






写在最前面,本人是一个超级小白(python没有什么基础,深度学习浅浅了解了一下CNN,RNN和基础的神经网络,没有学过机器学习),这个题目我研究了近两周(可能是我太笨了,泪目),今天就以自己这两周的学习经历,详解一下这个题目,相信和我一样的小白要是看了这篇文章应该会有所收获。(其实这个是为了明天的组会准备的东西)
1. 基础知识
1.1 RNN神经网络
首先什么是RNN神经网络,这一部分的理解大家可以见这个视频的P1。循环神经网络(RNN)
其实这里的解释不够直观,下面这个视频通过3D的角度更加直观的解释了什么是RNN。(真的强推,这个看了之后会有不一样的收获)【循环神经网络】5分钟搞懂RNN,3D动画深入浅出
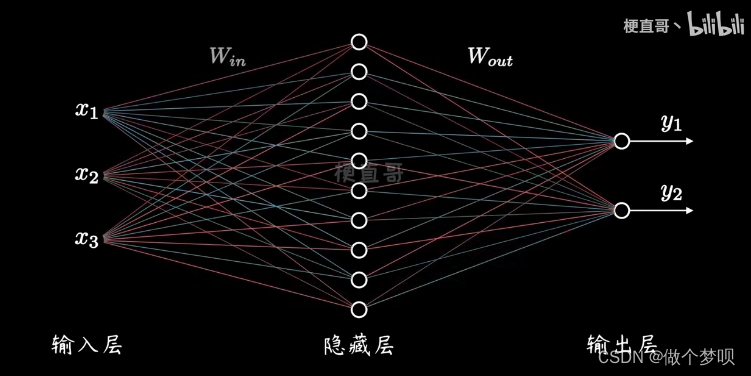
图1 普通的神经网络结构

图2 RNN的网络结构
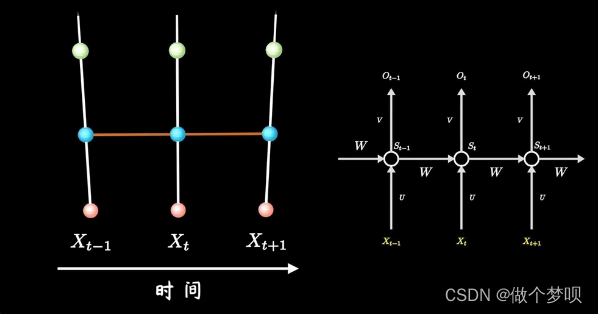
图3 将3D视角图与平时论文中常见的RNN结构相连接
以上三张图片均来自B站梗直哥丶的视频。
1.2 MNIST数据集
MNIST数据集是NIST(National Institute of Standards and Technology,美国国家标准与技术研究所)数据集的一个子集,MNIST 数据集可在 http://yann.lecun.com/exdb/mnist/ 获取。
在该数据集中训练集train一共包含了 60000 张图像和标签,而测试集一共包含了 10000 张图像和标签。每张图片是一个28*28像素点的0 ~ 9的灰质手写数字图片,黑底白字,图像像素值为0 ~ 255,越大该点越白。
关于该数据集的详细介绍可以看这篇文章的介绍。
2. 需要导入的包和参数的定义
本次项目所需要的包,以及超参数的定义如下所示(关于各个超参数的含义,各位看官可以先往下看):
import numpy as np
import torch
import torch.nn as nn
import torchvision
import torchvision.datasets as datasets
import torchvision.transforms as transforms
from torch import device
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
# 1.定义超参数
Epoch = 1 # 训练次数
Batch_Size = 64 # N,设置了每批次装载(读取)的数据图片为64个(自行设置)
Input_Size = 28 # d,图片宽度
Time_Step = 28 # L,图片长度
LR = 0.01 # 学习率3. 数据加载
关于导入MNIST数据集的代码如下,详细的解析可以见第一部分的那篇文章。
之后可以观察导入的MNIST的数据类型,能看出该测试集的格式为[60000,28,28],即60000张图片,每张图片为28×28的像素,标签的类型一共有10种,即[0-9]。
# 2.导入数据集
train_sets = datasets.MNIST(root='./data/', train=True, transform=transforms.ToTensor(), download=True)
test_sets = datasets.MNIST(root='./data/', train=False, transform=transforms.ToTensor(), download=True)
# 3.查看导入的数据集类型
class_name = train_sets.classes # 查看标签 ['0 - zero', '1 - one', '2 - two', '3 - three', '4 - four', '5 - five', '6 - six', '7 - seven', '8 - eight', '9 - nine']
class_data_shape = train_sets.data.shape # torch.Size([60000, 28, 28])
class_target_shape = train_sets.targets.shape # torch.Size([60000])4. 数据分批
这一步非常的重要,这一步的主要目的是将测试集的60000个数据,每一批每一批的导入。而先前定义的超参数Batch_Size,则是这每一批导入数据的个数,一共会导入60000/Batch_Size批数据。
之后我们可以查看分批导入数据的数据特征,运用到的代码如下。我们能够发现这里imgs的尺寸为[64, 1, 28, 28],比上面的[60000,28,28]多了一维,哔哩哔哩的老师介绍的多出的一维为颜色通道。
# 4.数据分批(创建数据集的可迭代对象,也就是说一个batch一个batch的读取数据)
train_loader = DataLoader(dataset=train_sets,batch_size=Batch_Size,shuffle=True)
