






前沿科技速递🚀
在人工智能领域,每一次技术的进步都伴随着参数规模的提升和计算力的突破。然而,面壁智能公司最新推出的MiniCPM-V 2.6端侧多模态模型,却以相对“小巧”的8B参数量级,打破了传统思维,实现了端侧多模态能力的重大飞跃。这款模型不仅在单图、多图、视频理解三项任务上超越了GPT-4V,更为端侧AI应用开启了全新的篇章。
来源:传神社区
01 “三合一”最强端侧多模态:全面超越GPT-4V
MiniCPM-V 2.6的最大亮点在于其“三合一”的多模态理解能力。传统的端侧模型往往只能在单一模态上表现出色,而MiniCPM-V 2.6通过深度优化模型架构和训练算法,成功实现了在单图、多图和视频理解上的全面突破。这款模型不仅能够对单张图片进行深入理解,还能在多图联合分析和动态视频内容理解方面给出精准、富有洞察力的结果。
这种能力的实现,对端侧AI应用具有里程碑式的意义。我们可以期待,在未来的端侧设备中,更多智能化、丰富多样的AI应用将会出现,如实时图像识别、视频内容分析和多模态交互等,进一步提升用户体验。
02 多项功能首次上端:开启端侧AI的新篇章
除了多模态理解能力的全面提升,MiniCPM-V 2.6还首次在端侧模型中实现了多项功能,包括实时视频理解、多图联合理解、多图ICL(视觉类比学习)和多图OCR等。这些功能的引入,标志着端侧AI应用的新里程碑。
🎬实时视频理解 是MiniCPM-V 2.6的一大亮点。传统的端侧模型由于计算资源和模型复杂度的限制,难以实现实时视频处理。然而,MiniCPM-V 2.6通过对模型结构和算法的优化,成功实现了这一功能。这对于视频监控、实时互动等应用场景具有重大意义,能够让端侧设备更加智能、高效。
🖼️多图联合理解 则为图像比较和多图分析等应用场景提供了新的可能。MiniCPM-V 2.6不仅能处理单张图片,还能同时处理多张图片,并理解它们之间的关联和差异。这一创新功能,对于处理复杂视觉信息的任务具有极高的价值。
💪多图ICL(视觉类比学习) 和 多图OCR 功能的实现,则进一步丰富了MiniCPM-V 2.6的应用场景。通过视觉类比学习,模型能够识别和理解不同图片之间的相似性和差异性,从而实现更精准的图像分类和识别。OCR功能的加入,使得该模型能够高效地识别和处理图片中的文字信息,为文本提取和图像标注等应用场景提供了有力支持。

