







文章目录
Show, Attend and Read: A Simple and Strong Baseline for Irregular Text Recognition
基本信息
- 论文链接:arxiv
- 发表时间:2019 - AAAI
- 应用场景:自然场景文字识别
摘要
| 存在什么问题 | 解决了什么问题 |
|---|---|
| 1. 非规则自然场景文字大都具有弯曲、方向不定以及变形等特点,导致难以识别。先前的方法大都采取了多模型混合或者字符级别标注来解决这些问题,这无疑是增大了算法实现难度与数据搜集的难度。 2. 现有的解决方案可归类为三种:a:rectification based(大曲率弯折下矫正模块表现不佳)。b:attention-based 之前的SOTA方法需要字符集标注。c:multi-direction encoding based 模型复杂。 | 1. 提出了一个仅用word粒度标注信息就能对非规则自然场景文字进行准确识别的简单易实现模型SAR。仅用合成数据进行训练就能在全部irregular dataset上达到SOTA。 |
模型结构
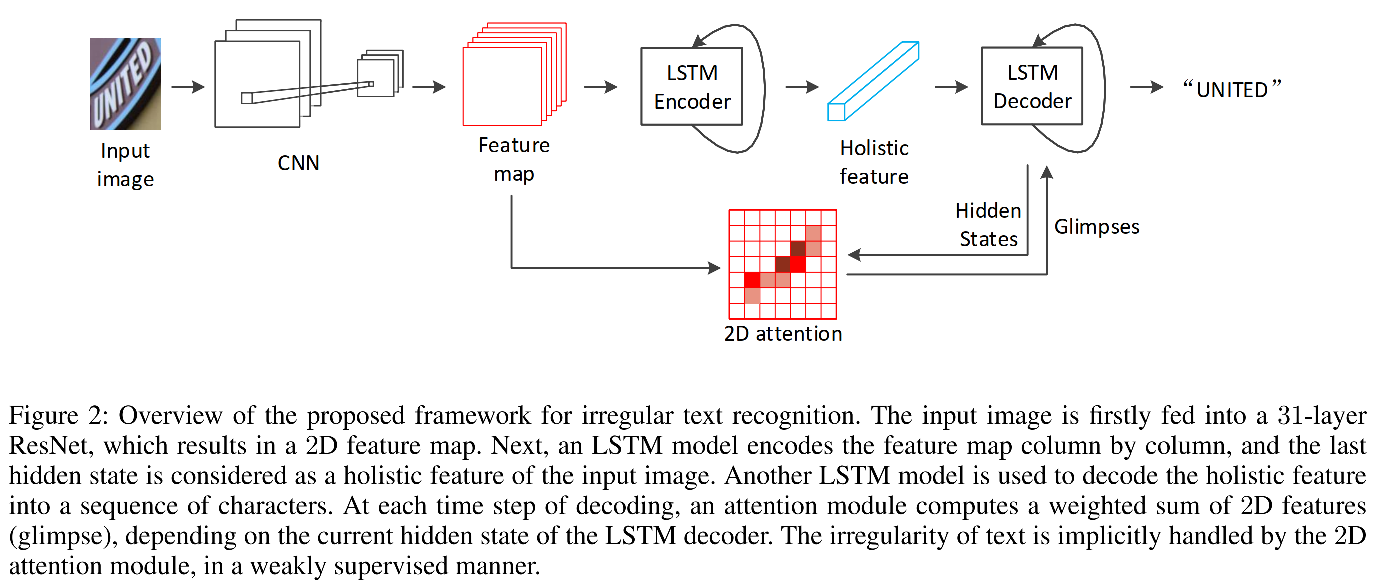
ResNet CNN
同于对图片的特征抽取。
Reize方法:高度固定,宽度随比例缩放,作者这里将resize后的高度设为48.