test_loader = DataLoader(dataset=test_sets,batch_size=Batch_Size,shuffle=True)
# 5.查看分批导入数据的数据特征
print(type(train_loader)) # 了解一下数据特征,图片是28*28个像素
dataiter = iter(train_loader) # 创建一个可迭代的对象
imgs, labs = next(dataiter) # imgs是64张图片的数据,labs则是64张图片的标签
imgs.size() # torch.Size([64, 1, 28, 28]),1是颜色通道5. 显示一批数据
这一步的工作就是为了显示我们导入的一批数据,代码如下(这一步我个人认为和这个项目的关系不是那么大,所以没有细看,之后有机会再补充)。
# 6.定义函数,显示一批数据
def imshow(inp, title=None):
inp = inp.numpy().transpose((1, 2, 0)) # 先转换为numpy格式,颜色通道改变
mean = np.array([0.485, 0.456, 0.406]) # 均值
std = np.array([0.229, 0.224, 0.225]) # 标准差
inp = std * inp + mean # 数据恢复
inp = np.clip(inp, 0, 1) # 数据压缩,像素值限制在【0,1】之间
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001)
# 7.网格显示 make_grid显示
out = torchvision.utils.make_grid(imgs)
imshow(out)显示结果如下图所示。

图4 显示的一批数据
6. 定义网络模型
在这里我们需要定义一个网络模型,首先初始化一个RNN和全连接层,再定义一个前向传播。(有点崩溃,写到最后了结果没保存,我的心态现在非常的朴妍珍)
6.1 RNN定义
此处需要使用到nn.RNN函数(这个部分的详解见这里PyTorch nn.RNN 参数全解析,这位小哥的讲解非常的清楚,看完受益匪浅。这里也附加上我对于这篇文章的笔记。)

图5 笔记
关于N×L×d的理解见图6,若是一个句子的长度为3,一个字的长度为28,则L为3,d为28,N为一批传入的数据,即Batch_Size。在这个项目中L为28(图片的长度),d为28(图片的宽度)。

图6 N×L×d的理解方式
关于全连接层,使用到的是nn.Linear(),详解见此PyTorch的nn.Linear()详解。
6.2 前向传播
定义前向传播需要先定义初始隐态h0(但是这部分我没有使用到)。之后将输入数据传入先前定义的RNN,之后将获得的r_out的最后一个状态ht输出给全连接层,以获得输出。所以在这里r_out[:, -1, :]的作用则是获得最后状态ht。
# 8.定义网络模型
class RNN(nn.Module):
def __init__(self):
super(RNN,self).__init__() # (初始化)
input_size, hidden_size, output_size = Input_Size, 64, 10
self.rnn = nn.LSTM(
input_size=Input_Size, # d
hidden_size=64, # h 隐藏神经元的个数
num_layers=1, # RNN的层数
batch_first=True, # N×L×d,以batch_size为第一维度,若是false则是L×N×d
)
self.out = nn.Linear(hidden_size, output_size) # 定义一个全连接层
def forward(self, x): # 定义前向传播
h0 = torch.zeros(1, x.size(0), 64).to(device) # h_0的格式为 num_layers×N×h
r_out, _ = self.rnn(x)
out = self.out(r_out[:, -1, :]) # 将r_out传给全连接层,-1是最后一层的状态,ht
return out7. 定义使用GPU
代码如下,但是由于我的电脑不具备GPU,所以之后包含GPU的语句并没有写入,未来有空进行补充。
# 9.使用定义好的RNN
model = RNN()
# 判断是否有GPU
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# 模型和输入数据都需要to device
mode = model.to(device)8. 定义损失函数和优化器
关于这两个函数的详解见nn.CrossEntropyLoss()交叉熵损失函数和Python-torch.optim优化算法理解之optim.Adam()。
