






01
背景
近年来,生成式语言模型(GLM)的飞速发展正在重塑人工智能领域,尤其是在自然语言处理、内容创作和智能客服等领域展现出巨大潜力。然而,大多数领先的语言模型主要依赖于英文数据集进行训练,中文数据资源在规模和多样性方面相对不足,限制了中文生成式模型的实际应用表现。为应对这一挑战,OpenCSG算法团队启动了 Chinese Cosmopedia 项目,对标Huggingface Cosmopedia,旨在构建一个专为中文语言模型设计的大规模合成数据集,推动中文大模型的性能提升和广泛应用。
Chinese Cosmopedia 项目通过整合中文互联网中的多种数据来源和内容类型,构建了涵盖约1500万条数据和600亿个token的庞大数据集。该数据集包括了多种文体和风格,如大学教科书、中学教科书、幼儿故事、技术教程和普通故事等,内容广泛涉及学术、教育、技术等多个领域。这些多样化的数据能够满足不同应用场景的需求,帮助训练更加智能和精准的中文生成式语言模型。
OpenCSG团队在数据生成过程中,通过种子数据和prompt设计来控制数据的主题和风格,确保数据的多样性和高质量。例如,种子数据来源于各类中文百科、知识问答和技术博客等,而prompt则用于生成具有不同受众和风格的内容,从学术教科书到儿童故事,内容广泛且具有针对性。团队还利用先进的生成技术,确保生成数据具备连贯性和深度。
通过推出 Chinese Cosmopedia,OpenCSG团队致力于提升中文语言模型在多种任务中的表现,使得中文模型在准确性、生成能力和实际应用中的表现更加优越。该项目不仅将帮助研究人员和开发者加速中文大模型的训练和应用,也将为企业和行业提供丰富的工具和数据支持。Chinese Cosmopedia 的成功实施将成为中文AI技术发展中的一个重要里程碑,推动人工智能技术的普及和民主化,让更多人和企业能够享受到AI带来的创新和效益。

02
Cosmopedia数据集介绍
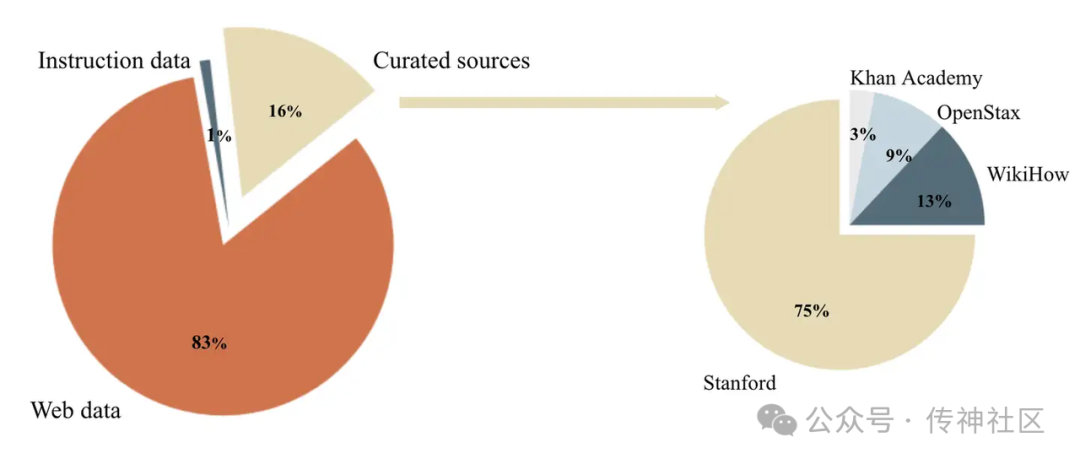
