






前沿科技速递🚀
在 AI 大模型浪潮中,国内厂商面壁智能再次突破,推出了其最新的“小钢炮”系列——MiniCPM 3.0。这款全新模型不仅实现了在移动设备上运行 GPT-3.5 级别的能力,而且具备超强的推理、检索与代码解释功能。MiniCPM 3.0 以仅 4B 参数的“轻量级”模型,成功超越了 GPT-3.5,在移动端 AI 应用场景中展现出强大的实力。
来源:传神社区
01 模型介绍:从 MiniCPM 1.0 到 3.0
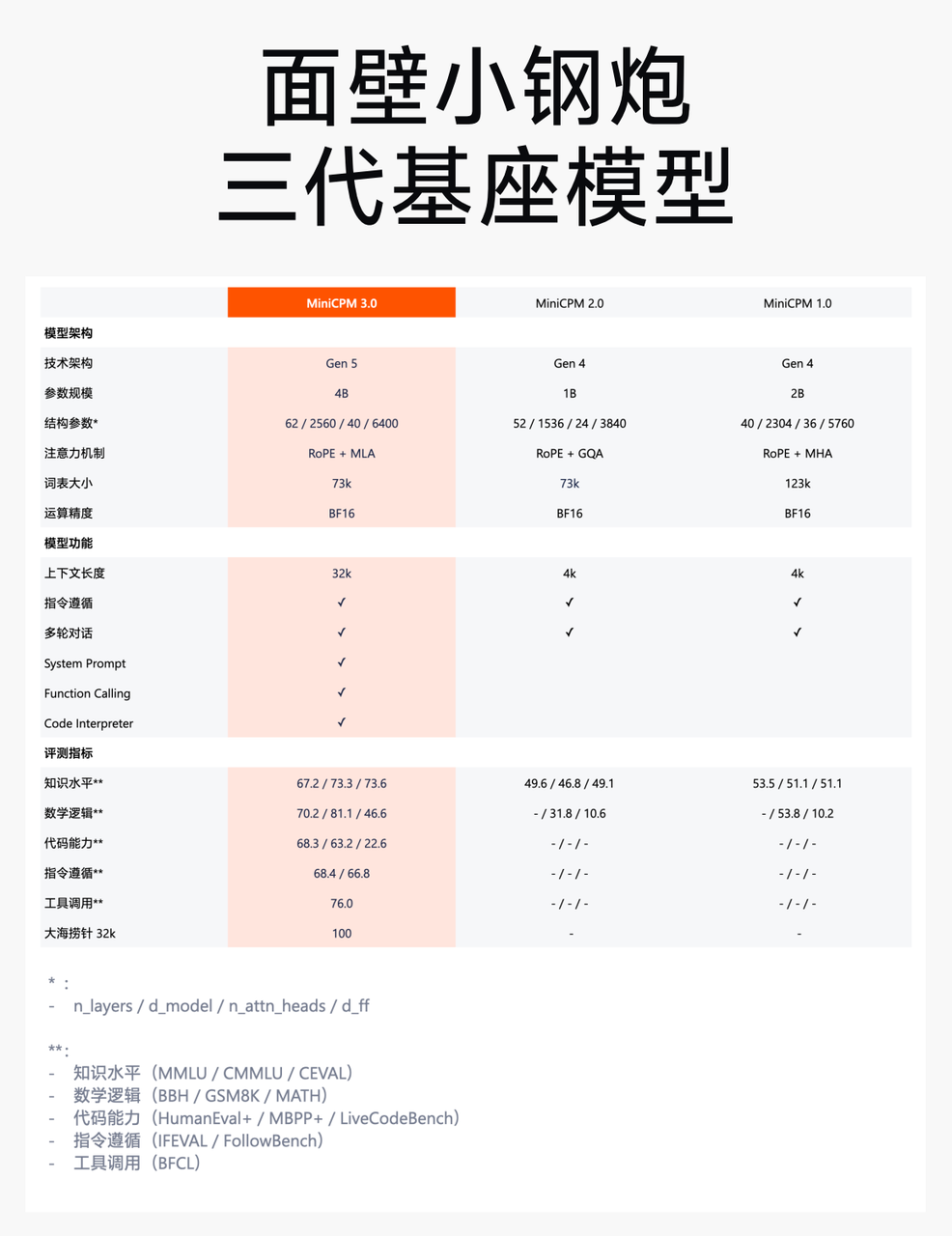
MiniCPM 3.0 是面壁智能“小钢炮”系列的最新版本,相比于前两代,3.0 版本在模型结构、性能优化和功能支持上都有显著提升。以下是对比三代模型的结构差异和关键改进:
-
位置编码机制:RoPE -> RoPE -> RoPE
-
三代模型都采用了 RoPE(旋转位置编码),确保模型在处理长文本时能够高效地保留序列的位置信息,尤其是在处理超长上下文时表现更为出色。
-
-
注意力机制:MHA -> GQA -> MLA
-
MiniCPM 1.0 采用标准的多头自注意力机制(MHA),
-
MiniCPM 2.0 引入了分组查询注意力机制(GQA),提高了注意力计算效率,
-
MiniCPM 3.0 使用了 MLA(Multi-Level Attention),这一核心创新使得模型在复杂任务处理中的推理和生成能力更强,特别是长文本处理时性能更为稳定。
-
-
