






近期,国产大模型DeepSeek R1-67B的推理成本引发热议——官方定价16元/百万token,究竟亏不亏?
有分析认为成本可低至4元,也有实测显示高达150元。这背后是算力、通信、显存优化的复杂博弈。本文将用“人话”拆解技术内幕,带你看懂大模型推理的降本逻辑。

分析:
以及之前传播很广的关于4090 做LLM推理的分析:
https://www.zhihu.com/question/615946801/answer/3205148871
为了理解怎么搞才是高性能的模型部署,我们首先要能找到瓶颈在哪里, 或者从优化的角度看就是找到目标函数的限制条件。(以下讨论都不涉及量化等操作)
背景知识
先简单的了解一下Roofline分析,
更深入的理解可以参考文章Roofline


Roofline分析大体上讲主要分析的是到底通信(显存带宽,多卡互联)是瓶颈,还是算力是瓶颈。 在大语言模型的场景下还有一个限制条件没有考虑,就是kvcache 占用的空间大小。
DeepSeek V3 模型结构
MoE概念的理解可以参考 MoE 模型训练
关于DeepSeek 模型结构的解读可以参考DeepSeek V3 模型结构解读
参考 A Mathematical Framework for Transformer Circuits 我们可以把Transformer看作一个残差流

然后结合DeepSeek的论文来看它的架构调整
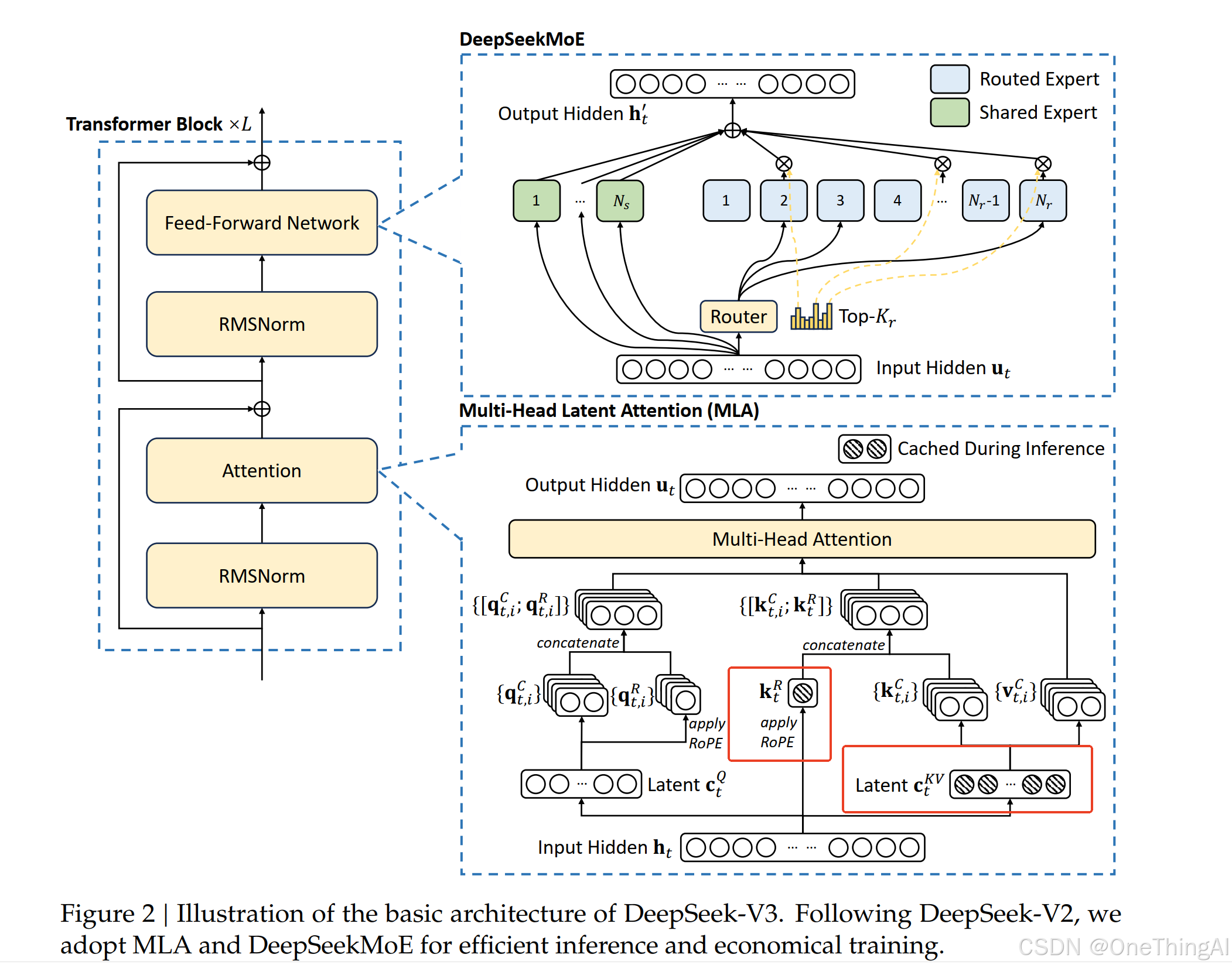
DeepSeek 对Attention和MLP做了替换。
如上图 Attention 层对K,V做了压缩(为什么能压缩,有什么风险),kvcache时只需要存上图红框里的2个部分(更多细节可以参考论文)以此降低kvcache的大小,所以 2 里计算

