








本文深入探讨了批处理在现代GPU上的工作原理,以及它是如何影响深度学习模型的推理速度,基于此,作者为模型优化提供了实用指导。通过优化批处理策略,研究人员和工程师可以更有效地利用计算资源,提高模型的推理效率。
(本文作者为机器学习研究员Finbarr Timbers,他曾是DeepMind的工程师。本文由OneFlow编译发布,转载请联系授权。原文:https://www.artfintel.com/p/how-does-batching-work-on-modern)
作者 | FINBARR TIMBERS
OneFlow编译
翻译|杨婷
对于任何现代深度学习系统而言,执行批处理是最重要的一项优化。批处理是指,在推理过程中不是发送单个输入,而是发送一个大小为N的输入批次。通常情况下,根据批次大小N的具体值,这项优化可以视为“免费”,因为整个批次的处理时间与处理单个示例的时间几乎相同。为何会这样?按理来讲,批处理不应该免费,毕竟要多做N倍的工作。
对于简单的神经网络模型来说,这并不是免费的,批处理计算确实需要N倍的计算资源来运行。如但果在CPU上运行这种批处理,你会发现这一点确实存在(在Colab上ResNet50的平均推理时间)。
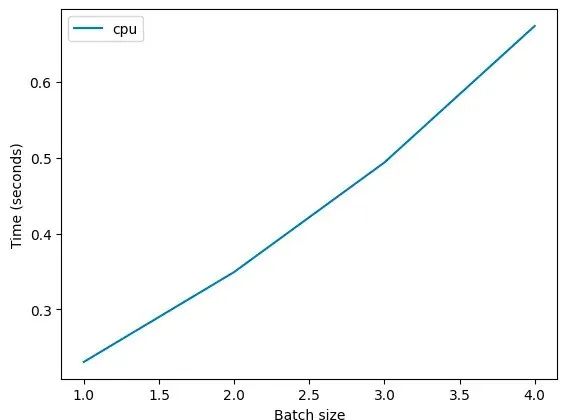
然而,当你在现代GPU上运行相同的示例时,情况就有所不同了。以下是我们观察到的现象(T4):
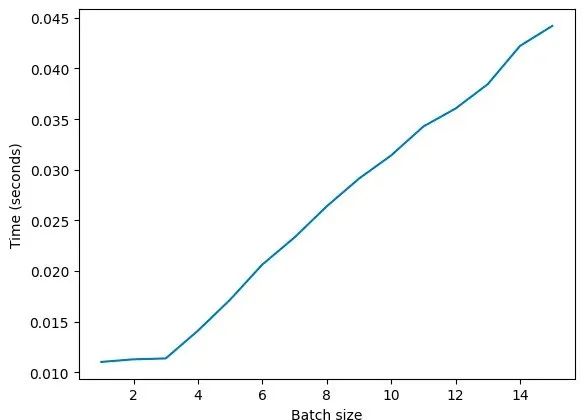
将批量大小从1增加到2、再增加到3都不需要额外的时间,之后才会线性增加。
为什么会这样呢?这是由于并发性。现代GPU可以并发地运行这些操作。(实际上,在每个线程的基础上,GPU的速度比CPU慢)。
在计算模型推理时,我们通常会将模型视为单个块(block),但实际上模型由许多矩阵组成。当我们运行推理时,每个矩阵都被加载到内存中。具体来说,每个矩阵的块被加载到设备内存中,即共享内存单元(在A100上只有192KB)。然后,该块用于计算批次中每个元素的结果。需要注意的是,这与GPU RAM(即HBM)不同,A100具有40GB或80GB的HBM,但只有192KB的设备内存。因为我们不断地在设备内存中搬运数据,所以这在执行数学运算时会导致一个内存带宽瓶颈。我们可以通过计算模型大小/内存带宽比来近似传输权重所需的时间,并通过模型FLOPS/GPU FLOPS来近似计算所需的时间。
使用多层感知器(MLP)时,FLOPS(每秒浮点运算次数)约为参数数量的两倍乘以批次中元素的数量(对于批次大小为b和一个m x n矩阵,FLOPS为2 * m * n * b,https://www.stat.cmu.edu/~ryantibs/convexopt-F18/scribes/Lecture_19.pdf)。因此,当
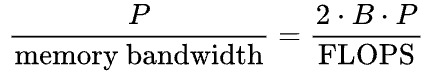
时,传输时间等于计算时间。
注意,我们可以在这里消除参数的数量:
