







基于Python2.7
1.基础内容
#!/usr/bin/env python
#-*-coding:utf-8-*-
import math
print 'Hello world'
print 'Hello','world' # , 处输出空格
#格式化输出
a = 100
print 'Hello,%s %d' % ('world',a)
#Hello,world 100
num = input('please input a number\n') #input a number
print num+100 # 这里num为int型
num = raw_input("please input a string\n") #input a string
#print num+100 #error,这里num为字符串类型
#字符串用'' "" 均可
#Python 中没有常量
a = 100
if a>=0 and a<200:
print a #通过缩进控制函数体
else:
print -a
L = ['B','A','C']
for a in L:
print 'Hello ,',a #print 自动输出换行2. 数据结构的使用
#!/usr/bin/env python
#-*-coding:utf-8-*-
import math
classmates = ['ooc','zc','tom'] #list 有序集合
print classmates[2],classmates[-1]
#输出 tom tom
classmates.insert(1,'Jerry') #把元素插入到指定位置
print classmates[1]
#print Jerry
classmates.pop() #删除list末尾
classmates.pop(2) #删除指定位置
#list中的元素可以为不同类型
#list实现类似数组指针
#tuple
classmates = ('ooc','zc',['A','B']) #tuple,其中最后一个元素是list
#tuple 中的元素一旦初始化就不能改变,但这里list中的元素可以改变,list不能改变
#dict的使用(和C++ Map相似) # Hash 实现
d = {'ooc':30, 'zc':33, 'Jerry':40}
print d['zc'] # print 33
d['tom'] = 44 # 向d中添加键值对
print d['tom']
if 'tom' in d: #如果tom在d中存在返回true
print 'tom in d'
d.pop('tom') #删除d中tom为键的键值对
else:
print 'tom not in d'
d['tom'] = 33 #添加 tom - 33 键值对
#set 类似C++ 中的set集合
s = set([1,1,2,2,3]) # 过滤为 1,2,3
s.add(4) # add 4
s.remove(2) #remove 2
s1 = set([5,6])
s & s1 # 交集
s | s1 # 并集3.简单函数调用
a.py:
# -*- encoding=utf-8 -*-
import math
def cal(x,y,z): #定义cal函数
if not isinstance(x,(int,float)): #x属于int或float返回true
raise TypeError('not not not')
n = math.sqrt(y*y-4*x*z)
return (-y+n)/2/x,(-y-n)/2/x # 返回两个参数b.py:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from a import cal #引入a文件中的cal函数
#这里会先执行a.py中的代码(非函数中的代码!)
n = 3
m = 40
o = 4
anw,a1 = cal(n,m,o) # anw = cal(n,m,o) 用一个接也可,这里anw为一个tuple
print anw,a1 # print anw 4.列表生成式与生成器Generator
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#列表生成式
print [x * x for x in range(1,11)] #range(1,11) 生成1 ... 10
# [1, 4, 9, 16, ... , 99, 100]
print [x * x for x in range(1,11) if x % 2 == 0]
# [4, 16, 36, 64, 100]
L = ['HELLO','WORLD','IBM']
print [s.lower() for s in L]
# ['hello', 'world', 'ibm']
#生成器Generator
#如果列表元素可以按照某种算法推算出来
