






一、技术背景与核心优势
在 AI 多模态技术爆发的今天,如何让静态图片 “开口说话” 成为热门课题。腾讯开源的 Sonic 模型通过图像 + 音频驱动数字人视频生成,而 ComfyUI 作为节点式工作流工具,能将这一过程简化为可视化操作。两者结合后,开发者只需 3 步即可实现:
- 上传人物照片:支持正面 / 侧面高清肖像
- 输入语音文件:支持 WAV/MP3 等格式
- 一键生成视频:自动匹配口型与动作
ComfyUI + 腾讯 Sonic 节点实战,让图片说话
二、环境搭建与模型准备
(本地部署可以参考其他资料)
1. 云平台部署
- 快速创建实例:登录控制台,选择ComfyUI 官方镜像,如果配置 RTX 4090 显卡,实测生成一分钟的视频需要20分钟左右。
- 官网链接:OneThingAI算力云 - 热门GPU算力平台
2. 模型&节点:需要下载Sonic模型安装到对应文件夹
-
关键模型说明:
模型名称 功能描述 下载地址 unet.pth 核心生成网络 Sonic仓库 yoloface_v5m.pt 人脸检测模型 LeonJoe13/Sonic 仓库 svd_xt_1_1.safetensors 动态视频扩散模型 hugging face
sonic模型发布地址:https://github.com/smthemex/ComfyUI_Sonic
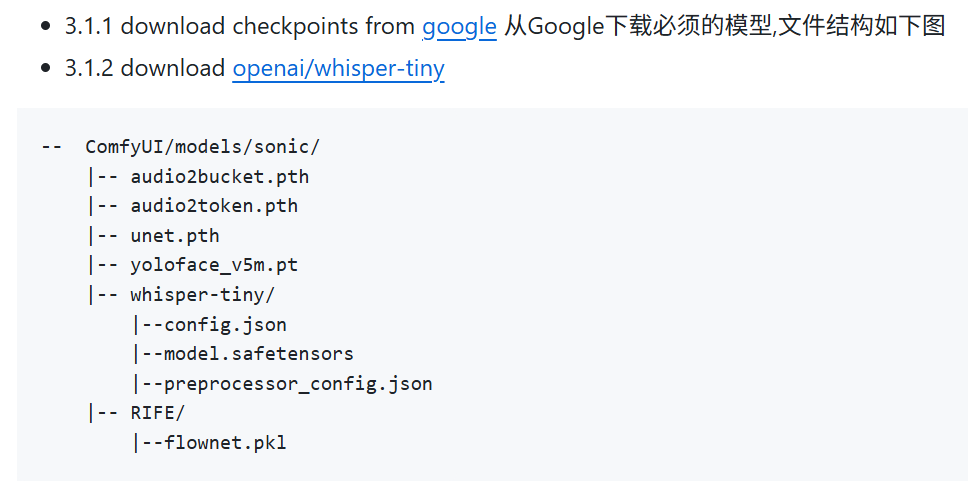
sonic模型中需要下载模型文件链接如下:
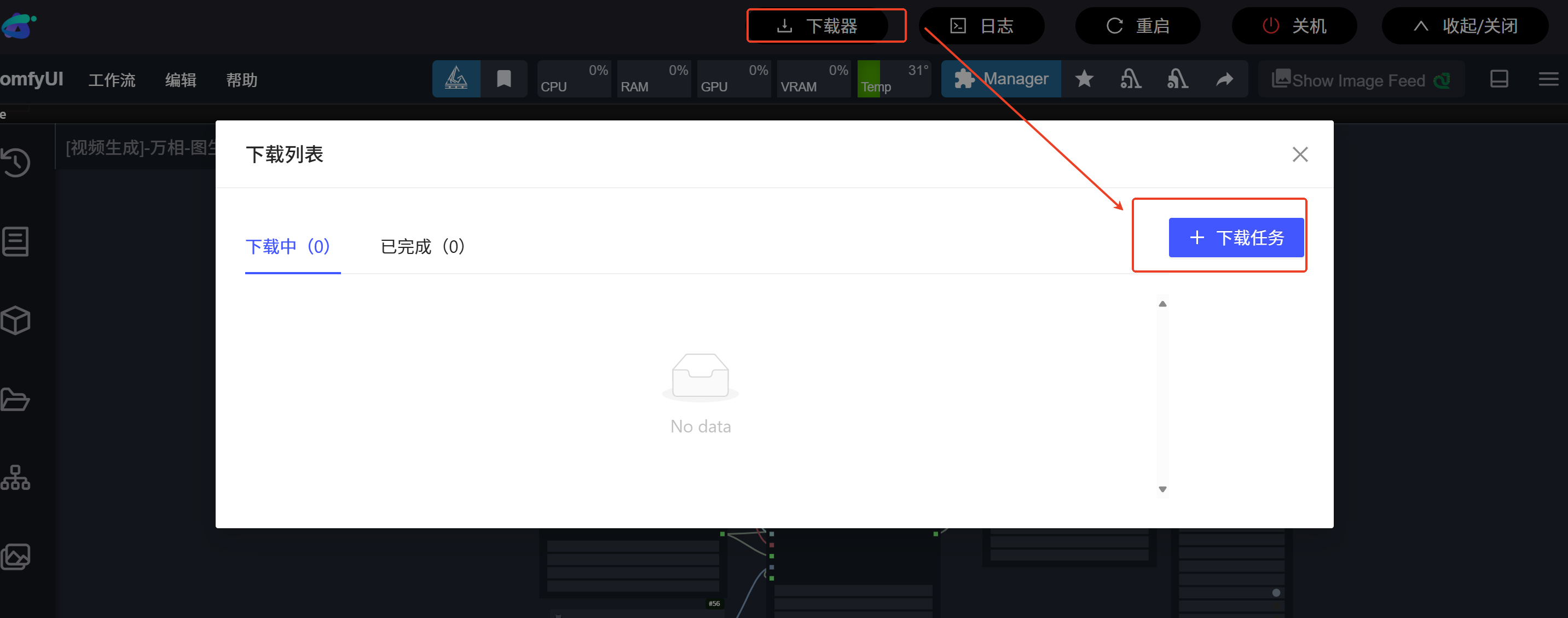
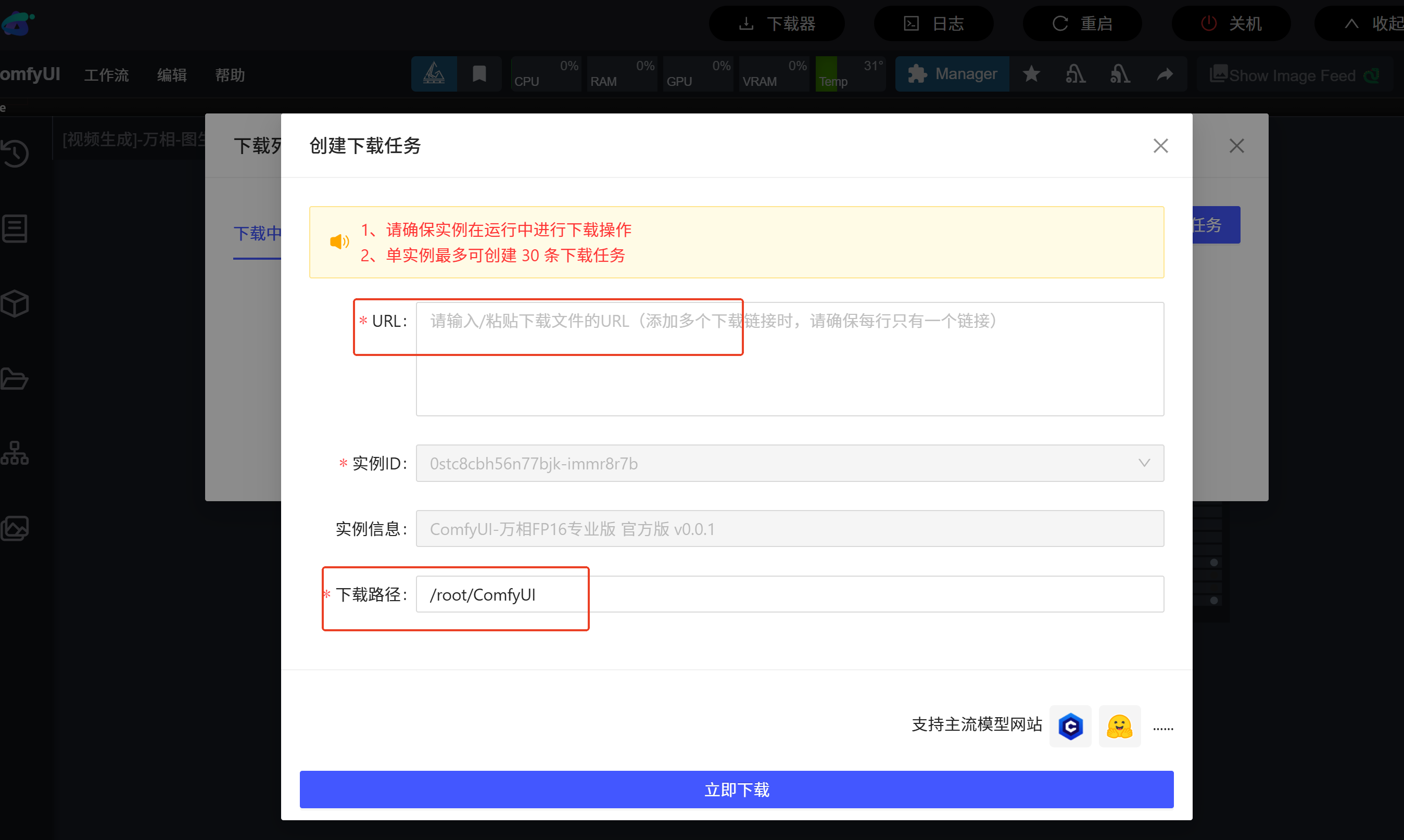
