




 本文介绍了一种名为Primitive Representation Learning for Scene Text Recognition (PREN)的方法,它通过Pool和Weighted Aggregator学习文本特征,结合GCN增强视觉表达,有效解决多方向场景下识别难题。PREN2D将此技术融入注意力模型,提升识别准确性和速度,达到SOTA。
本文介绍了一种名为Primitive Representation Learning for Scene Text Recognition (PREN)的方法,它通过Pool和Weighted Aggregator学习文本特征,结合GCN增强视觉表达,有效解决多方向场景下识别难题。PREN2D将此技术融入注意力模型,提升识别准确性和速度,达到SOTA。
文章目录
Primitive Representation Learning for Scene Text Recognition(PREN)
基本信息
- 论文链接:arxiv
- 发表时间:2021 - CVPR
- 应用场景:自然场景文字识别
摘要
| 存在什么问题 | 解决了什么问题 |
|---|---|
| 1. 在多方向场景文本上,先前的识别方法没有充分探索稳定且高效的特征表达,进而导致识别效果不够好。 | 1. 为了挖掘场景文字的内在特征表达,通过两种算子:pooling aggregator和weighted aggregator去学习文本的更高层的原始特征。然后将原始特征通过GCN映射回视觉表达空间,从而达到了强化视觉特征的目的,增强模型在多方向文本图片上的识别能力,即PREN。 2. 所提出的pipeline迁移能力强,可以迁移到2d-attention-based的识别模型上,即PREN2D。达到了强化visual-text特征对齐的效果,最终提升识别准确率。 3. PREN在速度和精度上取得了良好的平衡,PREN2D则达到了SOTA。 |
模型结构
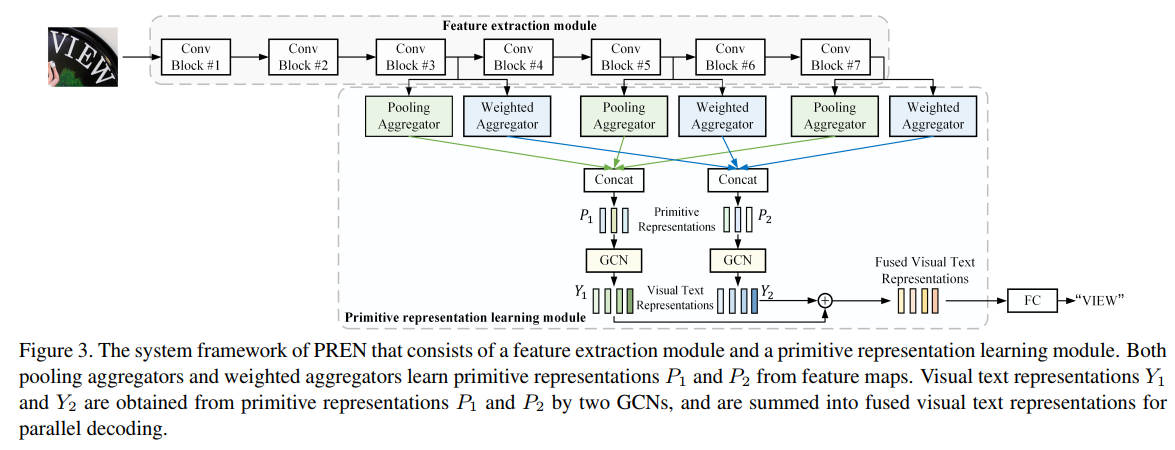
Primitive representation learning
预先设定要学习的primitive vector的个数:n(根据经验人为设定,作者这里取为5),设计两种算子:Pooling aggregator和Weighted aggregator分别从feature map上学习各自的primitive vector,假设vector的维度为d,那么primitive feature的shape=[n,d]。
Pooling aggregator
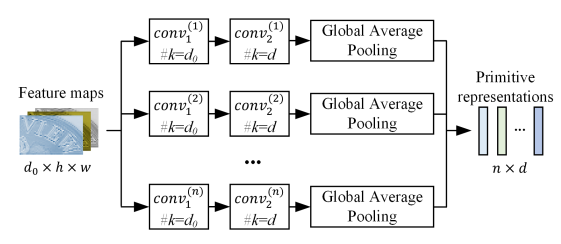
该算子的目的是为了学习全局信息。
该算子有n个分支,每个分支上包含三个操作:连续的两个conv(k=3, s=2,两个conv间有一个非线性激活函数)和global average pooling,得到一个shape=[d]的向量,由于有n个分支,将它们拼接后即可得到一个shape=[n,d]的原始特征表达。
每个分支对应的具体操作如下:
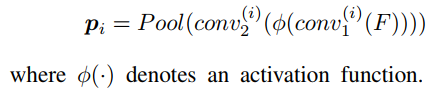
Weighted aggregator