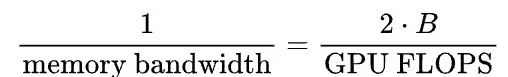
然后,以批次大小为单位重新组织:
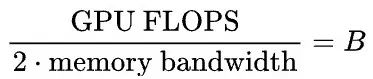
当批大小小于FLOPS与内存带宽之比时,我们会受到内存带宽的限制。当批大小大于该比值时,我们会受到FLOPS的限制。需要注意的是,这种分析是针对MLP而不是卷积网络(例如ResNet50)。对于卷积网络来说,情况会变得更加复杂。
在T4 GPU(https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/tesla-t4/t4-tensor-core-datasheet-951643.pdf)上,我们有65 TFLOPS的fp32性能和300 GB/s的内存带宽,因此魔数比(magic ratio )应该是216。当运行一个MLP(深度:8,宽度:1024)时,我们大致看到了预期结果:
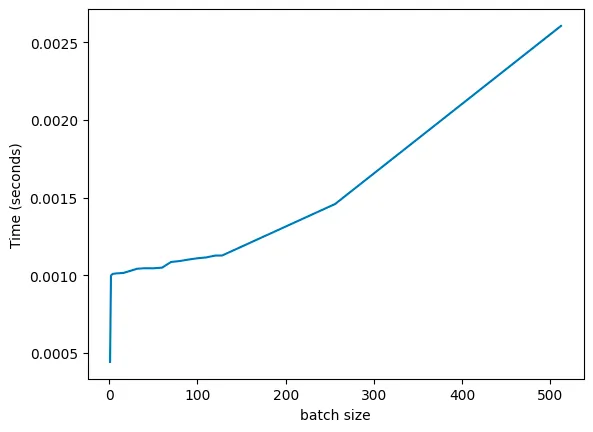
虽然结果里有些噪声,但基本符合我们的预期:推理时间在批大小约为128左右开始显著增加(批次大小每次翻一倍,可以看到批次分别为128、256和512)。如果改变MLP层的宽度,我们会发现这个现象在各种架构中都成立。以下是一个对数-对数图,以便将所有数据都纳入其中。
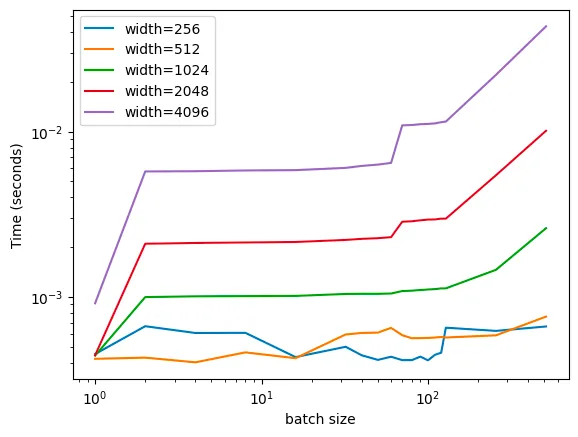
这真的很酷!可以看到,各种不同架构都存在临界阈值。此外,同样有趣的是,较小的网络在整个批大小范围(从1到512)中几乎没有看到任何扩展,花费的时间大致保持不变。我认为,其原因在于:GPU在执行数学计算方面非常快速,但其他方面(例如CPU等)相对较慢。而对于开始阶段的噪声,我还不能给出一个很好的解释,只能简单地将其归因为“计算开销”。
对于很多机器学习工程师而言,他们实际上并没有在机器学习上花太多时间,而是在解决计算开销问题,这些计算开销通常出现在非机器学习代码中。在强化学习研究中,特别是对于研究持续学习问题的研究人员来说,当存在一个单一智能体连续进行大量的动作时,通常不值得使用GPU进行实验,除非满足以下条件之一:1)有非常大的神经网;2)对堆栈的其他方面进行了广泛优化(如果你想让一位资深的DeepMind工程师感到不安,可以问他们关于内置计算图环境的事情——我们曾在TensorFlow计算图内实现强化学习环境)。
那么CNN网络呢?
在卷积网络中,权重等于滤波器数量乘以滤波器大小。对于torch.nn.Conv2d,这相当于kernel_size^2 * out_channels。因此,如果我们有一个(224,224)的图像,步长为1,卷积核大小为3,那么我们会将同一个滤波器应用于图像224次。这意味着,基本上对于卷积层来说,批处理带来的优势要少得多,因为我们多次重复使用相同的权重。对于池化层(pooling layer),计算量基本上是与像素数量成正比,正如你所期望的那样。
那么Transformer呢?