svd模型下载到:/root/ComfyUI/models/checkpoints/
(以上都可以通过comfyui镜像中的下载器直接下载)
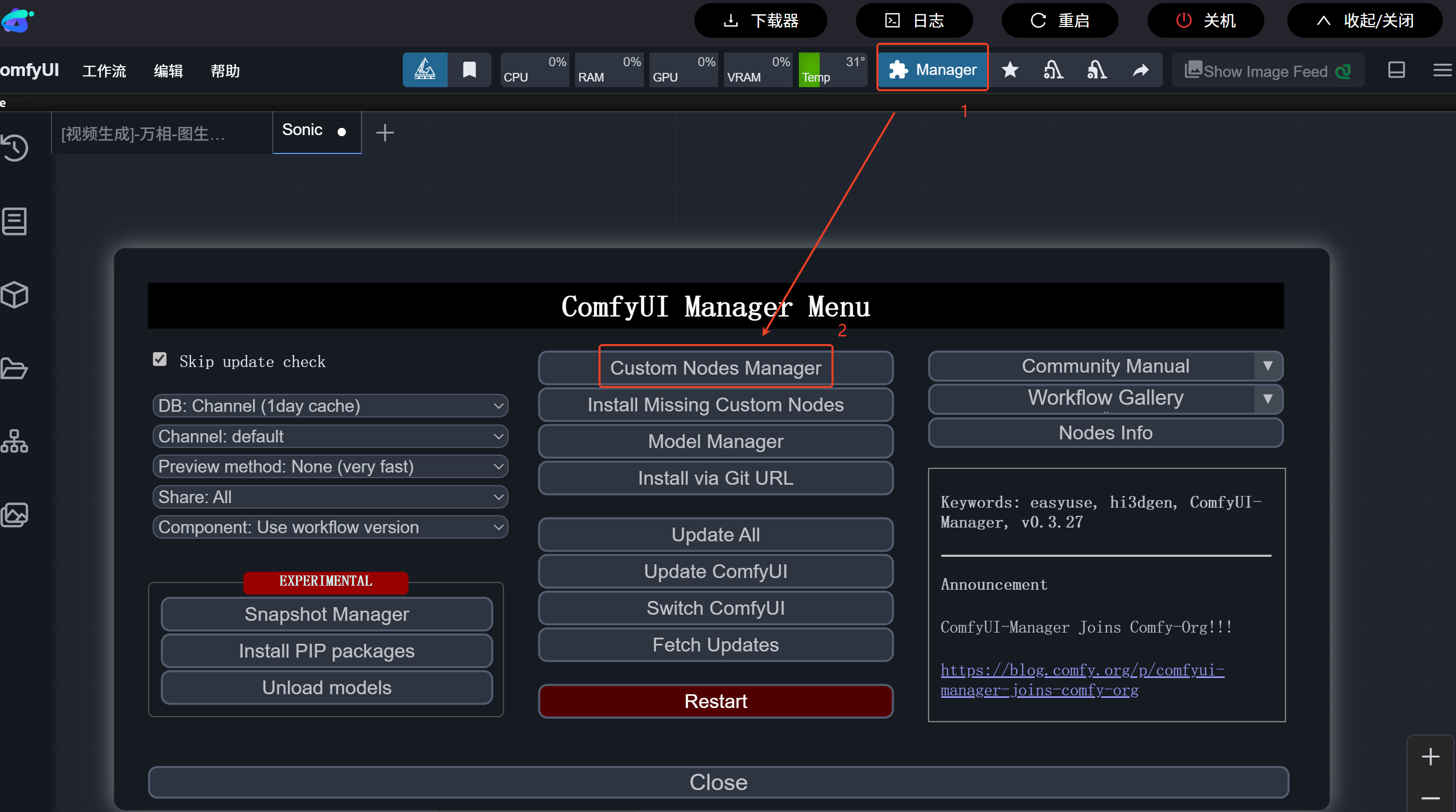
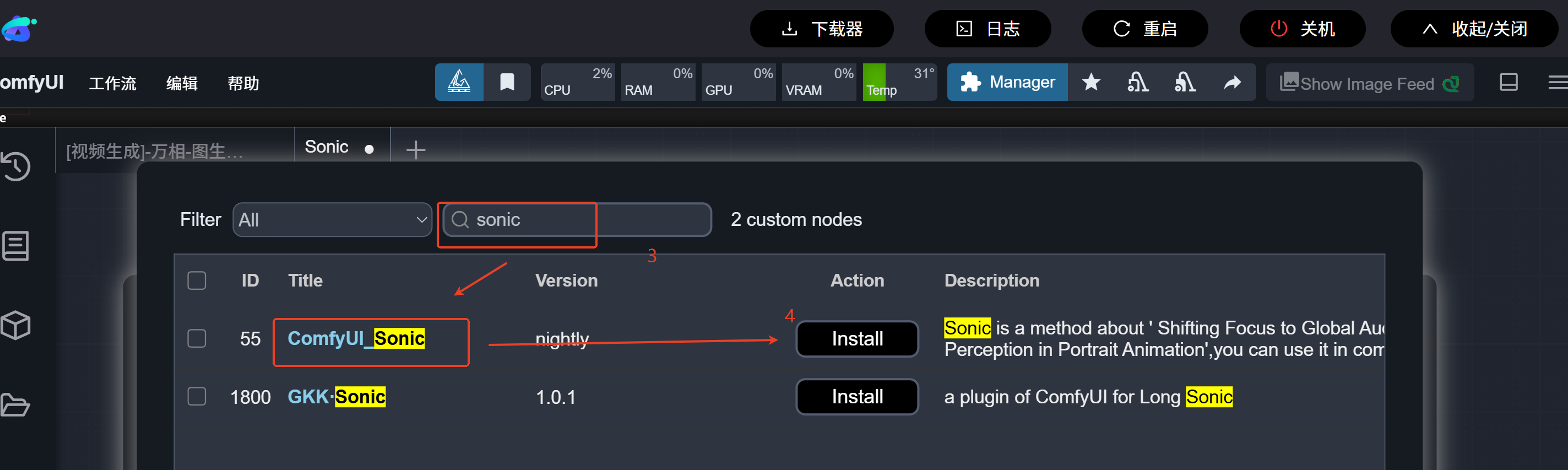
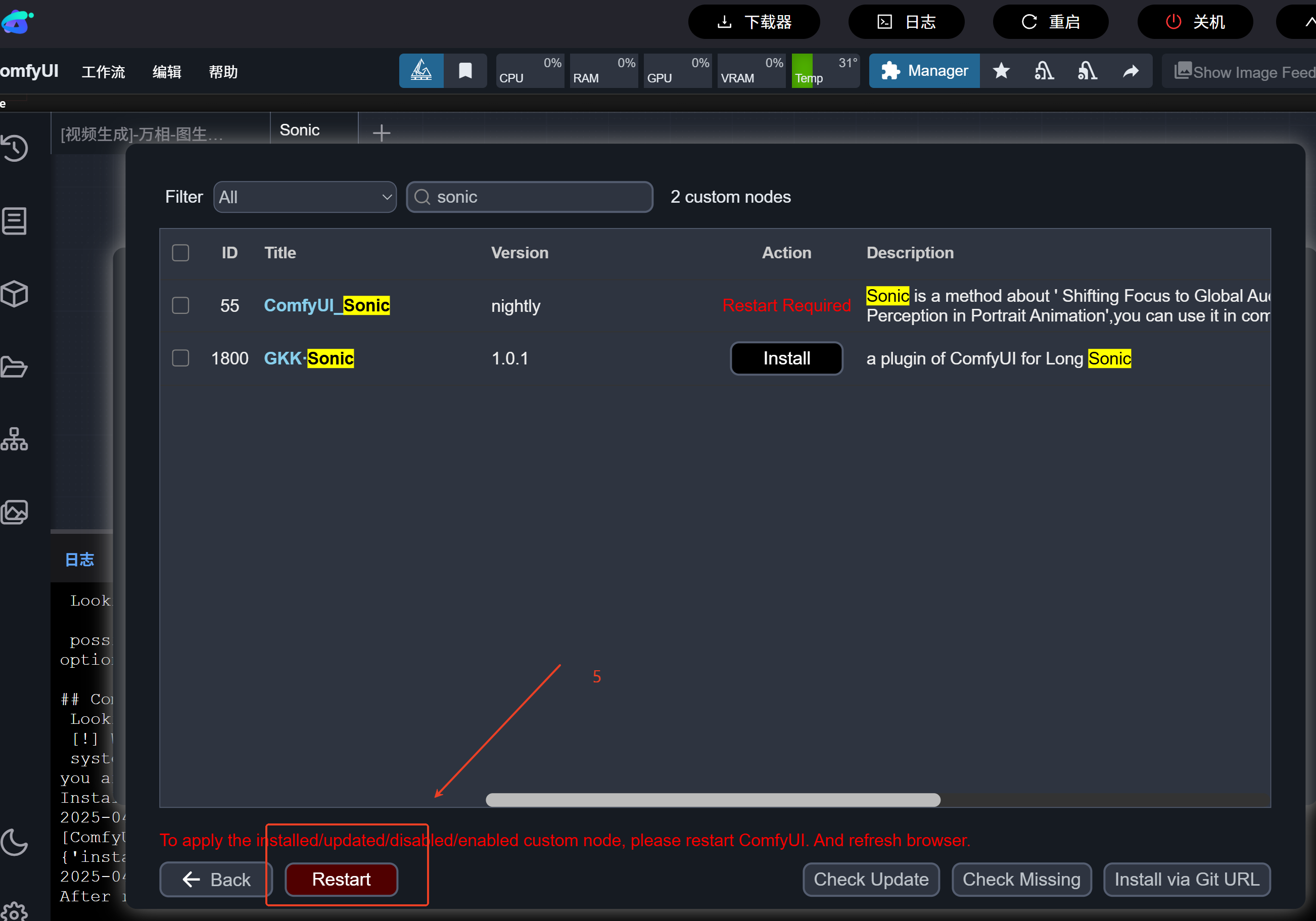
sonic节点下载步骤:
在comfyui管理器→节点管理→搜索sonic→下载相关节点→下载完成后点击【重启】实例