词表大小:123K -> 73K -> 73K
-
从 MiniCPM 2.0 开始,词表大小被大幅精简至 73K,有效提高了模型的处理速度和多语言场景中的适用性。
-
-
模型层数:40 -> 52 -> 62
-
随着版本迭代,模型层数逐步增加,提升了模型的复杂性与推理能力。
-
-
隐藏层节点数:2304 -> 1536 -> 2560
-
MiniCPM 3.0 的隐藏层节点增加至 2560,使模型的表现力和任务处理能力进一步增强,特别是在数据推理任务上表现更加优秀。
-
-
最大上下文长度:4K -> 4K -> 32K
-
MiniCPM 3.0 的上下文处理长度大幅提升至 32K,支持长文本的处理。这为模型在文档分析、写作工具等应用场景中提供了强大的优势。
-
-
系统提示词与工具调用能力:不支持 -> 不支持 -> 支持
-
MiniCPM 3.0 引入了系统提示词功能,并支持工具调用和代码解释器,使得模型能够通过自然语言交互执行复杂任务,特别是在工具调用上性能显著增强。
-
02 核心亮点:打破性能与参数之间的界限
-
无限长文本处理,性能随文本长度延展
-
MiniCPM 3.0 引入了 LLMxMapReduce 技术,实现了无限长文本的处理能力。无论是 32K 还是 512K,模型都能高效处理长文本,并且在长文档场景中具备超强的性能稳定性。
-
在长文本测试的 InfiniteBench Zh.QA 评测中,MiniCPM 3.0 甚至超越了 8B、9B 参数量级的对手 Kimi,展现出极为优异的表现。

