









当使用LableEncoder对数据进行编码时,先fit数据,在transform时如果遇到fit时没有遇过的数据,程序会抛出ValueError异常。
这里相对fit时没遇过的数据统一编码为一个值。
我的解决:
x_train = LabelEncoder_list[i].fit_transform(dfTrain[feat].values) # fit并编号one-hot
try:
x_test = LabelEncoder_list[i].transform(dfTest[feat].values) # 编号one-hot
except ValueError:
print("LabelEncoder_list[",i,"] transform out range.")
x_test = []
feat_len = len(dfTest[feat].values)
fit_len = len(LabelEncoder_list[i].classes_)
for j in range(feat_len):
if len(np.intersect1d(dfTest[feat].values[j], LabelEncoder_list[i].classes_)) == 1:
# 看当前value与fit的数据集是否有交集
x_test.append(np.searchsorted(LabelEncoder_list[i].classes_, dfTest[feat].values[j]))
# 如果有,把fit的编号返回
else:
x_test.append(fit_len + 2)
# 没有则返回一个fit中没有的编号
# 编号为 0 - (fit_len - 1)
x_test = np.array(x_test) # change list to array
print("fit_len : ", fit_len)
print("out range x_test : ", x_test)
except:
print("Error!")
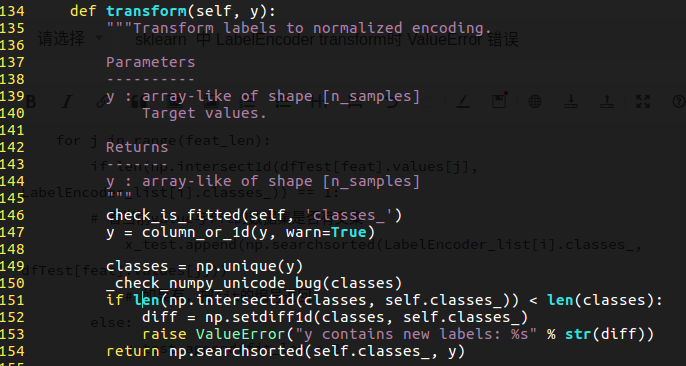
raiseLabelEncoder.transform() 的源码:















 1051
1051

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