#这样就不必创建完整的list,从而节省大量的空间
#可以在循环中不断推算出后续的元素,以免一次全算出来效率低下
L = [x * x for x in range(10)] #L为一个list
g = (x * x for x in range(10)) #g为生成器
print g.next() #可以用这种方式一个一个输出
for n in g: #常用这种方式输出
print n
# 自定义Generator
def fib(m): #生成斐波拉切数列的生成器
n, a, b = 0, 0, 1
while n < m:
yield b #每次调用next()时执行,遇到yield返回
a, b = b, a + b #当函数执行结束后,再调用next()报错
n = n + 1
for n in fib(5):
print n
# 1 1 2 3 5判断是否可迭代
from collections import Iterable
#只要是可迭代对象即可用for ... in 循环
if isinstance('abc',Iterable): #判断str是否为可迭代对象
print 'string 可迭代'
else:
print 'string 不可迭代'
5.命令行参数
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import sys # 当前文件为b.py
print sys.argv #为一个list,第一个参数为文件名,后是命令行参数
# ['b.py']
#高阶函数
#Python中变量可以指向函数,函数的参数能接收变量
#那么一个函数就可以接收另一个函数作为参数,这种函数称为高阶函数。
6.异常处理
#!/usr/bin/env python
# -*- encoding=utf-8 -*-
#Python异常处理,与Java相似
try:
print 'try ...' #正常输出
r = 10 / 0 #出现除0错误,抛异常
print 'result:', r #未输出
except ZeroDivisionError, e:
print 'except:', e #输出
finally:
print 'finally...' #无论如何都输出
print 'END' #输出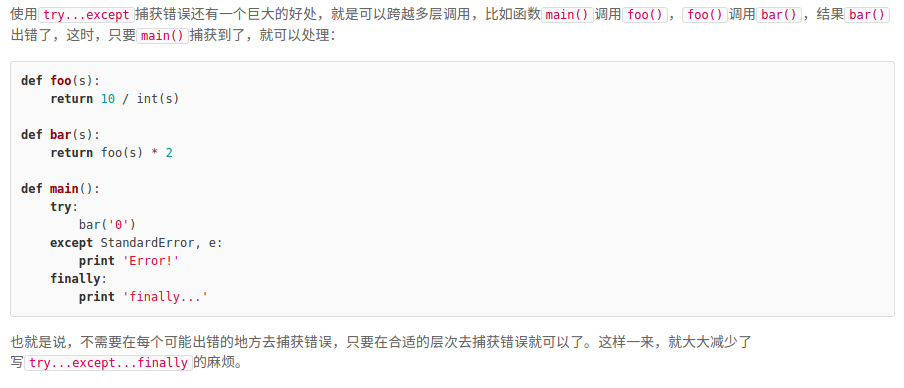
7.文件读写
读文件
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# 读写文件
try:
f = open('test.txt','r') #只读方式打开
print f.read() #一次读入所有内容
finally:
if f:
f.close()
#with 语句的写法
with open('test.txt','r') as f:
print f.read()
#两种写法作用相同
with open('test.txt','r') as f:
for line in f.readlines():
#readlines()一次读入所有内容,按行返回list
print(line.strip())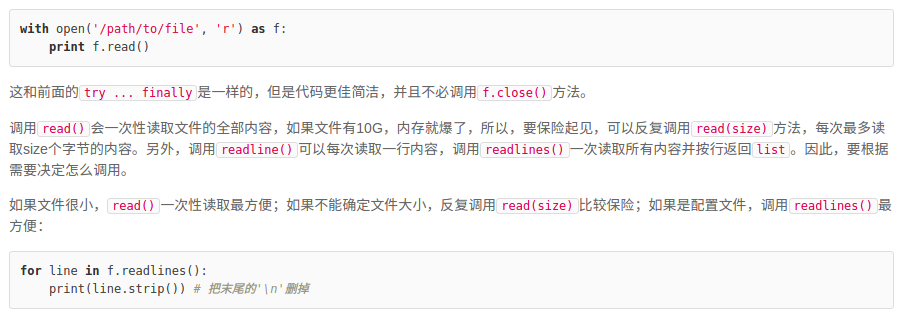
readline() 从文件读取整行,包括 “\n” 字符,当readline()读到结尾EOF时,返回空字符串 ”
写文件
#!/usr/bin/env python
# -*- encoding=utf-8 -*-
# 写文件
f = open('test.txt','w') #test.txt 中的原内容被清除
#'w'表示写文本文件,'wb'表示写二进制文件。
#'a+' 表示追加读写
f.write('1 大幅上升三十三岁所示1\n')
f.write('0 的发放反反复复反反复复2\n')
f.close()
#等价写法
with open('test.txt','w') as f:
f.write('1 大幅上升三十三岁所示1\n')
f.write('0 的发放反反复复反反复复2\n')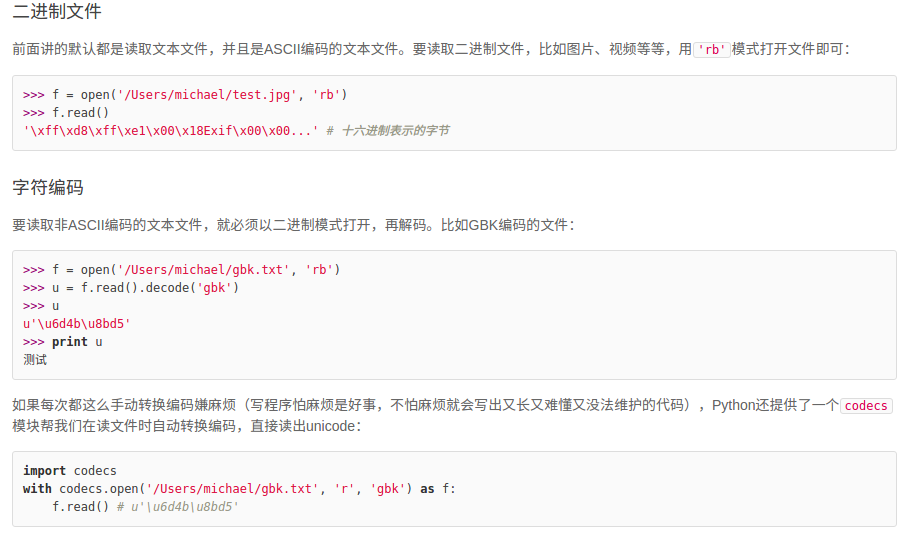
文件操作
#!/usr/bin/env python
# -*- encoding=utf-8 -*-
import os
os.mkdir('/home/ooc/test/hh') #创建目录
os.rmdir('/home/ooc/test/hh') #删除目录
os.rename('test.txt','test.tx') #对文件重命名
os.remove('aa') #删除文件
print os.path.abspath('.') #打印当前路径 这里为/home/ooc/test














 433
433











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