# 10.定义损失函数,以及分类器 分类问题使用交叉信息熵
loss_func = nn.CrossEntropyLoss()
# 定义优化器
optimizer = torch.optim.Adam(model.parameters(), lr=LR)9. 模型训练
首先我们对一些参数进行定义。
# 11.训练前的参数定义
loss_list = [] # 保存loss
accuracy_list = [] # 保存accuracy
iteration_list = [] # 保存循环次数
iter = 0 # 循坏第0次开始,作为计数器之后开始训练,整个训练流程进行了较为详细的备注:
# 12.开始训练
for epoch in range(Epoch):
# 60000/BATCH_SIZE
for step, data in enumerate(train_loader): # STEP∈[0,975]
model.train() # 声明训练
inputs, labels = data # 取出数据及标签
inputs = inputs.view(-1, 28, 28) # 修改形状,变换为RNN的输入维度,参数-1 指自动调整size,此时inputs的格式变为[64, 28, 28]
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad() # 梯度清零
outputs = model(inputs) # 前向传播
loss = loss_func(outputs, labels) # 计算损失函数
loss.backward() # 反向传播
optimizer.step() # 参数更新
# 测试,计算准确率
if step % 100 == 0: # 每100次进行一次模型的验证
model.eval() # 模型声明
# 计算验证的accuracy
correct = 0.0 # 正确的
total = 0.0 # 总数
for test_x, test_y in test_loader:
test_x = test_x.view(-1, 28, 28) # 验证集,修改形状,变换为RNN的输入维度,参数-1 指自动调整size
test_x = test_x.to(device)
# 模型验证
test_outputs = model(test_x) # 前向传播
# 获取预测概率最大值的下标
predict = torch.max(test_outputs.data, 1)[1]
print("test_x", test_x.size())
print("test_outputs", test_outputs.size())
# 统计测试集的大小
total += labels.size(0)
# 统计判断/预测正确的数量
correct += (predict == test_y).sum()
# 计算accuracy
accuracy = correct / total * 100
# 保存accuracy,loss,iteration
loss_list.append(loss.data)
accuracy_list.append(accuracy)
iteration_list.append(iter)
# 打印信息
print("loop:{},LOSS:{},Accuracy:{}".format(iter, loss.item(), accuracy))
iter += 1 # 计数器自动加1这里对我在学习的过程中,开始不太明白的地方进行一个补充:
1.首先inputs.view(-1, 28, 28)的使用是由于,inputs的形状为[64, 1, 28, 28],而输入RNN所需要的形状为[64, 28, 28],所以.view()函数使用的目的是为了将形态转换为适合RNN的维数。
2.关于反向传播的目的,我们知道最后我们在得出预测值后与真实值进行比较可以得到误差,这个误差是关于权重w的一个函数,那么我们可以通过梯度下降法来更行权重以获得损失函数的最小值。关于反向传播的更加详细的知识见“反向传播算法”过程及公式推导(超直观好懂的Backpropagation),梯度下降法的原理见详解梯度下降算法。都是非常好理解的干货文章。
3.关于torch.max()函数
# torch.max()[1].data.numpy() 把数据转化成numpy ndarry # torch.max(action_value, 1)表示取action_value里每行的最大值 # torch.max(action_value, 1)[1]表示最大值对应的下标
10. 可视化
# 13.可视化
plt.plot(iteration_list, loss_list)
plt.xlabel("Number of Iteration")
plt.ylabel("Loss")
plt.title("LSTM")
plt.show()