-
-
端侧最强 Function Calling,媲美 GPT-4o
-
MiniCPM 3.0 是目前端侧设备上 Function Calling 性能最强的模型之一,能够精准理解用户输入,并转化为可执行的结构化指令。无论是调用日历、天气、还是手机中的文件和应用,MiniCPM 3.0 都能流畅响应。
-
在 Berkeley Function-Calling Leaderboard 上,MiniCPM 3.0 的性能接近 GPT-4o,证明了它在工具调用上的实力。

-
-
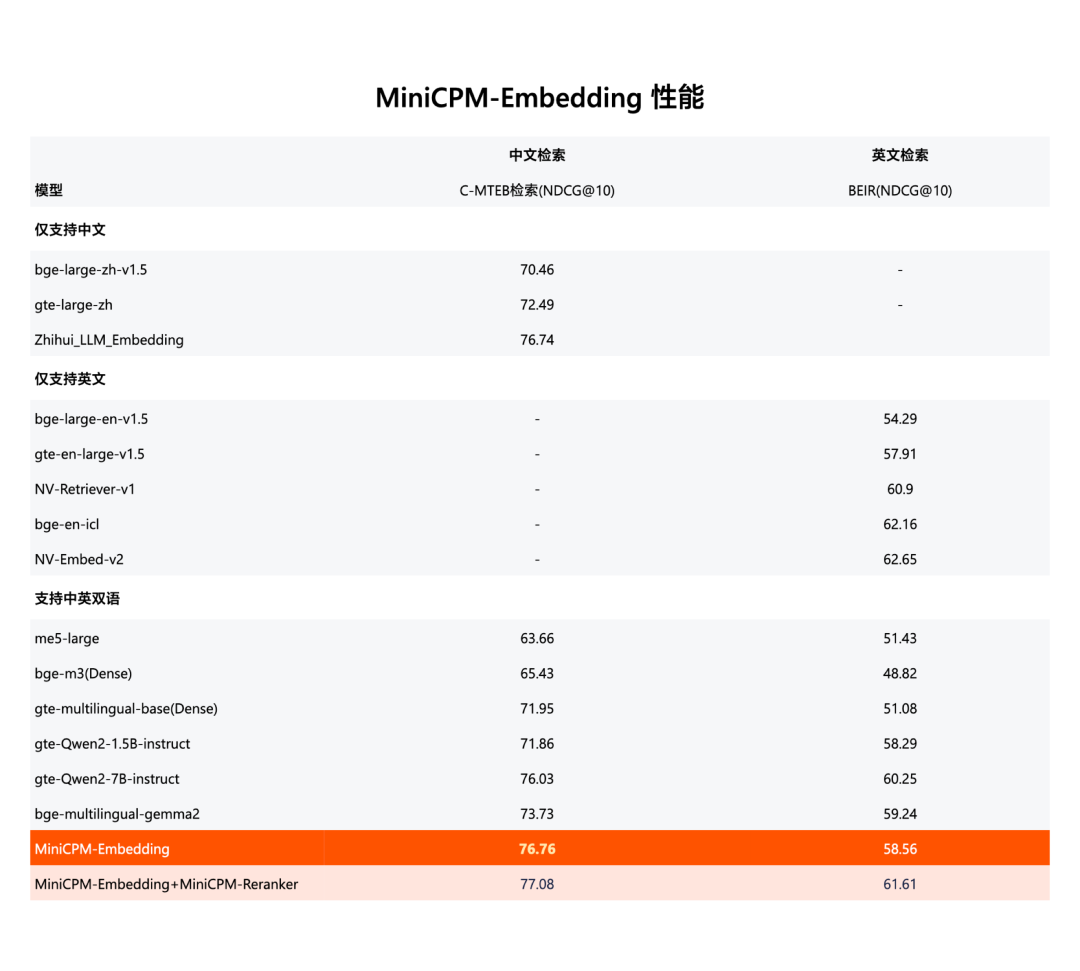
RAG 三件套:检索、排序、生成全能选手
-
MiniCPM 3.0 同时发布了 RAG(检索增强生成)三件套:MiniCPM-Embedding(检索)、MiniCPM-Reranker(重排序)和 MiniCPM3-RAG-LoRA(生成)。在多项检索任务中取得了 SOTA(State of the Art)的表现。
-
经过 LoRA 微调后,MiniCPM 3.0 在开放域问答、多跳问答等任务上,超越了 Llama3-8B 和 Baichuan2-13B,成为中英文跨语言检索的领导者。
-
03 MiniCPM性能评估
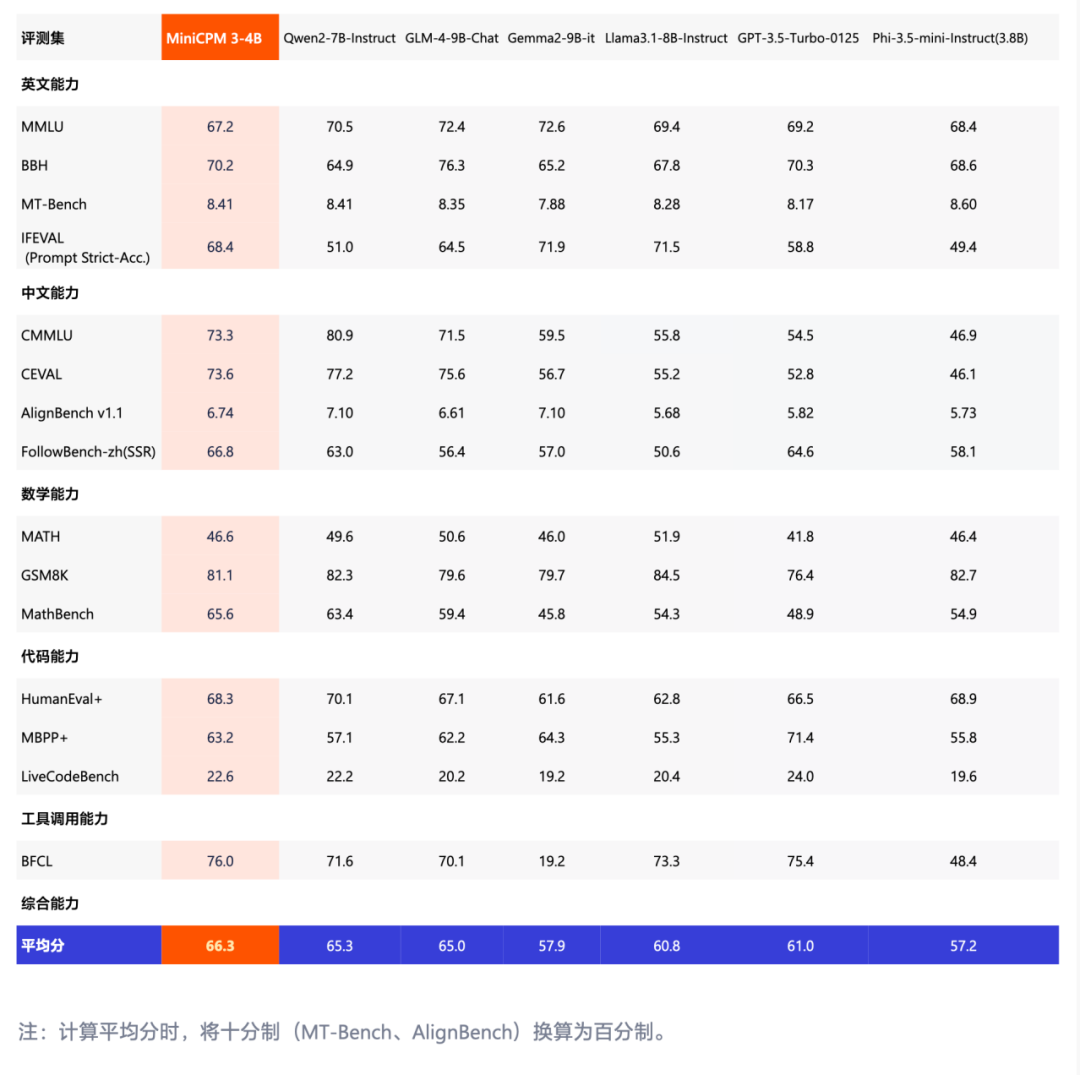
从评测数据中可以看出,MiniCPM3-4B 在多个评测集上的表现优越,尤其在整体性能和工具调用能力方面展现了明显的领先优势。
在综合评测的平均分上,MiniCPM3-4B 以 66.3 的得分超越了 Qwen2-7B(65.3) 和 GLM-4-9B-Chat(65.0) 等大模型,展现出强大的综合能力。与部分 7B、9B 参数的大模型相比,MiniCPM3-4B 的性能表现显著更好,尤其是在中文能力、数学能力等任务中优势明显。
在工具调用能力的评测中,MiniCPM3-4B 在 BFCL(Berkeley Function Calling Leaderboard)上的得分高达 76.0%,领先于 Qwen2-7B-Instruct(71.6%) 和 GLM-4-9B-Chat(70.1%) 等多个更大参数模型,表现出超强的工具调用能力。相比于其他大模型,MiniCPM3-4B 在这方面的领先地位使其在实际应用中更加高效、灵活。
04 模型下载
传神社区:
MiniCPM3-4B:
https://opencsg.com/models/OpenBMB/MiniCPM3-4B
github:
https://github.com/OpenBMB/MiniCPM/
欢迎加入传神社区
•贡献代码,与我们一同共建更好的OpenCSG
•Github主页
欢迎🌟:https://github.com/OpenCSGs
•Huggingface主页
欢迎下载:https://huggingface.co/opencsg
•加入我们的用户交流群,分享经验

扫描上方二维码添加传神小助手
“ 关于OpenCSG
开放传神(OpenCSG)成立于2023年,是一家致力于大模型生态社区建设,汇集人工智能行业上下游企业链共同为大模型在垂直行业的应用提供解决方案和工具平台的公司。
关注OpenCSG

加入传神社区















 439
439

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









