







1. 定量特征二值化
在数据挖掘领域,定量特征二值化的目的是为了对定量的特征进行“好与坏”的划分,以剔除冗余信息。举个例子,银行对5名客户的征信进行打分,分别为50,60,70,80,90。现在,我们不在乎一个人的征信多少分,只在乎他的征信好与坏(如大于90为好,低于90就不好);再比如学生成绩,大于60及格,小于60就不及格。这种“好与坏”、“及格与不及格”的关系可以转化为0-1变量,这就是二值化。变化方式如下所示:
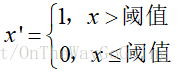
from sklearn.preprocessing import Binarizer
#阈值设置为3,对x的每一个元素都进行二值化
Binarizer(threshold=3).fit_transform(x) 2. 定性特征哑编码

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