03 极致高效:全面优化像素密度、内存占用和推理速度
在追求高性能的同时,面壁智能团队也注重对模型效率的优化。MiniCPM-V 2.6在像素密度、内存占用和推理速度等方面实现了极致的高效性。这得益于团队在模型压缩和加速技术上的深入研究,使得该模型在端侧设备上运行时能够占用更少的资源,同时保持高效的处理速度。
具体来说,MiniCPM-V 2.6采用了先进的模型压缩技术,降低了参数规模和计算复杂度,使其在端侧设备上运行时更加轻量化。无论是在像素密度较高的图像上,还是在内存资源有限的端侧设备上,该模型都能表现出色,快速且准确地完成任务。
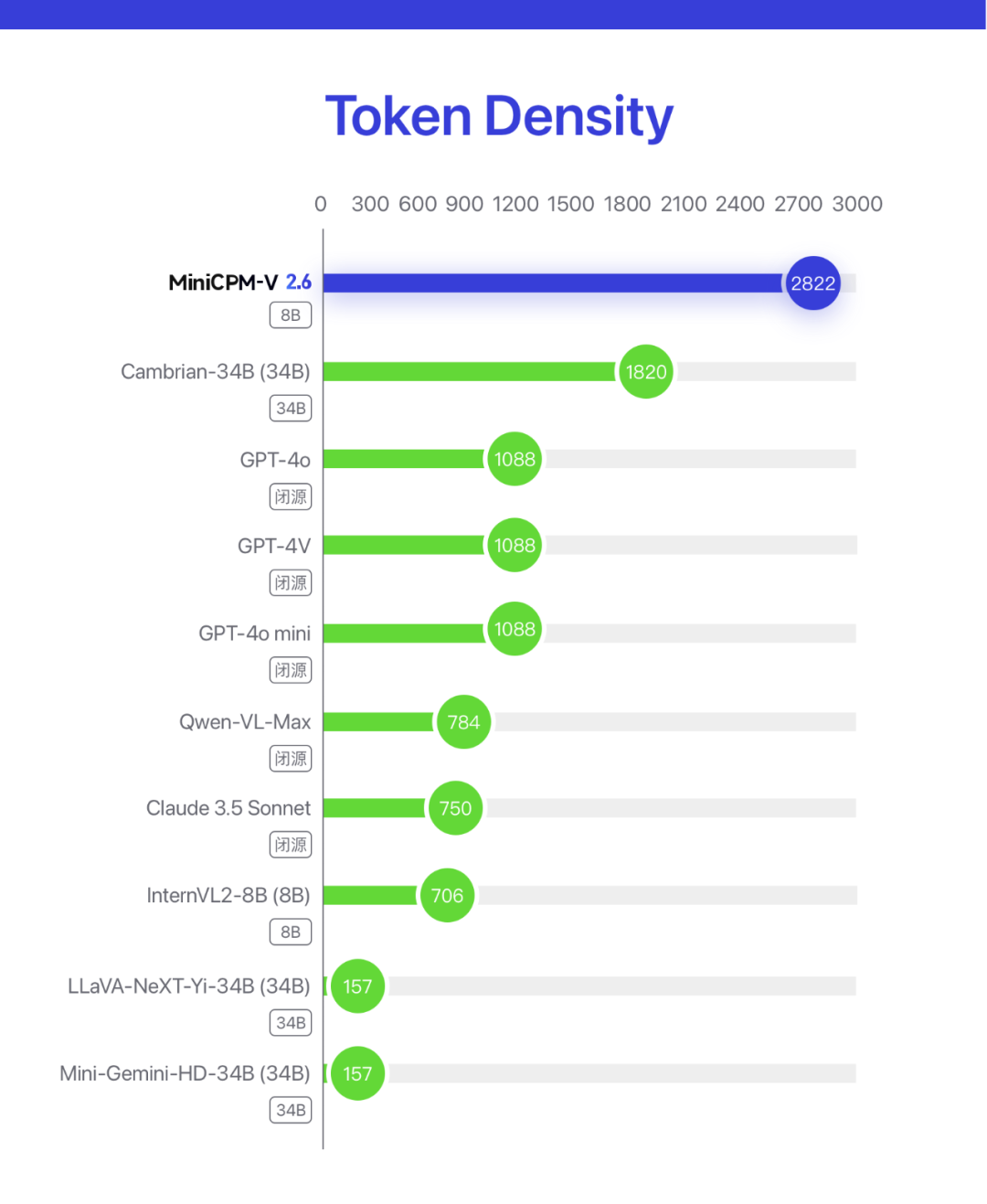
此外,MiniCPM-V 2.6在推理速度上也取得了显著提升。与上代模型相比,推理速度提高了33%,达到每秒18 tokens,使其能够更加高效地处理复杂的多模态任务。这种高效性使得该模型在更多端侧AI应用场景中得以实现,为智能手机、平板电脑和其他端侧设备的功能升级提供了有力支持。

