








作者 | Lilian Weng
OneFlow编译
翻译|杨婷、宛子琳、张雪聃
题图由SiliconFlow MaaS平台生成
过去几年,扩散模型(Diffusion models)在图像合成领域取得了显著成效。目前,研究界已开始尝试更具挑战性的任务——将该技术用于视频生成。视频生成任务是图像生成的扩展,因为视频本质上是一系列连续的图像帧。相较于单一的图像生成,视频生成的难度更大,原因如下:
它要求在时间轴上各帧之间保持时间一致性,这自然意味着需要将更多的世界知识嵌入到模型中。
相较于文本或图像,收集大量高质量、高维度的视频数据难度更大,更不用说要获取文本与视频的配对数据了。
阅读要求:在继续阅读本文之前,请确保你已经阅读了之前发布的关于图像生成的“什么是扩散模型?(https://lilianweng.github.io/posts/2021-07-11-diffusion-models/)”一文。(本文作者Lilian Weng是OpenAI的AI安全与对齐负责人。本文由OneFlow编译发布,转载请联系授权。原文:https://lilianweng.github.io/posts/2024-04-12-diffusion-video/)
1
从零开始的视频生成建模
首先,我们来回顾一下从头开始设计和训练扩散视频模型的方法,这里的“从头开始”指的是我们不依赖预训练的图像生成器。
参数化与采样基础
在前一篇文章的基础上,我们对变量的定义稍作调整,但数学原理依旧不变。假设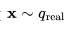 是从真实数据分布中采样的数据点。现在,我们逐步向其引入少量的高斯噪声,形成一系列x的噪声变量
是从真实数据分布中采样的数据点。现在,我们逐步向其引入少量的高斯噪声,形成一系列x的噪声变量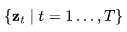 ,随着t 的增长,噪声量逐渐增大,直至最终形成
,随着t 的增长,噪声量逐渐增大,直至最终形成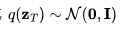 。这一逐步添加噪声的前向过程遵循高斯过程。此外,我们用
。这一逐步添加噪声的前向过程遵循高斯过程。此外,我们用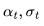 来表示高斯过程的一个可微分的噪声调度(noise schedule):
来表示高斯过程的一个可微分的噪声调度(noise schedule):
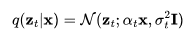
将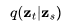 表示为
表示为 ,需要以下操作:
,需要以下操作:
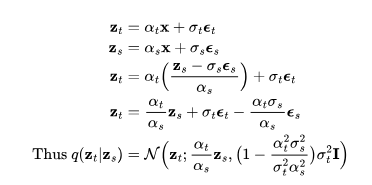
设对数信噪比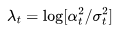 ,我们可以将DDIM(宋等人,2020年)更新表示为:
,我们可以将DDIM(宋等人,2020年)更新表示为:
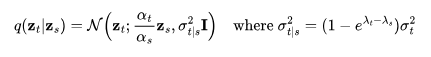
由Salimans和Ho(2022年)提出的v预测 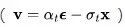 参数化,特别适用于在视频生成中避免色彩偏移,相比
参数化,特别适用于在视频生成中避免色彩偏移,相比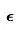 参数化,其效果更佳。
参数化,其效果更佳。
v参数化采用了角坐标系中的一个巧妙技巧进行推导。首先,我们定义 ,然后得到
,然后得到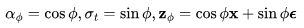 ,
,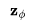 的速率可以表示为:
的速率可以表示为:
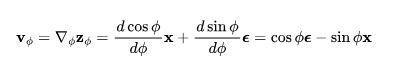
然后可以推导出:
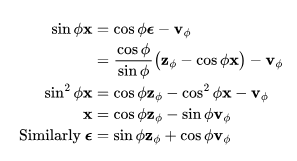
相应地,DDIM更新规则为:
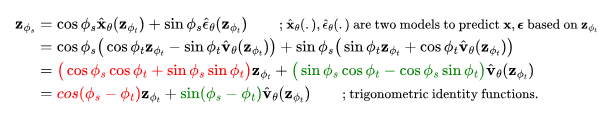
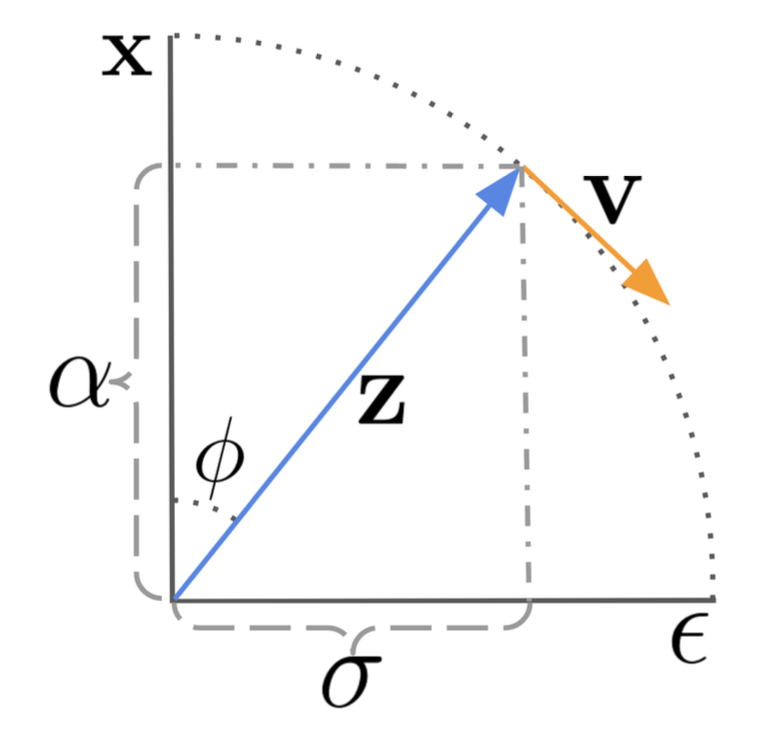
图1:扩散更新步数在角坐标中的工作原理,其中,DDIM沿着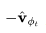 方向移动
方向移动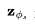 来进行演化。(图源:Salimans和Ho,2022)
来进行演化。(图源:Salimans和Ho,2022)
模型的v参数化是为了预测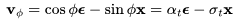 。
。
在视频生成中,我们需要扩散模型运行多个上采样步数,以延长视频长度或提高帧率。这要求模型具备根据第一个视频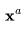 采样第二个视频
采样第二个视频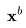 的能力,
的能力,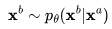 ,其
,其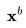 可能是
可能是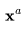 的自回归扩展,或者是低帧率视频
的自回归扩展,或者是低帧率视频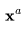 中的缺失帧。
中的缺失帧。
采样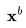 时,不仅要依赖其自身的噪声变量,还需要考虑视频
时,不仅要依赖其自身的噪声变量,还需要考虑视频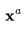 。视频扩散模型(VDM;Ho和Salimans等人,2022年)提出了一种重建引导(reconstruction guidance)方法,使用调整后的去噪模型,确保视频
。视频扩散模型(VDM;Ho和Salimans等人,2022年)提出了一种重建引导(reconstruction guidance)方法,使用调整后的去噪模型,确保视频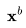 的采样能够恰当地考虑
的采样能够恰当地考虑
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 18
18

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