我们这里要做一些修正 k v 按BF16 存储,每个输出长度按1w token计算,那么就只要batch size 113就能占完卡的显存(算力,通信外的另一个限制)。
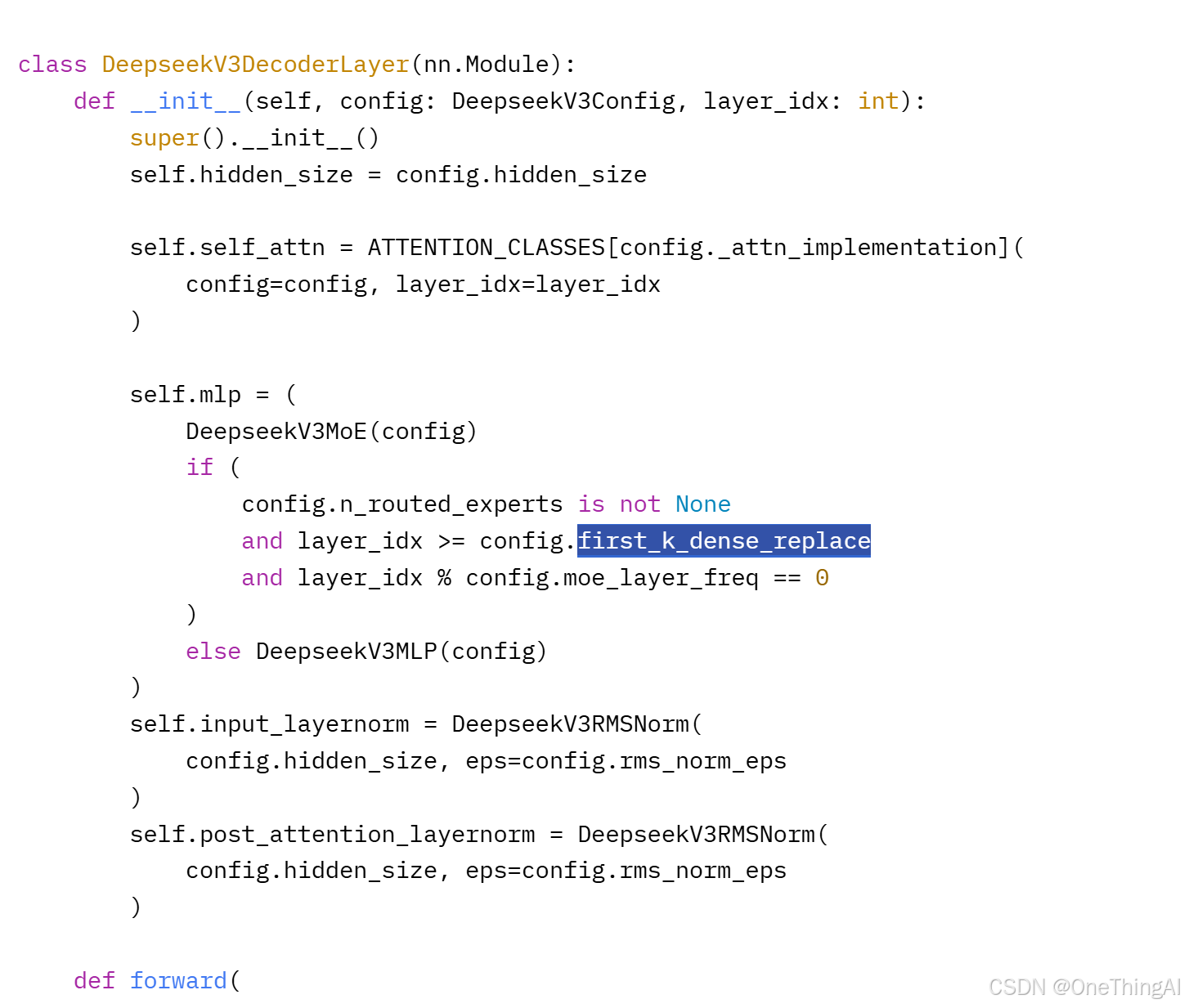
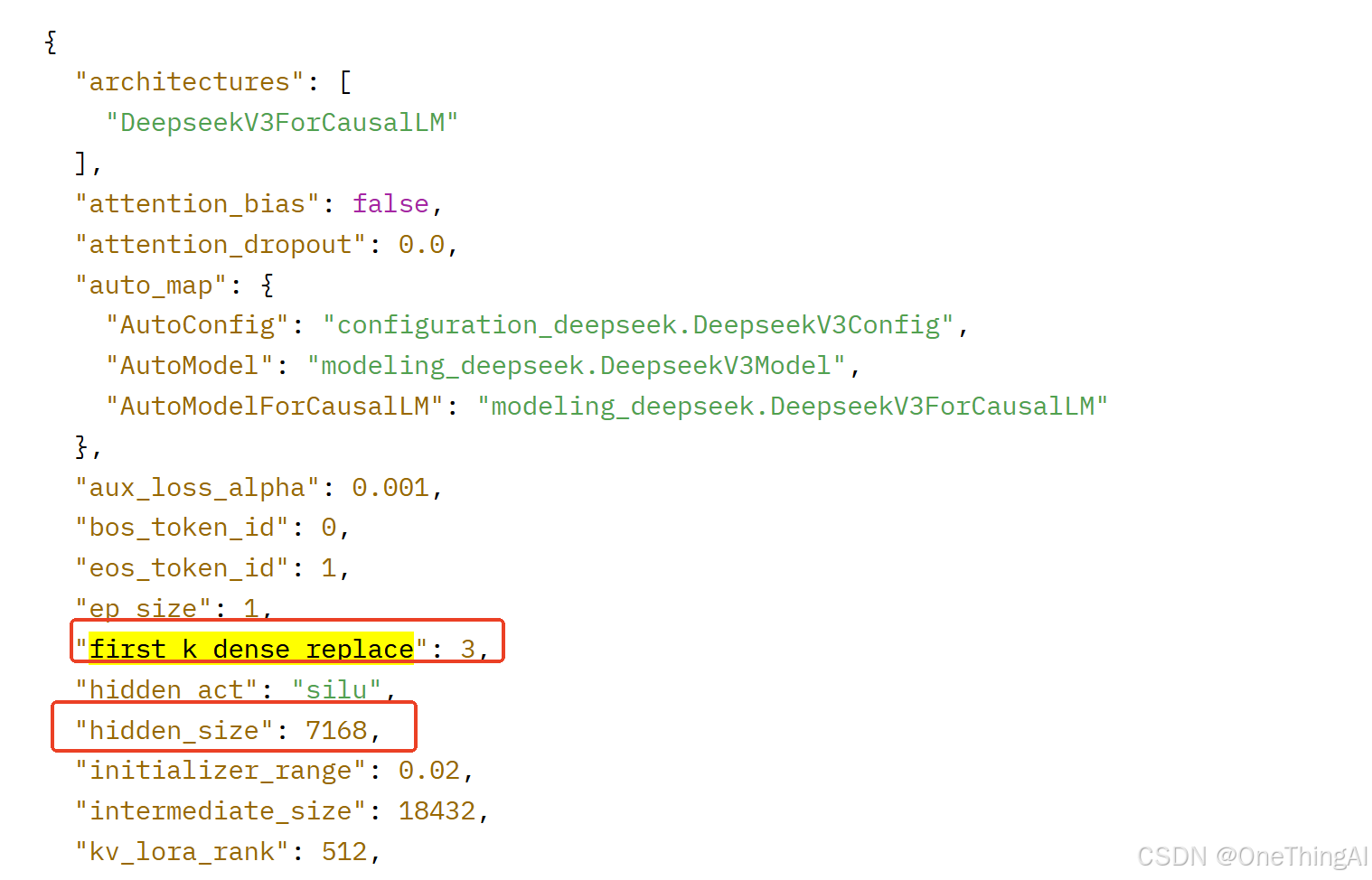
针对MLP替换成了DeepSeekMoE。 在V3 模型61层中前3层还是MLP(模型很深,梯度下降的算法在往后的层从训练数据中得到的特征会少,导致MLP里linear layer天然是低秩的)。细节可以参考下面的代码和配置文件。