Cosmopedia 是 Hugging Face 社区开发的一个庞大的开放合成数据集,旨在支持大语言模型(LLM)的预训练。该数据集包含超过 3000 万个文件,总共约 250 亿个 tokens,是迄今为止最大规模的公开合成数据集之一。Cosmopedia 的主要目的是生成用于模型训练的多样化、高质量数据,以复现类似于微软的 Phi-1.5 模型的训练数据。

内容覆盖面广泛
Cosmopedia 涵盖多种文本类型,包括合成教科书、博客文章、故事以及类似 WikiHow 的教程文章。这些内容从不同的来源获取和加工,既包括精选的教育资源,如 斯坦福课程、可汗学院、OpenStax 和 WikiHow。这些资源涵盖了许多有价值的主题可供 LLM 学习。
Cosmopedia 中 80% 以上的提示数据来自网络,经过复杂的聚类算法,确保生成数据的多样性和质量。这些数据广泛覆盖多个主题,从教育、科学到日常生活,几乎涵盖了人类知识的方方面面。
生成方法与挑战
Cosmopedia 的生成过程中,使用了 Mixtral-8x7B-Instruct-v0.1 模型。提示生成是该项目的核心部分,为了确保生成的内容在不同主题和受众间保持多样性,开发团队设计了数百万条不同的 prompts,调整了生成文本的风格和目标受众。这些提示不仅包括学术教科书式的生成任务,还包括为少年儿童、研究人员等不同受众定制的内容。
数据集链接:https://huggingface.co/datasets/HuggingFaceTB/cosmopedia
03
Chinese Cosmopedia 数据集
数据集简介
Chinese Cosmopedia数据集共包含1500万条数据,约60B个token,构建合成数据集的两个核心要素是种子数据和prompt。种子数据决定了生成内容的主题,prompt则决定了数据的风格(如教科书、故事、教程或幼儿读物)。数据来源丰富多样,涵盖了中文维基百科、百度百科、知乎问答和技术博客等平台,确保内容的广泛性和权威性。生成的数据形式多样,涵盖大学教科书、中学教科书、幼儿故事、普通故事和WikiHow风格教程等多种不同风格。通过对每条种子数据生成多种不同风格的内容,数据集不仅适用于学术研究,还广泛应用于教育、娱乐和技术领域。

下载地址:
huggingface社区:https://huggingface.co/datasets/opencsg/chinese-cosmopedia