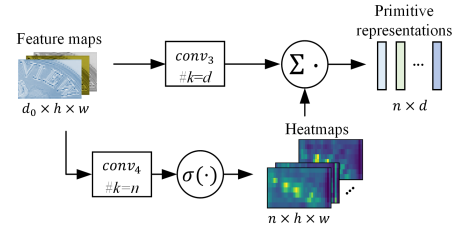
该算子的目的是为了自适应的学习不同样本间独特的信息(Pooling aggregator并没有考虑样本间差异)。
从图中可以看出算子有两个分支,上边的分支经过输出channel=d的卷积和一个非线性激活函数,得到shape=[d,h,w]的feature map,reshape后变为[d,h*w]。下面的分支经过输出channel=n的卷积和一个sigmoid,得到shape=[n,h,w]的heat maps,reshape后变为[n,h*w]。然后对两个矩阵做矩阵乘法,得到shape=[n,d]具备sample-specific特性的原始特征表达。其物理意义为:对于每一个heatmap,去点乘每一个featuremap(总共有d个),得到当前heatmap对于每个featuremap的权重贡献,shape=[1,d],由于总共有n个heat map,所以最终的shape=[n,d]。
其具体操作如下:
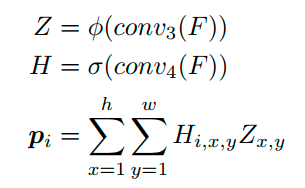
Visual text representation generation
现在得到了两个shape=[n,d]的原始特征表达,对于每一个特征表达,通过GCN映射回视觉表达。
具体可以表示为以下pipeline:[n,d]通过1d conv(输出通道数为max_len)变成[max_len, d],再经过一个线性映射层fc,得到[max_len,d1],再经过一个非线性激活层即可。
最后通过一个输出channel=char_num的fc层,得到[max_len,char_num]用于字符解码。
注:max_len是预先设定的最大解码长度,char_num是字典包含的字符个数。由于每个label的长度不一定达到max_len,这里用padding_idx来填充,注意计算loss的时候padding_idx不参与计算。
其他细节
- backbone采用EfficientNet-B3。
- 上面讨论的都是单feature map的情景,但实际上取了最后3个feature map(1/8,1/16,1/32),可以通过模型结构图发现,对于每一个feature map都应用两种聚合算子,因为通过两种算子后的shape都是[n,d],基于每一个类型的聚合算子输出结果,在这里对做了拼接,所以实际上shape=[n,3d],然后通过各自的GCN网络映射回视觉特征,再对两种算子得到的视觉特征做一个简单的求和操作。最后通过fc映射到字典域即可。
PREN2D
鉴于PREN中的两种算子能够产生更好的特征表达,因此可以将它们插入到attention-based的识别方法中,加强vis-text特征对齐,提高识别精度,具体结构如下:
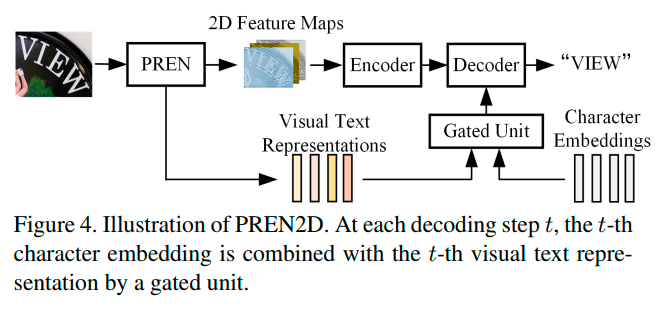
模型整体结构依托transformer(类似于satrn网络)。
2d feature map通过upsample2x(upsample2x(F7)+F5)+F3得到。
feature map通过两个聚合算子+GCN得到refined visual feature[max_len, d]。