三、工作流搭建与参数调整
1.工作流
上传图片和音频即可生成视频
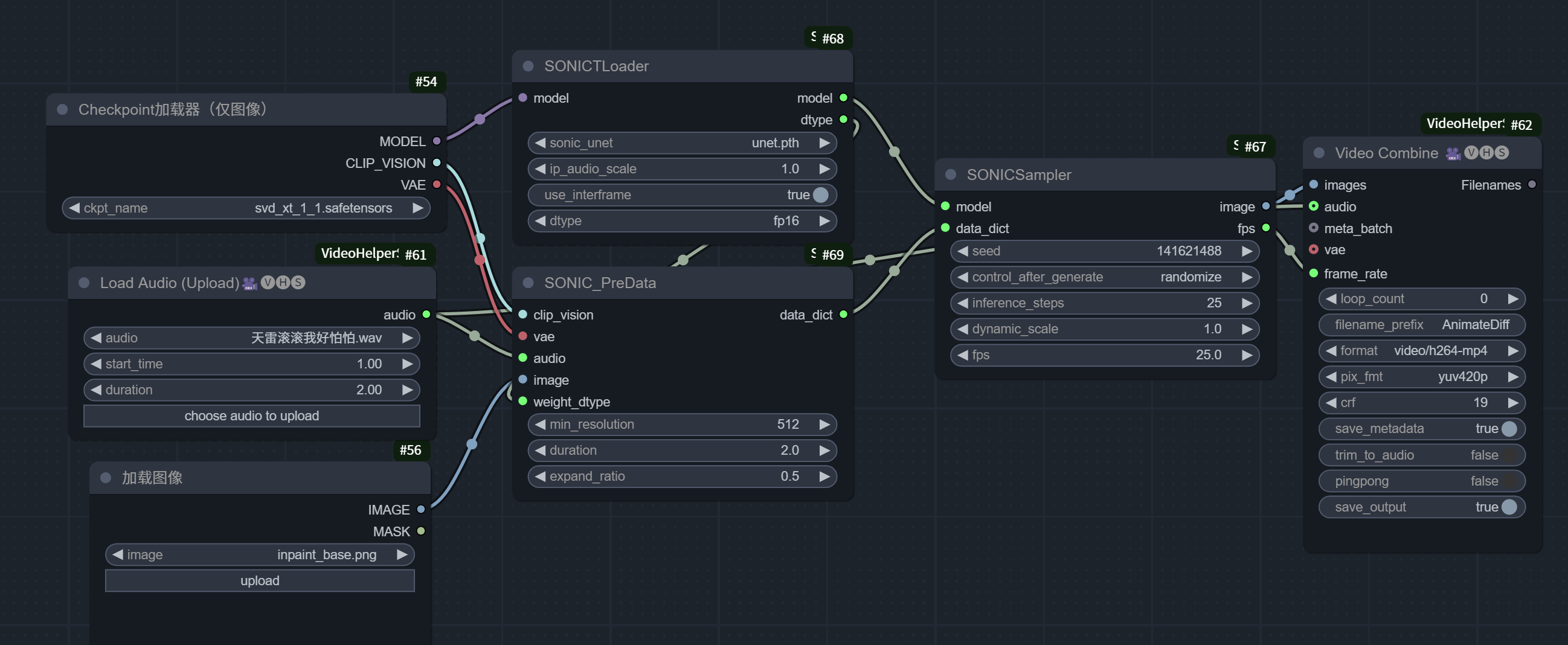
2. 关键参数详解
| 参数名称 | 取值范围 | 作用说明 |
|---|---|---|
| duration | 1-600 秒 | 控制视频总时长 |
| min_resolution | 384-1024 | 调整视频最短边分辨率 |
| motion_scale | 0.5-2.0 | 控制数字人动作幅度 |
| face_padding | 0-0.3 | 人脸裁剪留白比例 |
通过 ComfyUI 与 Sonic 的结合,我们实现了从静态图片到动态数字人的全流程自动化。
本文配套资源:
- 工作流 JSON 文件
- 模型文件下载
关注作者获取完整资料,让我们一起探索 AI 多模态的无限可能!

















 611
611

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









