







 本文介绍了GShard的自动并行技术,该技术通过轻量级API和XLA编译器扩展实现大规模模型的并行训练。文章回顾了数据并行、模型并行的发展,讨论了GShard与其他自动并行方法的比较,指出GShard在张量切分抽象和命名方面存在的冗余和不完整性。同时,文章提出了OneFlow的SBP体系作为对比,强调了局部计算结果延迟规约的重要性,并指出GShard在多维划分概念的简洁性方面的不足。
本文介绍了GShard的自动并行技术,该技术通过轻量级API和XLA编译器扩展实现大规模模型的并行训练。文章回顾了数据并行、模型并行的发展,讨论了GShard与其他自动并行方法的比较,指出GShard在张量切分抽象和命名方面存在的冗余和不完整性。同时,文章提出了OneFlow的SBP体系作为对比,强调了局部计算结果延迟规约的重要性,并指出GShard在多维划分概念的简洁性方面的不足。

撰文 | 袁进辉
GShard的论文最早于2020.6.30放在arXiv上,包括《GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding (https://arxiv.org/pdf/2006.16668.pdf)》,还有一篇更系统的系统论文《GSPMD: General and Scalable Parallelization for ML Computation Graphs (https://arxiv.org/pdf/2105.04663.pdf)》。
文章内容主要包含两部分工作,一部分是并行API,一部分是Mixture of experts,比较有意思的是前一部分,我只讨论这部分,这部分的贡献在论文摘要里概括得很清楚:
GShard is a module composed of a set of lightweight annotation APIs and an extension to the XLA compiler.(GShard是由一组轻量级注释API和XLA编译器的扩展组成的模块。)
我也不打算过多介绍文章的细节,这些内容在原论文里都可以看到,只介绍一些背景信息,以及从OneFlow里做过的类似工作来评价一下GShard还有哪些可改进的地方。只有把GShard放在上下文里去看,才能更清楚地看到它的好和不好。
1
与GShard类似的工作带来的启发
这要从数据并行和模型并行说起,先列一下我知道的在GShard之前的相关工作。
1. One weird trick for parallelizing convolutional neural networks
这也许是最早探讨模型并行的文章,由Alex Krizhevsky (没错,就是AlexNet那位)在2014年发表在arXiv上(https://arxiv.org/pdf/1404.5997.pdf)。
这篇文章最大的洞见是发现不同的层适合用不同的并行方式。具体来说,卷积层数据比参数大,适合数据并行,全连接层参数比数据大,适合模型并行。
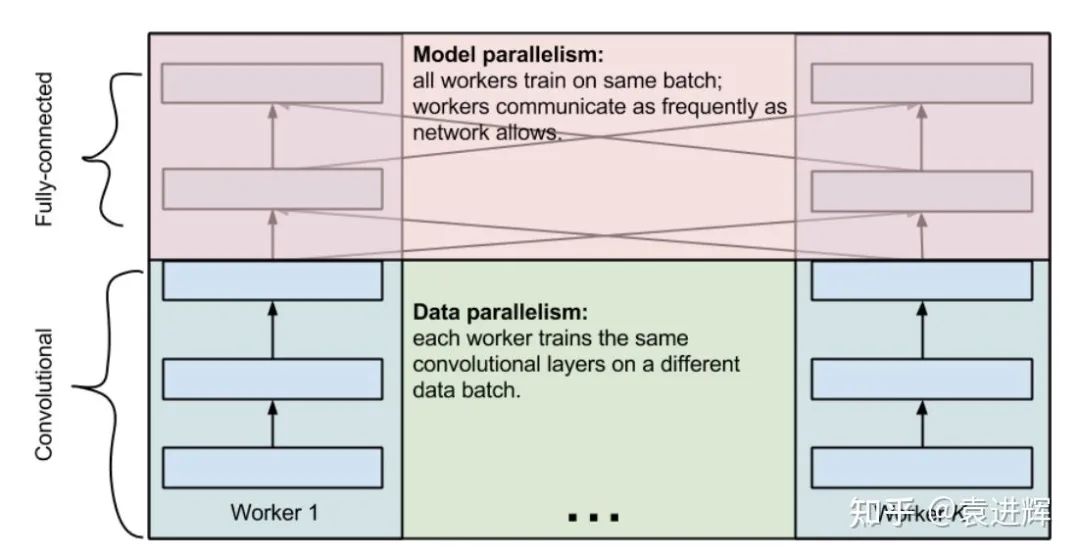
这最早是在cuda-convnet这个史前的深度学习框架上实现的,现在知道这套软件的人比较少了。
2. Exploring Hidden Dimensions in Parallelizing Convolutional Neural Networks
这篇由Zhihao Jia在2018年发在ICML(链接:https://cs.stanford.edu/~zhi
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 72
72

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