plt.plot(iteration_list, accuracy_list)
plt.xlabel("Number of Iteration")
plt.ylabel("Accuracy")
plt.title("LSTM")
plt.show()11. 最终结果
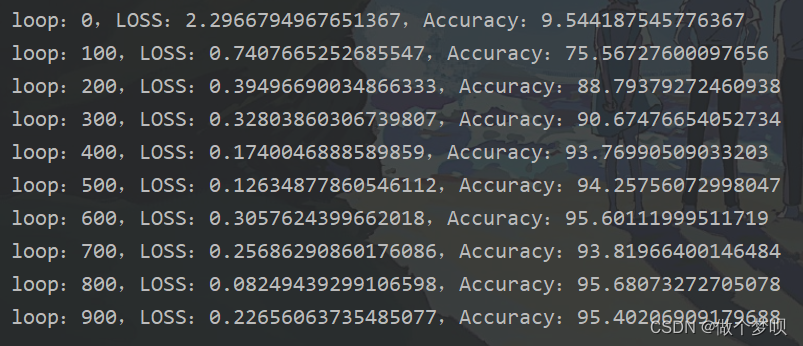
epoch设置为一,900批数据进行验证,验证结果如下。


12. 完整代码
import numpy as np
import torch
import torch.nn as nn
import torchvision
import torchvision.datasets as datasets
import torchvision.transforms as transforms
from torch import device
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
# 1.定义超参数
Epoch = 1 # 训练次数
Batch_Size = 64 # N,设置了每批次装载(读取)的数据图片为64个(自行设置)
Input_Size = 28 # d,图片宽度
Time_Step = 28 # L,图片长度
LR = 0.01 # 学习率
# 2.导入数据集
train_sets = datasets.MNIST(root='./data/', train=True, transform=transforms.ToTensor(), download=True)
test_sets = datasets.MNIST(root='./data/', train=False, transform=transforms.ToTensor(), download=True)
# 3.查看导入的数据集类型
class_name = train_sets.classes # 查看标签 即[0-9]
class_data_shape = train_sets.data.shape # torch.Size([60000, 28, 28])
class_target_shape = train_sets.targets.shape # torch.Size([60000])
# 4.数据分批(创建数据集的可迭代对象,也就是说一个batch一个batch的读取数据)
# 关于DataLoader详解见RNN.py文件
train_loader = DataLoader(dataset=train_sets,batch_size=Batch_Size,shuffle=True)
test_loader = DataLoader(dataset=test_sets,batch_size=Batch_Size,shuffle=True)
# 5.查看分批导入数据的数据特征
print(type(train_loader)) # 了解一下数据特征,图片是28*28个像素
dataiter = iter(train_loader) # 创建一个可迭代的对象
imgs, labs = next(dataiter) # imgs是64张图片的数据,labs则是64张图片的标签
imgs.size() # torch.Size([64, 1, 28, 28]),1是颜色通道
# 6.定义函数,显示一批数据
def imshow(inp, title=None):
inp = inp.numpy().transpose((1, 2, 0)) # 先转换为numpy格式,颜色通道改变
mean = np.array([0.485, 0.456, 0.406]) # 均值
std = np.array([0.229, 0.224, 0.225]) # 标准差
inp = std * inp + mean # 数据恢复
inp = np.clip(inp, 0, 1) # 数据压缩,像素值限制在【0,1】之间
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001)
# 7.网格显示 make_grid显示
out = torchvision.utils.make_grid(imgs)
imshow(out)
# 8.定义网络模型
class RNN(nn.Module):
def __init__(self):
super(RNN,self).__init__() # (初始化)
input_size, hidden_size, output_size = Input_Size, 64, 10
self.rnn = nn.LSTM(
input_size=Input_Size, # d
hidden_size=64, # h 隐藏神经元的个数
num_layers=1, # RNN的层数
batch_first=True, # N×L×d,以batch_size为第一维度,若是false则是L×N×d