在第i个解码阶段,不再是用i-1阶段预测字符的embedding(或者gt embedding),而是用第i个refined visual feature和第i-1阶段预测字符embedding的自适应组合:
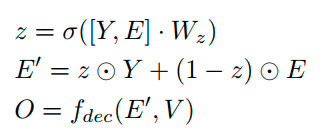
此时refined visual feature提供了全局特征引导,起到了加强vis-text特征对齐的作用。
另外,transformer encoder中也做了小幅优化:
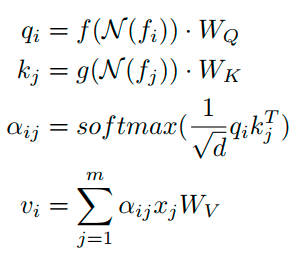
f ( N ( f i ) ) f(N(f_i)) f(N(fi))和 G ( N ( f j ) ) G(N(f_j)) G(N(fj))就是两个3x3 conv,加强了局部特征关联而已,比较简单。
Training and Infernece
对于label,其预处理策略为: [ a , b , c , < e o s > , < p a d > , < p a d > . . . < p a d > ] [a,b,c,<eos>,<pad>,<pad>...<pad>] [a,b,c,<eos>,<pad>,<pad>...<pad>]总长度为max_len。
训练Loss为交叉熵损失:
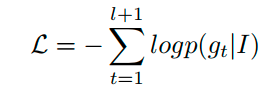
注意不参与Loss计算。
inference阶段由于最后是FC,可以一次并行解码出全部识别字符,那么预测到或者到达最大预测长度即结束解码。
实验
英文场景,仅用MJ+ST训练,PREN2D达到全部benchmark(包含regular以及irregular dataset)SOTA。PREN表现也很强势。
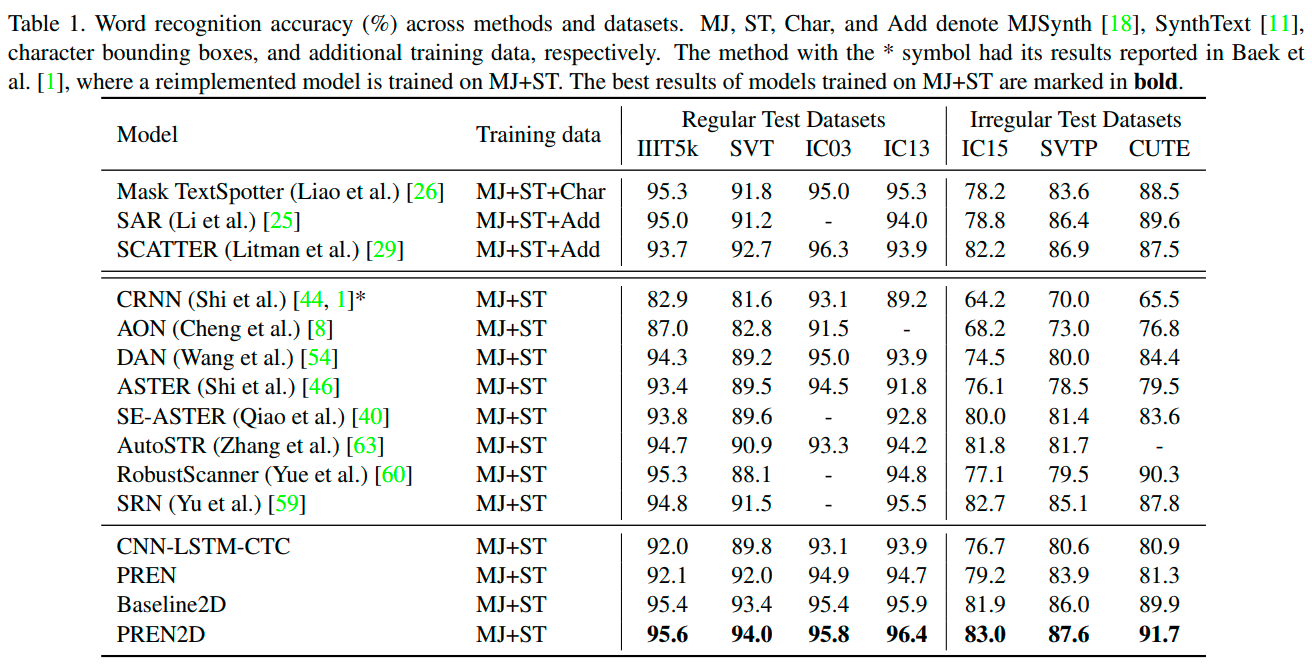
预测速度上,PREN预测速度比CRNN还快。

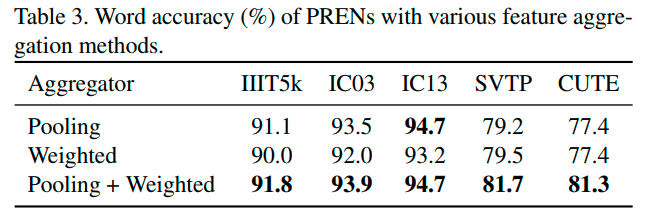
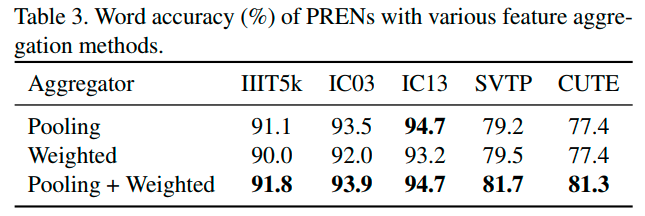
两种聚合算子的消融实验,只用pool在regular dataset上效果比weightd好,只用weighted在irregular dataset上效果比pool好。当然两者都用上效果是最好的
聚合特征数量n的消融实验,n太小或者太大都会降低识别精度,通过实验发现设定为5是比较合理的数值。
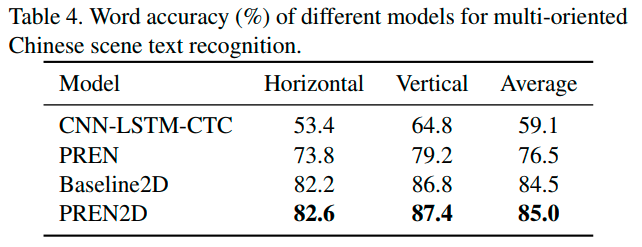
中文多方向识别场景实验,PREN2D表现也是最好的。
总结
- 提出了两种聚合算子来学习primitive feature,再通过GCN映射回vision空间得到refined visual feature,既可以直接解码,也可以和attention-based model结合优化解码过程,并通过实验证明了pipeline有助于提点的结论。
- 模块设计简单,计算量小,是一个很好的innovation point。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