总结
1,1-5 篇文章中1,2 估算了EP320 这种部署,到底能可以支持多大的并发。1 认为瓶颈在通信这个判断单台和8卡H100支持600左右的并发请求是很合理的。 因为首先H100 FP16 989TFLOPs的算力,FP8 等于989 * 2,以989 T来做Arithmetic intensity的预估也就是295 FLOPs/byte,大体可以理解为只要单卡batch size 不大于295则算力不是瓶颈。我们回来计算成本,假设单卡按2的预估支持40并发请求,每个请求每秒32 token 做为lower bound, 按道理应该并发数应该高于这个值。 那么按H100 每小时2美元,成本确实不到4块, 16 块钱百万token有利润。API业务能不能赚钱核心问题就转化为跑满率的问题了。(如果低峰期跑不满怎么办呢,是不是可以进一步把算力调度来做RL训练)
2,关于百万token 成本150块,直接见下图

比如5里的测试,效果比上图的结果更差。 为什么2台设备的小集群部署效果是这样呢,batch size 再开大一些,单个用户每秒30tokens/s就无法满足了吗?
1,对于700GB 这么大的模型Prefill就会占用大量的浮点算力资源和显存带宽;


通信的压力, sglang 针对deepseek v3 本身并没有优化到最佳等导致目前小集群的整体吞吐还比较低。虽然小集群的性价比方面的上限肯定低于PD分离的EP320 这种部署方案,但是当数据安全是一个约束项时,不得不做小集群部署。
无论sglang还是vllm 针对deepseek v3 都还有很大的优化空间,150/百万token 再优化一个数量级,应该是可实现的。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