Transformers模型本质上就是多层感知器(MLPs),因此我们可以将它们视为同类。它们具有自注意力机制,但是通过使用键值(KV)缓存(将计算的数据保存在内存中),自注意力所需的时间可以很少。我之前也多次写过有关这方面的内容。
对于混合专家(Mixture of Experts)模型也是如此。在许多Transformer的实现中,键值(KV)缓存位于注意力类的内部(MaxText是一个很好的例子)。由于MoE模型与普通解码器的唯一区别在于一些前馈层被替换为MoE层,因此KV缓存的表现是相同的,推理过程也将如此,但有一个小差异。
MoE层中的门控机制会将批次分配给不同的专家。因此,如果门控机制不能均匀地将批次分配到各个专家中,这可能会导致出现问题。不同的路由机制可以避免这个问题(例如,expert’s choice),但在自回归解码器中,你基本上只能使用token’s choice,这可能会导致门控机制有一些倾向。强制门控机制均匀分配词元是一个活跃的研究领域,并且是训练过程中优化的一个重要目标。
【语言大模型推理最高加速11倍】SiliconLLM是由硅基流动开发的高效、易用、可扩展的LLM推理加速引擎,旨在为用户提供开箱即用的推理加速能力,显著降低大模型部署成本,加速生成式AI产品落地。(技术合作、交流请添加微信:SiliconFlow01)
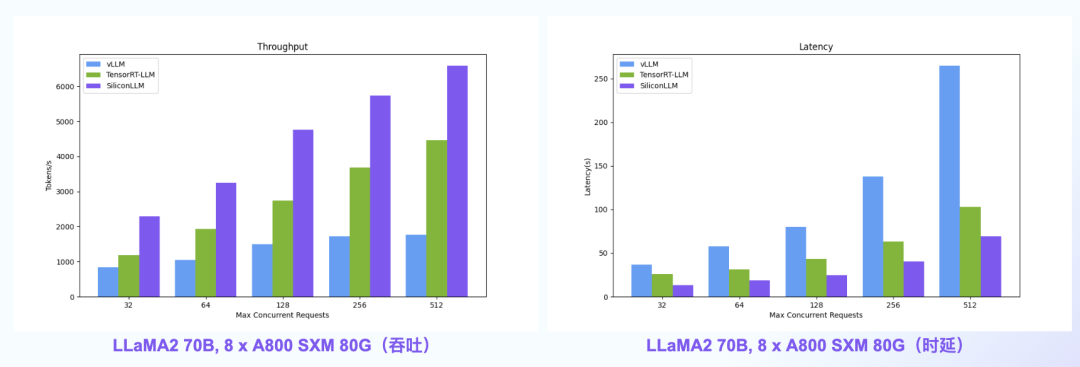
SiliconLLM的吞吐最高提升近4倍,时延最高降低近4倍
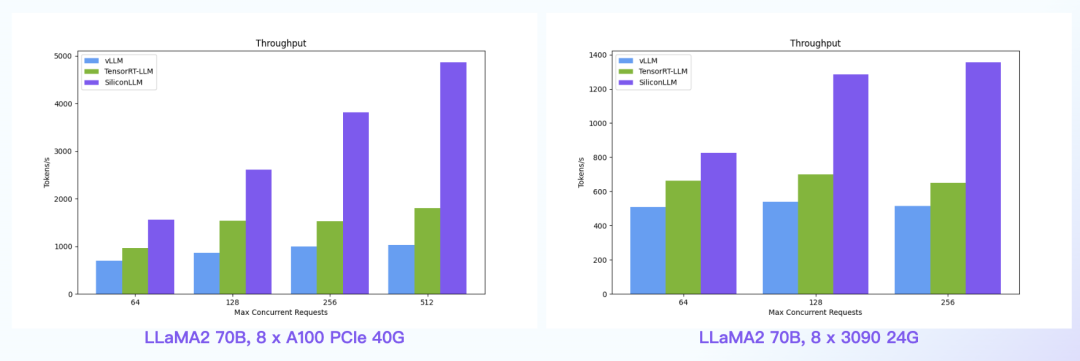
数据中心+PCIe:SiliconLLM的吞吐最高提升近5倍;消费卡场景:SiliconLLM的吞吐最高提升近3倍
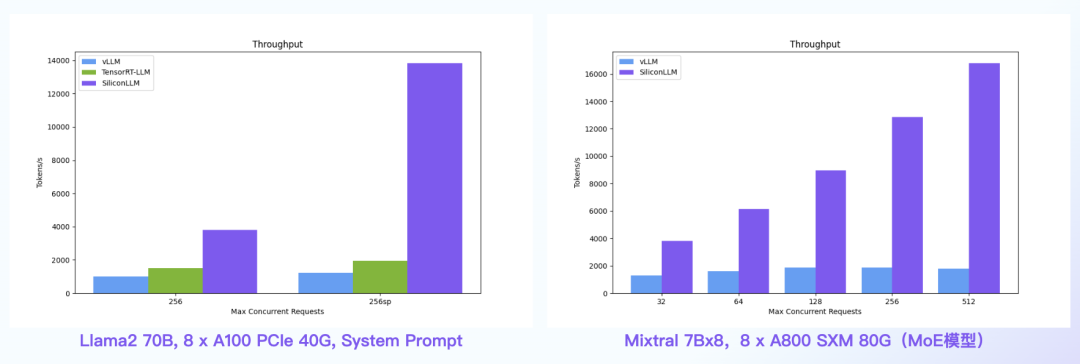
System Prompt场景:SiliconLLM的吞吐最高提升11倍;MoE模型:推理 SiliconLLM的吞吐最高提升近10倍
其他人都在看
















 418
418











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









