征”的过程。特征工程虽然是一个非正式的主题,通常情况下也并没有被列入到机器学习必要的元素中,但在机器学习实际应用中确实是不可缺少的元素。从这个角度看,有点类似于“空气之于人”,平时不重视,但十分重要,并且无处不在。
首先,特征是什么?特征是做分析或预测的所有独立样本共享的一种属性,所有对模型有影响的属性都能成为特征,除了属性意义之外,特征的目的是让模型更容易挖掘问题的语义,从而帮助模型解决问题。
然后,特征工程就是一大箩筐围绕着特征要做的事情的集合,以服务于后面模型的学习。特征工程与机器学习关系的示意图如图1所示,
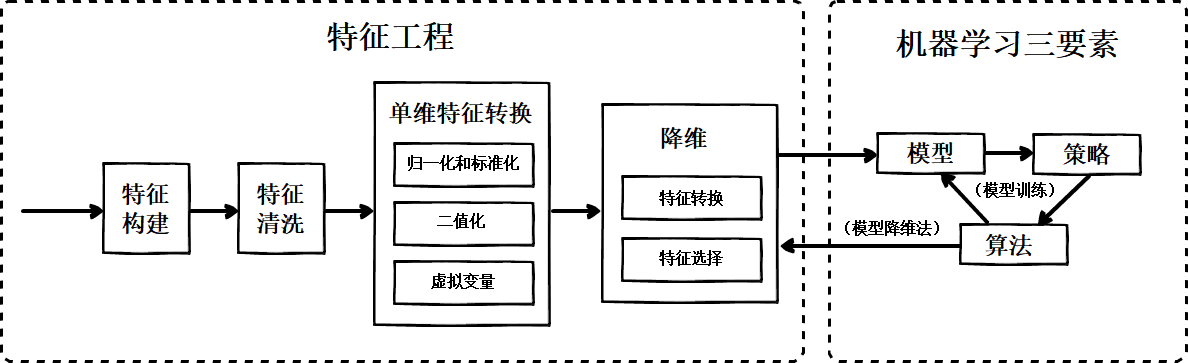
从图1可以看到,特征工程与机器学习有交叉的地方,但更多是扮演着独立的预处理过程的角色。特征工程的大致流程包括:
- 特征构建
- 特征清洗
- 检查特征如何与模型一起使用
- 特征改进。常见的包括单维特征处理、特征降维。
- 重复1-4步,直到工作完成。
文本重点介绍内容:第二节介绍第1步的特征构建,第三节介绍第2步的特征清洗,第四节介绍第4步中的单维特征处理,第五节介绍第4步中的特征降维。本文内容较多且杂,因为特征工程的工作本身就多且杂。
二、特征构建
通常有这么一种认知,认为机器学习会彻底占领人类专家擅长的领域,其实并不然,至少现阶段是错误的。特征构建作为机器学习流程的第一步(如图2所示),也是很重要的一步,是十分依赖专家知识的。
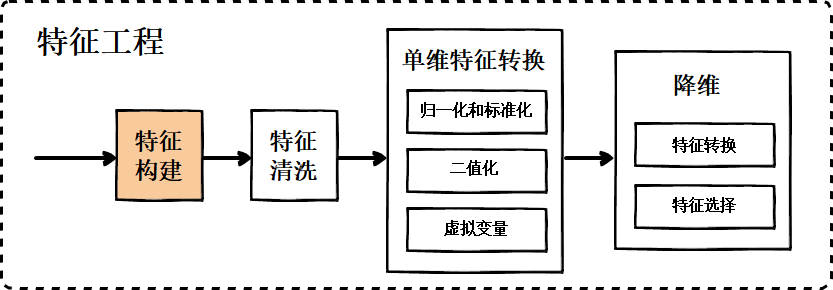
特征构建是指从原始数据中人工的找出一些对模型学习有用的具有物理意义的特征。 需要花时间去观察原始数据,思考问题的潜在影响因素。为了构建特征,我们应该需要做到以下两点:
- 培养对领域的认知、数据的敏感性、机器学习实战经验,这些能有效地帮助我们进行特征构建,但都需要一定的积累和沉淀。
- 除此之外,特征构建还有一些即时可以使用的技巧,数据的分割和结合:分割是指将某一种数据细化成多种数据,提供更多的信息,提高模型准确率;而结合是相反的过程,将冗余表达的信息合并在一起,提高模型收敛效率,典型有对于逻辑回归等广义线性模型,组合特征方法是一个十分常用并且有效的特征构建方法,比如将 特征A [1, 0, 1]与 特征B [0, 1] 组合,通过特征向量的叉乘构成新的 组合特征C [0, 0, 0, 1, 0, 1]。
为了方便理解,以下给出两个关于属性分割和结合的实际例子,
【场景1-属性分割】根据大学生前两个学期的表现来预测他是否能在大学毕业时获得优秀毕业生的称号。【分析】直观的当然应该将学习成绩作为一个特征属性,但进一步进行考虑,通常专业必修课课成绩对评选影响更大,而非专业选修课影响会比较小,学习成绩又是本任务一个十分重要的影响因素,所以分开更合理,那么这种情况就是按学科将学习成绩属性分割。
【场景2-属性结合】预测大学生毕业后的薪资水平【分析】对于该任务,影响因素大概有学校、专业、学习成绩、获奖情况、课程项目经历、公司实习经历等,在这种情况下影响因素本身就较多,而且都相对比较重要。我们已有的数据包含了学生各科的成绩,如果直接拿来作为特征,根据《总览篇 VII 三要素之策略-正则化》可知,特征过多可能会导致过拟合;而过多太细化的特征实际影响并不大。所以,跟属性分割相反,将所有成绩做平均,或者最多将部分课程成绩结合分成专业课成绩和非专业课成绩是更合适的做法。
可以看到,特征的构建是一个精准权衡的过程,需要做到信息 “不冗余的完整”,是个非常麻烦的问题,书里面也很少提到具体的方法,需要对问题有比较深入的理解。
三、特征清洗
也叫数据清洗,它是特征工程的第二步:它是发现并纠正数据文件中可识别的错误的最后一道程序,包括检查数据一致性,处理无效值和缺失值等;为了解决数据不平衡带来的学习无效的问题,还需要做到数据相对均衡。
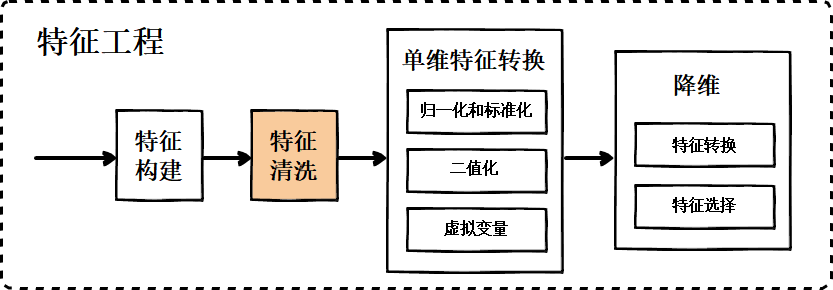
4.1 无效值和缺失值的处理
由于一些因素,数据中可能存在一些无效值和缺失值,需要给予适当的处理。常用的处理方法包括:
1. 估算(Estimation)。 使用缺失数值所在行或列的均值、中位数、众数、最值等来替代缺失值。或者根据样本其它有相关性的数据来估算缺失数据。
2. 样本删除(Casewise Deletion)。 当受到影响的样本占总样本比例较低,或者受影响的特征维度十分重要时,将有问题的样本删除是一种对学习效果影响较小的做
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 158
158











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









