







单链表必须从头结点出发才能访问全部节点。
为了解决这个问题,将单链表中的终结点的指针从NULL改为指向头结点,这就形成了一个环,头尾相接的单链表叫单循环链表,简称循环链表。
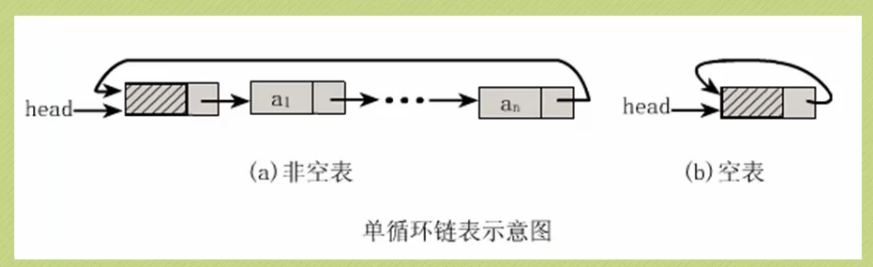
注意:循环链表与单链表的主要差异在空链表的判断上:
| 种类 | 空链表 | 非空链表 |
| 循环链表 | head->next == head | head->next != head |
| 单链表 | head->next == null | head->next != null |
终结点使用尾指针rear指示,则开始结点(元素的第一个)为rear->next->next,首末结点查找都是O(1)。
注意以下几点:
1)循环链表是一个“环”,每个结点都是概念上都是对等的,这里没有单链表中那个空的头结点,唯一不同的是链表名也就是头指针指向谁谁就是第一个结点。当改变第一个结点时,不要忘了改变头指针(代码34行)。
2)区分node pNode,node *pNode,node **pNode。第一个pNode是一个结点,从栈中申请的结点,如果在子函数中,函数结束返回后会被释放,不可以把它加到链表中。第二个*pNode是一个结点的指针,也就是链表(可以考虑为结点的数组名),如果next为null也可以认为是从堆中申请的一个结点(包含一个结点的链表)。第三个**pNode是一个链表的指针,如果想在函数之间传递参数并且修改这个链表(如插入删除),要传这个链表指针。如果传递参数但是不希望修改(如遍历或者计算长度),可以传第二个。
详细代码如下:
#include<iostream>
using namespace std;
///**************循环链表**********************/
typedef struct CLinkList
{
int data;
struct CLinkList *next;
}node;
//插入结点
//参数:链表的指针,插入的位置
void CList_inser 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1088
1088

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