)
self.out = nn.Linear(hidden_size, output_size) # 定义一个全连接层
def forward(self, x): # 定义前向传播
h0 = torch.zeros(1, x.size(0), 64).to(device) # h_0的格式为 num_layers×N×h
r_out, _ = self.rnn(x)
out = self.out(r_out[:, -1, :]) # 将r_out传给全连接层,-1是最后一层的状态,ht
return out
# 9.使用定义好的RNN
model = RNN()
# 判断是否有GPU
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# 模型和输入数据都需要to device
mode = model.to(device)
# 10.定义损失函数,以及分类器 分类问题使用交叉信息熵
loss_func = nn.CrossEntropyLoss()
# 定义优化器
optimizer = torch.optim.Adam(model.parameters(), lr=LR)
# 11.训练前的参数定义
loss_list = [] # 保存loss
accuracy_list = [] # 保存accuracy
iteration_list = [] # 保存循环次数
iter = 0 # 循坏第0次开始,作为计数器
# 12.开始训练
for epoch in range(Epoch):
# 60000/BATCH_SIZE
for step, data in enumerate(train_loader): # STEP∈[0,975]
model.train() # 声明训练
inputs, labels = data # 取出数据及标签
inputs = inputs.view(-1, 28, 28) # 修改形状,变换为RNN的输入维度,参数-1 指自动调整size,此时inputs的格式变为[64, 28, 28]
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad() # 梯度清零
outputs = model(inputs) # 前向传播
loss = loss_func(outputs, labels) # 计算损失函数
loss.backward() # 反向传播
optimizer.step() # 参数更新
# 测试,计算准确率
if step % 100 == 0: # 每100次进行一次模型的验证
model.eval() # 模型声明
# 计算验证的accuracy
correct = 0.0 # 正确的
total = 0.0 # 总数
for test_x, test_y in test_loader:
test_x = test_x.view(-1, 28, 28) # 验证集,修改形状,变换为RNN的输入维度,参数-1 指自动调整size
test_x = test_x.to(device)
# 模型验证
test_outputs = model(test_x) # 前向传播
# 获取预测概率最大值的下标
predict = torch.max(test_outputs.data, 1)[1]
# 统计测试集的大小
total += labels.size(0)
# 统计判断/预测正确的数量
correct += (predict == test_y).sum()
# 计算accuracy
accuracy = correct / total * 100
# 保存accuracy,loss,iteration
loss_list.append(loss.data)
accuracy_list.append(accuracy)
iteration_list.append(iter)
# 打印信息
print("loop:{},LOSS:{},Accuracy:{}".format(iter, loss.item(), accuracy))
iter += 1 # 计数器自动加1
# 13.可视化
plt.plot(iteration_list, loss_list)
plt.xlabel("Number of Iteration")
plt.ylabel("Loss")
plt.title("LSTM")
plt.show()
plt.plot(iteration_list, accuracy_list)
plt.xlabel("Number of Iteration")
plt.ylabel("Accuracy")
plt.title("LSTM")
plt.show()













 3400
3400











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









