






Pig 用于描述数据流的脚本语言,叫 Pig Latin。
如果只涉及一个大型数据集中的一小部分数据,Pig不会表现很好,因为它要扫描整个数据集或其中的很大一部分。
Pig有两种执行模式
1.本地模式
本地模式下,Pig运行在单个JVM中,访问本地文件系统。该模式只适用处理小规模数据集或使用Pig。
本地模式运行,需把选项设置为local
bin/pig -x local
2.MapReduce模式
此模式下,Pig将查询翻译为MapReduce作业,然后在Hadoop上运行。
bin/pig -x mapreduce // 不使用-x ,默认即为mapreduce模式。
pig 使用-e选项直接在命令行以字符串形式输入脚本.
Pig有三种数据格式
字段 比如 int 或者 chararray。
元组 字段的有序集。使用()。比如(int,int,chararray)和(chararray,int,int)是不同的元组。
包 元组的无序集。 一些元组的集合。使用 { } 。
关系 类似于包。
ok,现在开始第一个“hello_world”
给出数据(年份,气温,质量),求出每年的最高气温。
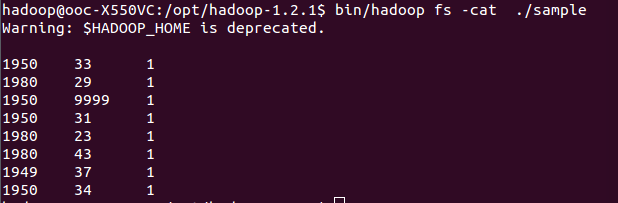
ok,接下来是代码。
records = LOAD 'sample' AS (year:int,temperature:int,a:int);
// 从默认路径 /user/hadoop读取sample,解析为三个int类型,并分别命名。
filtered_records = FILTER records BY temperature !=9999;
// 过滤records,temperature!=9999,才可以。
group_records = GROUP filtered_records BY year;
// 把相同year的元组合成一个包,然后和系统自建的group变量组成新元组。
// group_records的结构 {group: int,filtered_records: { ( year:int , temperature:int , a:int ) } }
max_temp = FOREACH group_records GENERATE group,MAX(filtered_records.temperature);
// FOREACH 对每一行处理, GENERATE 定义导出字段。 这里输出group和 每个filtered_records中temperature的最大值。
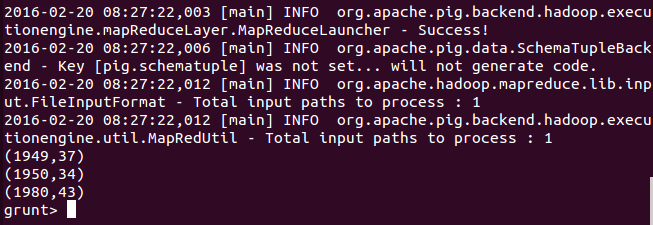
DUMP max_temp;
// 查看 max_temp 的内容。
输出的max_temp结果
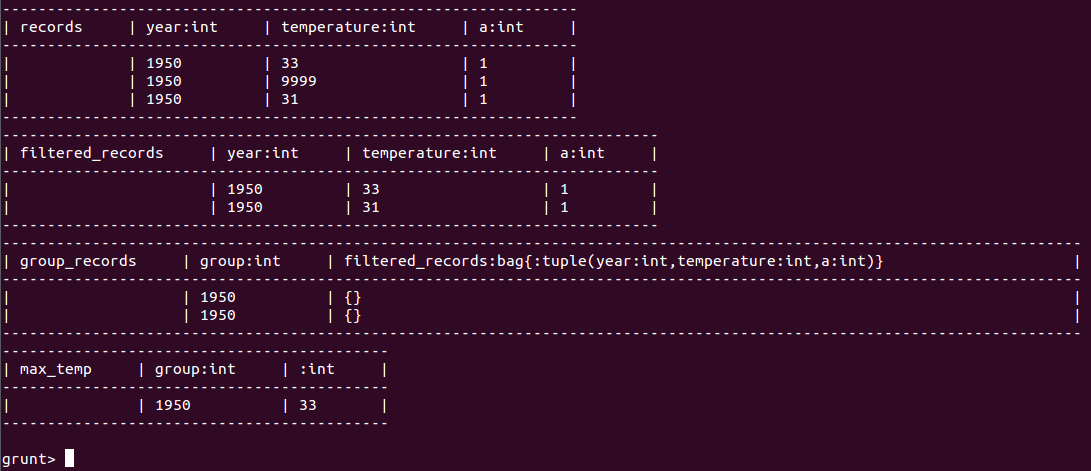
DESCRIBE group_records ; // 描述此变量的格式

ILLUSTRATE max_temp; // 描述max_temp的数据流















 95
95

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