04 全面性能验证:实力见证未来之星
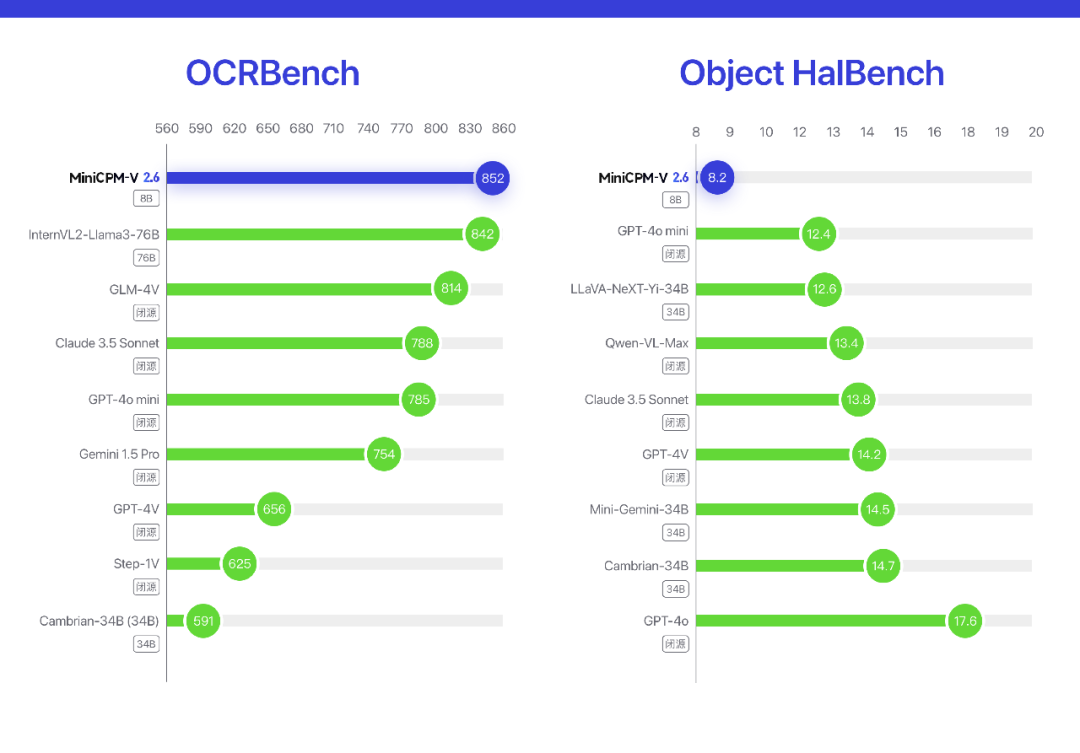
面壁智能团队通过一系列的评测和对比实验,全面展示了MiniCPM-V 2.6的性能和实力。无论是在单图理解、多图处理还是视频理解任务上,该模型均表现出色,超越了GPT-4V。在OCR任务中,MiniCPM-V 2.6的文字识别准确率和速度也优于其他端侧OCR模型,展现出强大的多模态处理能力。

在幻觉评测榜单 Object HalBench 上,MiniCPM-V 2.6 的幻觉水平(幻觉率越低越好)优于 GPT-4o、GPT-4V、Claude 3.5 Sonnet 等众多商用模型。MiniCPM-V 2.6的低幻觉率进一步提升了其在复杂场景中的处理能力,使其能够更加准确地识别和理解图像内容。这一特性的实现,为端侧AI应用的可靠性和稳定性提供了有力保障。
05 典型示例
对于GPT-4V 官方演示经典命题:调整自行车车座。这个对人很简单的问题对模型却非常困难,它非常考验多模态模型的复杂推理能力和对物理常识的掌握能力。仅 8B 的 MiniCPM-V 2.6 展现出顺利完成这项挑战的潜力,通过和模型进行多图多轮对话,它清晰地告知完成调低自行车车座的每一个详细步骤,还能根据说明书和工具箱帮你找到合适的工具。