基础结构采用Resnet中的Basic Block结构。
卷积操作都不改变大小,只有池化会对图像进行降采样。高度上降采样4倍,宽度上降采样8倍。得到2d feature map(后续称作F,shape=[h,w,c])。宽度上保留了更多信息,更利于窄字符(i,l等)的识别。
F后续会被用来提取抽取holisitc feature以及作为2d attention network的context。
2D Attention based Encoder-Decoder
Encoder
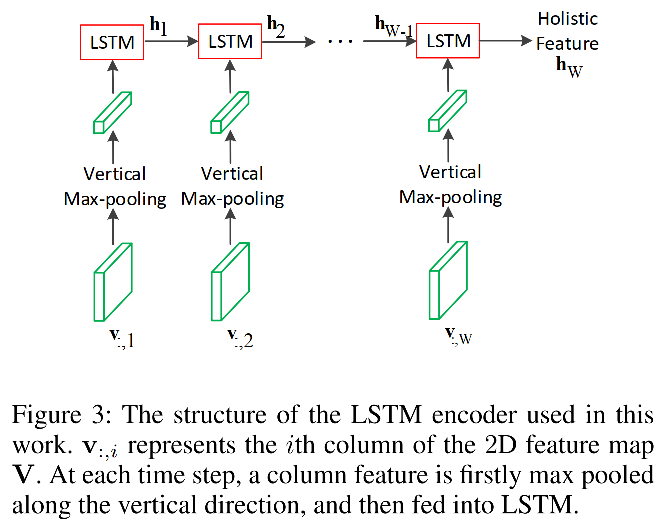
由两个堆叠(stacked)的LSTM组成。
基于F,在高度方向做max pooling,得到[w,c],以w作为序列长度,送入LSTM(不知道是单向还是双向的,得看代码)中,从第二个LSTM cell得到最终状态输出 h w h_w hw,称为holistic feature。
Decoder
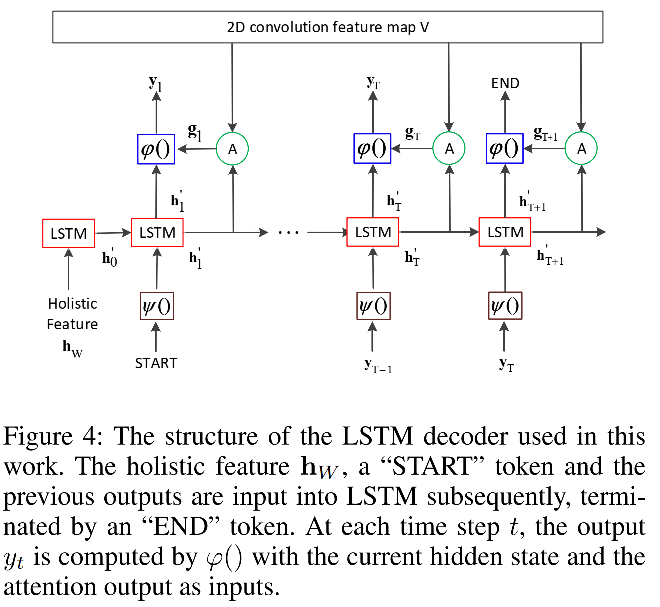
由两个堆叠(stacked)的LSTM组成,但是参数不和encoder共享。
首先将holistic feature输入给decoder中,起到初始化decoder的作用。然后是<start> token,将该阶段LSTM输出的hidden state和attention module输出的 g t g_t gtconcat并通过全连接层映射到字符空间,那么下一步的输入就是当前预测的字符(训练状态下是teach forcing模式)的embedding,以此类推。直到预测出<eos> token或者到最大解码长度。
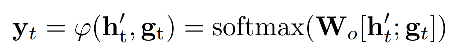
