






前面学习到了全连接神经网络和卷积神经网络,以及它们的训练和使用。他们都只能单独的取处理一个个的输入,前一个输入和后一个输入是完全没有关系的。但是,某些任务需要能够更好的处理序列的信息,即前面的输入和后面的输入是有关系的。比如,当我们在理解一句话意思时,孤立的理解这句话的每个词是不够的,我们需要处理这些词连接起来的整个序列;当我们处理视频的时候,我们也不能只单独的去分析每一帧,而要分析这些帧连接起来的整个序列。这时,就需要用到深度学习领域中另一类非常重要神经网络:循环神经网络(Recurrent Neural Network)。在过去的几年里,RNN应用于语音识别,语言建模,翻译,图像字幕等各种问题上,并且取得了巨大的成功。
为了做预测,使前一个结果的输出影响下一个神经元,例如:我 昨天 上学 迟到 了 ,老师 批评 了 ____,这里切词的关键在于我,要回去9个位置。下图是一个简单的循环神经网络如,它由输入层、一个隐藏层和一个输出层组成:
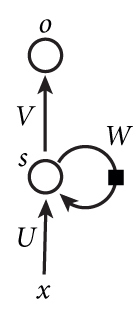
如果把W给他去了,就成了最简单的全连接神经网络了,x是一个向量,它表示输入层的值s是一个向量,它表示隐藏层的值,U是输入层到隐藏层的权重矩阵,o也是一个向量,它表示输出层的值;V是隐藏层到输出层的权重矩阵,循环神经网络的隐藏层的值s不仅仅取决于当前这次的输入x,还取决于上一次隐藏层的值s。权重矩阵 W就是隐藏层上一次的值作为这一次的输入的权重。
我们把这个结构展开,就变成了
输出层Ot=F(Vst),隐藏层st=G(st-1W+Uxt),其中F和G为激活函数。
双向循环神经网络
我的手机坏了,我打算____一部新手机。
关键词是手机坏了、新手机,如果是这种输入,需要前面和后面同时作用,才能准确判断出空格的词。这就需要双向循环神经网络了,其实也很好理解,就是将2个循环神经网络拼接起来,方向相反。

RNN的弊端

从这张图可以看出,在经历多次传播之后,前面远的神经元对现在的影响会变小,即出现梯度消失的情况,我们希望网络有个好的心态——选择性记忆和遗忘,对他有影响的记下来,对他没有没有影响的忘记。为了解决RNN存在的梯度消失问题,科学家们花费7年时间,分析出了LSTM(长短时记忆网络),解决了RNN的问题,此前,说人们通过RNN取得了显著的成果,这些成果基本上都是使用LSTM实现的。这足以表明LSTM的强大。
假设某轮训练中,各时刻的梯度以及最终的梯度之和如下图:

我们就可以看到,从上图的t-3时刻开始,梯度已经几乎减少到0了。那么,从这个时刻开始再往之前走,得到的梯度(几乎为零)就不会对最终的梯度值有任何贡献,这就相当于无论t-3时刻之前的网络状态h是什么,在训练中都不会对权重数组W的更新产生影响,也就是网络事实上已经忽略了t-3时刻之前的状态。这就是原始RNN无法处理长距离依赖的原因。
LSTM核心结构图
前面描述的开关是怎样在算法中实现的呢?这就用到了门(gate)的概念。门实际上就是一层全连接层,它的输入是一个向量,输出是一个0到1之间的实数向量。假设W是门的权重向量,b是偏置项。
门的使用,就是用门的输出向量按元素乘以我们需要控制的那个向量。因为门的输出是0到1之间的实数向量,那么,当门输出为0时,任何向量与之相乘都会得到0向量,这就相当于啥都不能通过;输出为1时,任何向量与之相乘都不会有任何改变,这就相当于啥都可以通过。因为(也就是sigmoid函数)的值域是(0,1),所以门的状态都是半开半闭的。

LSTM结构图展开
所有门的输入为3个:本层的cell,上一层的输出,本层的输入,门的开闭相当于权值。是训练出来的。

LSTM工作过程(一看就明白)

RNN+LSTM的代码实现,解决MNIST手写数字识别的问题。核心在于函数RNN,其他的部分和之前用全连接网络实现是一样的。
import tensorflow as tf
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
#载入Mnist数据集
mnist=input_data.read_data_sets("MNIST_data",one_hot=True)
#输入图片是28*28
max_time=28 #一共有28行
n_inputs=28 #一行有28个数据
lstm_size=100 #隐藏层单元,这里可不是神经元,而是一个bloack
n_classes=10 #10个分类
batch_size=50
n_batch=mnist.train.num_examples//batch_size #//是整除的意思。计算一共有多少个批次
x=tf.placeholder(tf.float32,[None,784])#None表示可以取任意值,方便后面传入。
y=tf.placeholder(tf.float32,[None,10])#y就是标签,正确答案
#创建一个简单的神经网络(前向传播)
weights=tf.Variable(tf.truncated_normal([lstm_size,n_classes],stddev=0.1))
biases=tf.Variable(tf.constant(0.1,shape=[n_classes]))
#定义RNN网络
def RNN(X,weights,biases):
#inputs=[batch_size,max_time,n_inputs]
inputs=tf.reshape(X,[-1,max_time,n_inputs])#改变X的shape,使它可以参与运算
#定义LSTM基本cell
lstm_cell=tf.contrib.run.core_run_celll.BasicLSTMCell(lstm_size)
#final_state[0]是cell_state
#final_state[1]是hidden_state
outputs,final_state=tf.nn.dynamic_run(lstm_cell,inputs,dtype=tf.float32)
results=tf.nn.softmax(tf.matmul(final_state[1],weights)+biases)
return results
#计算RNN的返回结果
prediction=RNN(x,weights,biases)
#二次代价函数(反向传播)
cross_entropy=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=prediction,labels=y))
train_step=tf.train.AdamOptimizer(0.0001).minimize(cross_entropy)
#重点理解这两句,有新东西。
correct_prediction=tf.equal(tf.argmax(y,1),tf.argmax(prediction,1))
#tf.argmax(input,axis)根据axis取值的不同返回每行或者每列最大值的索引。axis为1表示取行最大值得索引。
#如果两个值相等,返回TRUE,结果保存的是布尔型的列表
accuracy=tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
#tf.cast()类似强制类型转换,把布尔型变为32位float型,然后求平均。[1,1,1,0,0,0,1,1,1,1],准确率为0.7
init=tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for epoch in range(6):
for batch in range(n_batch):
batch_xs,batch_ys=mnist.train.next_batch(batch_size)
sess.run(train_step,feed_dict={x:batch_xs,y:batch_ys})
acc=sess.run(accuracy,feed_dict={x:mnist.test.images,y:mnist.test.labels})
print("iter"+str(epoch)+",Testing Accuracy"+str(acc))















 3651
3651











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









