






近来在了解深度学习。深度神经网络的一大特点就是含有多隐含层。卷积神经网络(CNN)算是深度神经网的前身了,在手写数字识别上在90年代初就已经达到了商用的程度。本文中将简要介绍CNN,由于相应的博文资料已经很多,也写的很好,本篇最有价值的是参考资料部分。
前向神经网络数字识别
假设我们的图片是28*28像素的,使用最简单的神经网络进行识别,如图1
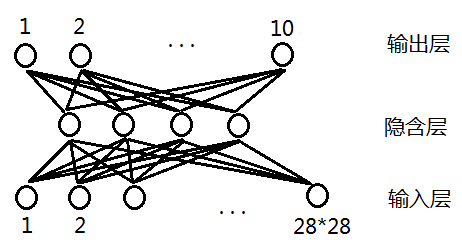
图1
输入层是像素值(一般使用黑白二进制),输出层是10个数字,隐含层的层数和节点书可以调整,图1只是示意。
这样的神经网络模型是可行的,但效果不会非常好,其存在以下问题:
1. 一般要得到较好的训练效果,隐层数目不能太少,当图片大的时候,需要的权值会非常多!
2. 对平移、尺度变化敏感(比如数字偏左上角,右下角时即识别失败)
3. 图片在相邻区域是相关的,而这种网络只是一股脑把所有像素扔进去,没有考虑图片相关性。
卷积神经网络(CNN)
CNN通过local receptive fields(感受野),shared weights(共享权值),sub-sampling(下采样)概念来解决上述三个问题【2】。
LeNet-5是一个数字手写系统,其结构图如下,是一个多层结构
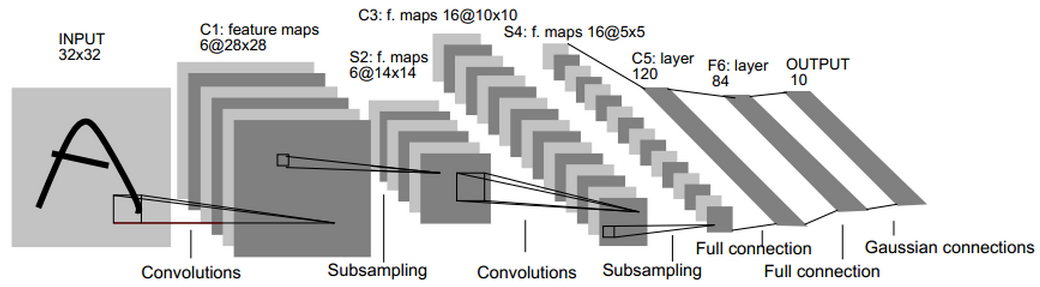
图2
这个图在各种资料里出现的非常多,在此偷个懒,不详细解释了。对此图最详细的说明请见【2】。
有一点要特别容易理解出错:权值共享不是5*5小块内的权值一样。5*5小块有25个不同权值,其作为一个滤波器,像抹窗户一样遍历整个图片。
推荐读物
【1】http://blog.csdn.net/zouxy09/article/details/8781543 (我的小伙伴的博文,非常适合作为入门级读物,他的一系列博客都很好)
【2】Gradient-Based Learning Applied to Document Recognition (极好的文!尤其是p5-p9,一定要细看,反复琢磨。把LeNet-5的来龙去脉讲得清清楚楚)
【3】http://yann.lecun.com/exdb/lenet/index.html (Yann LeCunn实现的CNN演示,以动画的形式演示了位移、加噪、旋转、压缩等识别,最有价值的是把隐层用图像显示出来了,很生动形象)
【4】http://blog.csdn.net/celerychen2009/article/details/8973218 (一位网友的博客,基本上是对【2】的通俗讲解)
【5】http://www.cnblogs.com/tornadomeet/archive/2013/04/09/3009830.html (一位网友的仿真实验,有助于理解,他的一系列博客都很注重实验)
http://www.codeproject.com/Articles/16650/Neural-Network-for-Recognition-of-Handwritten-Digi (一位外国网友自己实现的CNN,重构LeCunn的实验)
【6】Receptive fields, binocular interaction and functional architecture in the cat's visual cortex (1963年的文章,猫的局部感受野的生理学基础,从生理学上支持CNN是有效的,很长,我只略扫了一眼)















 5095
5095

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