2D Attention
目的是为了得到 g t g_t gt。
其输入有:feature map(V)、上一个step解码时的hidden state( h t ′ h^{'}_t ht′)。
具体运算如下:
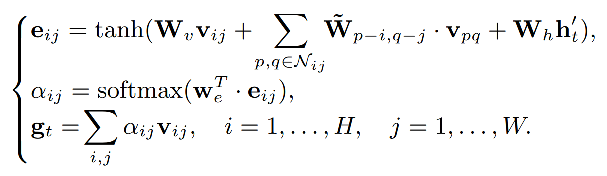
从公式上能够看出query是上一个step的lstm hidden state,key和value都是feature map。
W v , W ~ , W h , W e T W_v,\tilde{W},W_h,W^T_e Wv,W~,Wh,WeT是可学习权重。
v i j v_{ij} vij代表feature map上某一点, N i j N_{ij} Nij代表 v i j v_{ij} vij的八邻域,那么 e i j e_{ij} eij的计算可以通过对feature map的卷积以及对上一步LSTM输出的hidden state的线性变换(作者用的1d卷积)的加和再做tanh非线性激活得到。
α i j \alpha_{ij} αij通过对 e i j e_{ij} eij的一次卷积(输出channel=1)以及一个softmax后获取feature map上每个点的权重。
最后 g t g_t gt通过 α i j \alpha_{ij} αij和feature map的加权求和得到,代表当前step对encoder hidden states的自适应加权平均。
作者也给出了 g t g_t gt比较详细计算pipeline:
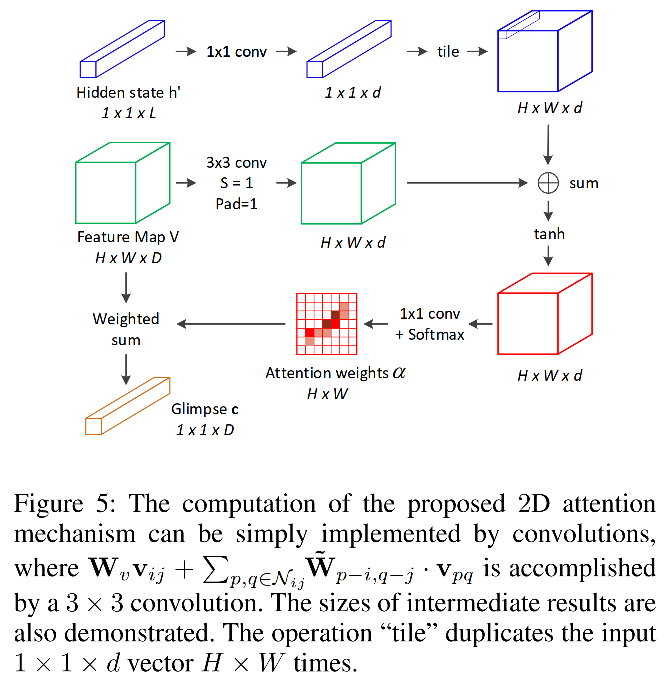
之所以叫tailored 2D attention是因为这里考虑每个像素的邻居像素(不就是加了卷积嘛…),之前的2D attention模块是独立对待这些位置的。