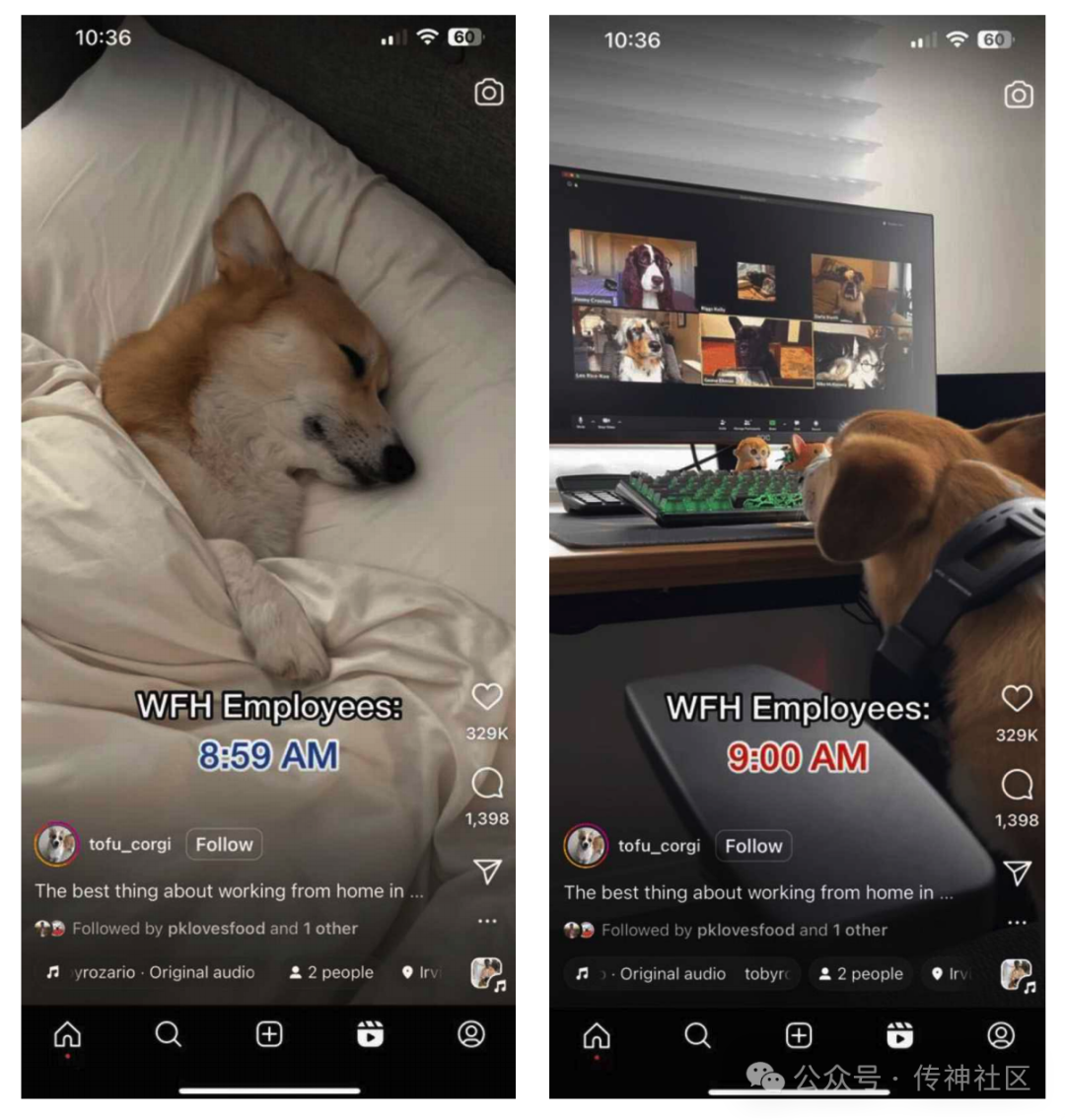
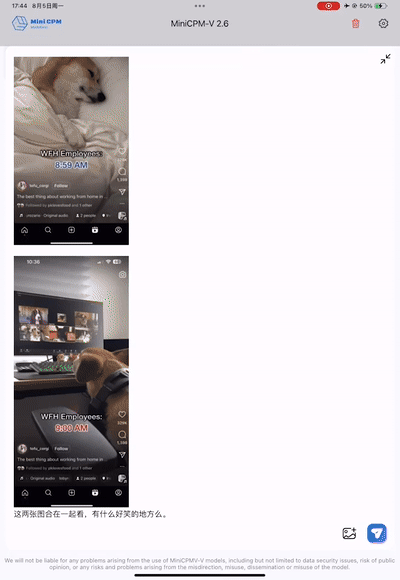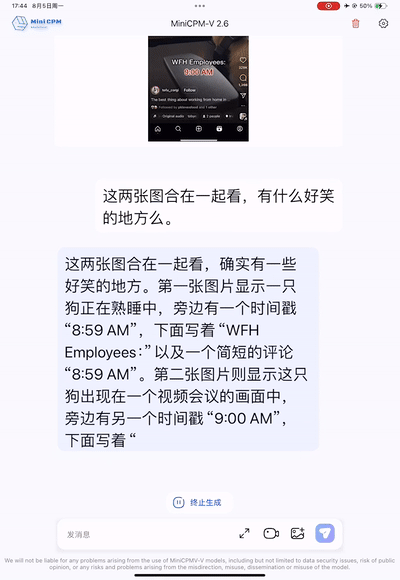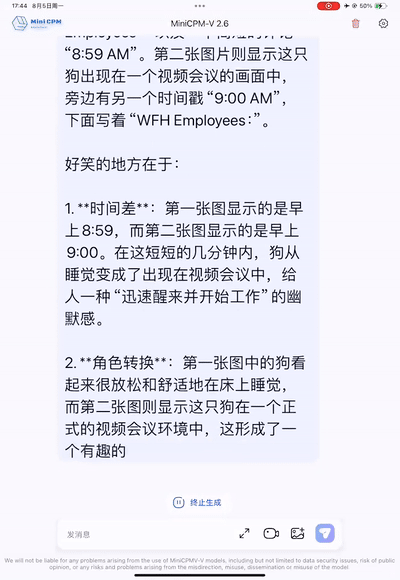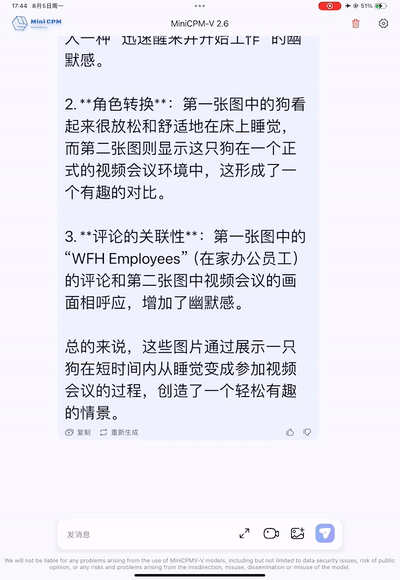
让模型解释下面两张图背后的小故事,MiniCPM-V 2.6 能够通过 OCR 精准识别到两张图片上的文字:“WFH Employees 8:59 AM”和 “WFH Employees 9:00 AM”,推理出“WFH”居家办公状态,然后结合两张图片的视觉信息联合推理出“工作在家时,8:59还在床上睡觉,9点立马出现在视频会议上”的居家办公的“抓狂”状态,尽显梗图的槽点和幽默,可谓是多图联合理解和 OCR 能力的强强结合。
当我们把近期风靡网络的“无语佛”表情包提交给MiniCPM-V 2.6模型时,模型不仅能够细腻地捕捉到表情包中菩萨雕像的微妙表情变化,如眼神中的无奈与嘴角的一抹苦笑,还能深刻解读出这些微表情背后所蕴含的复杂情感与幽默意涵。

06 模型下载
传神社区:https://opencsg.com/models/OpenBMB/MiniCPM-V-2_6
github:https://github.com/OpenBMB/MiniCPM-V
欢迎加入传神社区
•贡献代码,与我们一同共建更好的OpenCSG
•Github主页
欢迎🌟:https://github.com/OpenCSGs
•Huggingface主页
欢迎下载:https://huggingface.co/opencsg
•加入我们的用户交流群,分享经验

扫描上方二维码添加传神小助手
“ 关于OpenCSG
开放传神(OpenCSG)成立于2023年,是一家致力于大模型生态社区建设,汇集人工智能行业上下游企业链共同为大模型在垂直行业的应用提供解决方案和工具平台的公司。
关注OpenCSG

加入传神社区



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