实验
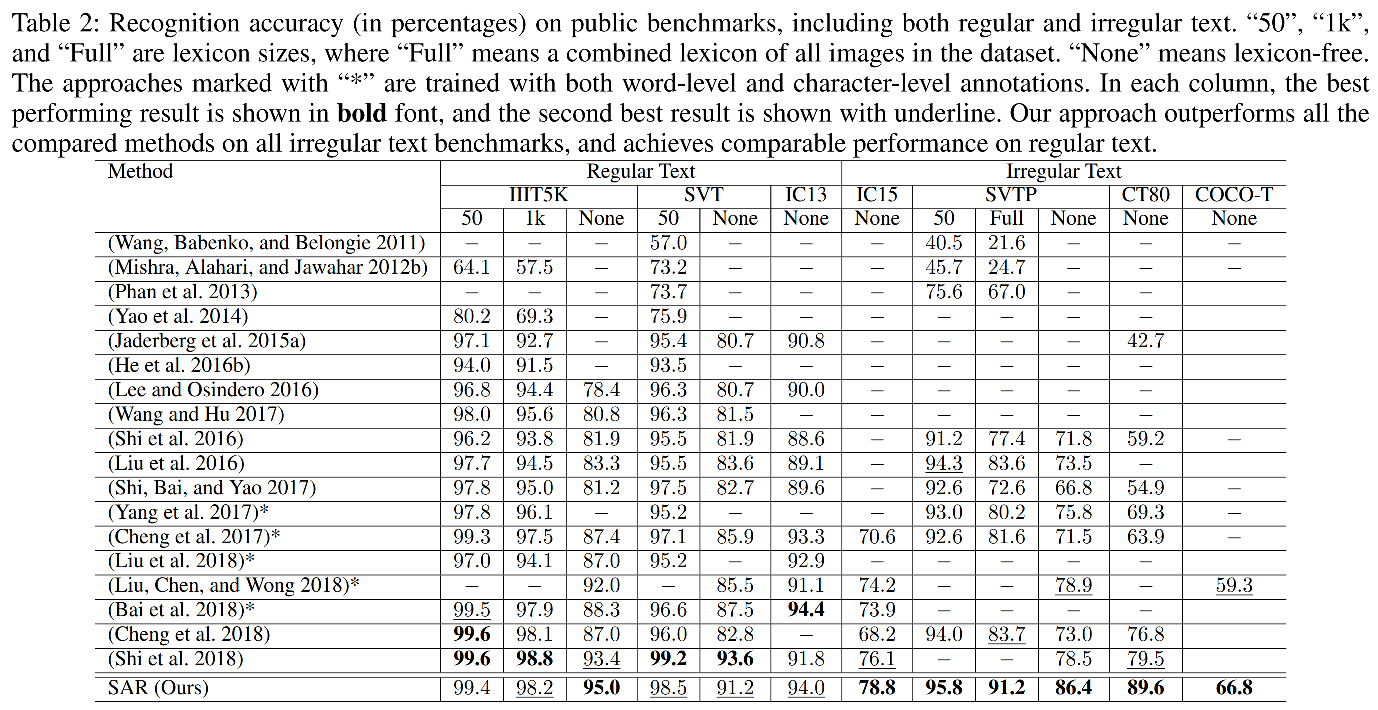
irregular dataset上精度SOTA,regular dataset上精度可比。
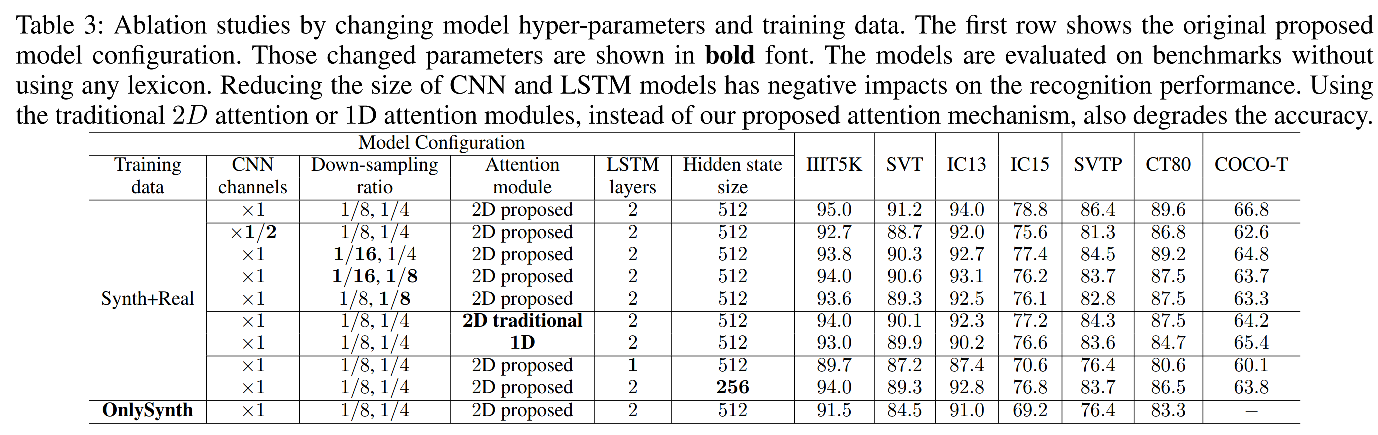
CNN上的消融实验,验证了CNN通道数减半以及降采样倍率增加都会掉点,所以对于2d attention模型,要保证一个足够大的feature map。
attention module上的消融实验,验证了所提出的tailored 2d attention是最优的,不论是常规的2d attention(不带邻域信息融合)还是1d attention,都不及tailored 2d attention方法。
LSTM上的消融实验,LSTM cell从2变成1掉点严重,隐藏层维度从512变为256也对会掉点。所以LSTM的层数是保证一个强有力识别效果的关键。
总结
- 提出了一个基于2D attention方法的识别模型SAR,该模型可以实现在只有word level标注信息的情况下解决大多数自然场景文字识别中的多方向、旋转、扭曲等复杂场景下识别精度不高的难题。提出了新型2d attention模块,即tailored 2d attention。模型结构简单,效果好,在所有irregular数据集上取得SOTA。
- 模型推导的时候采取了多方向翻转识别策略以及beam search(有0.5%的提升)。
- 解码不能并行,速度慢。















 2078
2078











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