数据来源与种类
Chinese Cosmopedia的数据来源丰富,涵盖了多种中文内容平台和知识库,包括:
-
中文维基百科:提供了大量精确、权威的知识性文章。
-
百度百科:作为国内最具影响力的百科平台之一,百度百科为数据集提供了广泛的中文知识资源。
-
知乎问答:从互动式问答平台中提取的内容,涵盖了多个领域的讨论与见解。
-
技术博客:来自技术社区的文章,涵盖了从编程到人工智能等多个技术方向的深入讨论。
这些种子数据构成了Chinese Cosmopedia数据集的核心内容来源,确保了不同领域知识的覆盖。
数据形式与风格
Chinese Cosmopedia数据集特别注重生成内容的风格与形式,涵盖了从学术到日常应用的多种文本类型,主要包括以下几类:
-
大学教科书:内容结构严谨,深入探讨各类大学学科的核心概念。
-
中学教科书:适合中学生的教学内容,简洁易懂,注重基本知识的传达。
-
幼儿故事:面向5岁儿童,语言简洁易懂,帮助幼儿理解世界和人际关系。
-
普通故事:通过引人入胜的情节和人物对话,展开对某一概念的生动描述。
-
WikiHow风格教程:详细的步骤指导,帮助用户完成特定任务。
每种文体都根据不同的应用场景和目标读者群体,进行了精细化的风格调整。通过这种设计,Cosmopedia不仅适用于学术研究,还能广泛应用于教育、娱乐、技术等领域。
统计
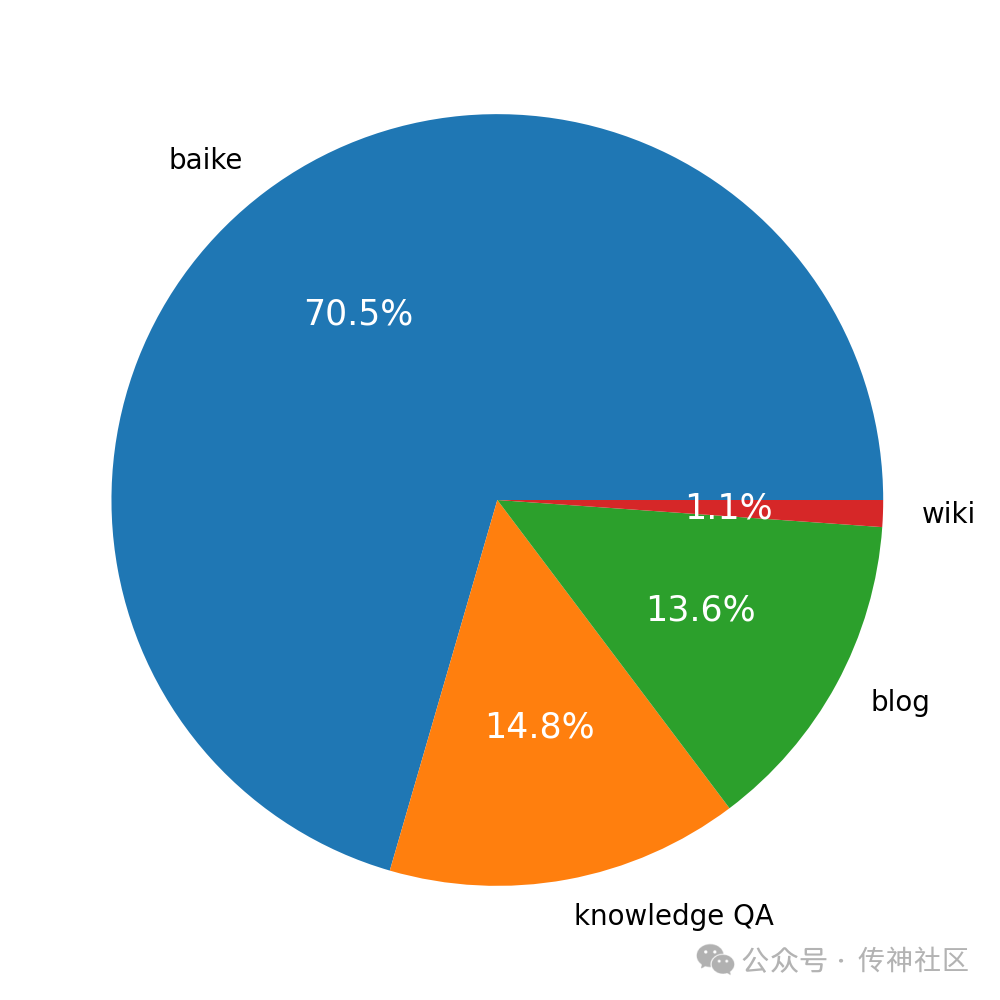
种子数据来源:{'blog': 2111009, 'baike': 10939121, 'wiki': 173671, 'knowledge QA': 2291547}
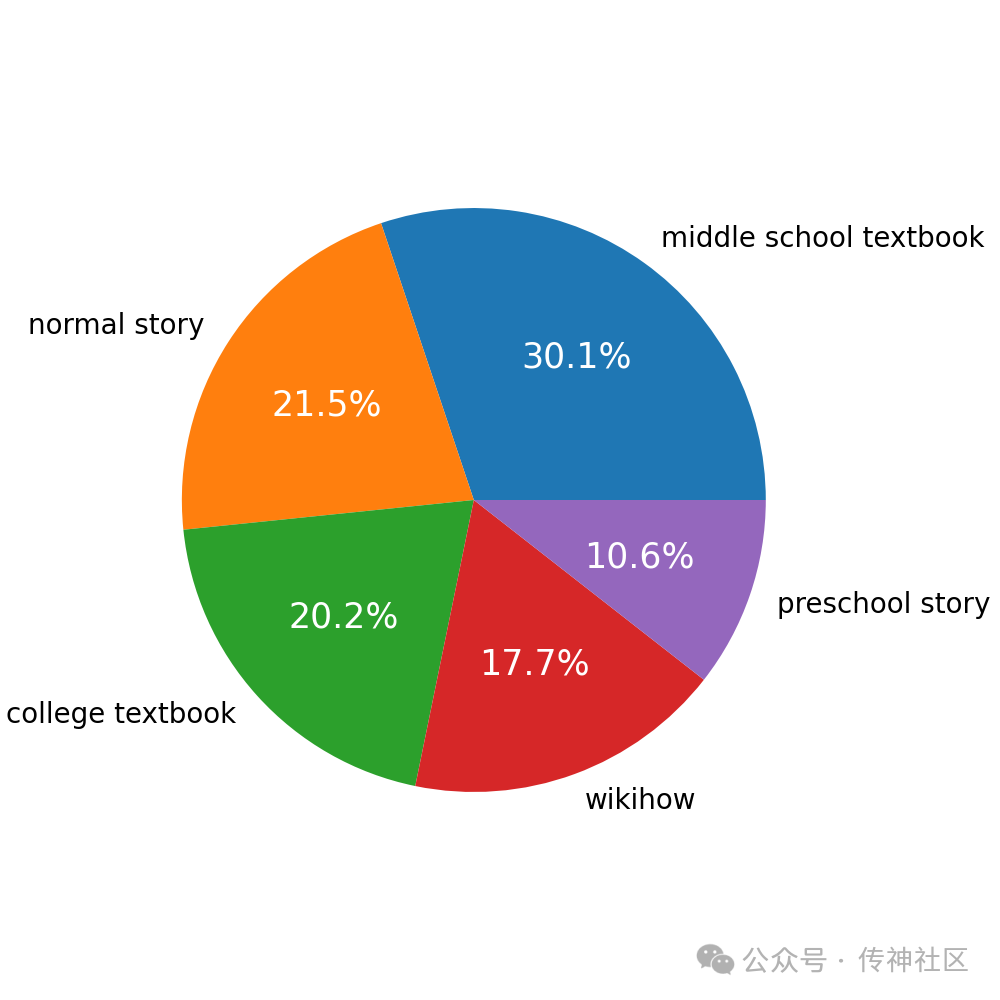
数据形式:{'preschool story': 1637760, 'normal story': 3332288, 'middle school textbook': 4677397, 'college textbook': 3127902, 'wikihow': 2740001}
数据生成与模型
Chinese Cosmopedia的数据生成基于OpenCSG团队自主开发的OpenCSG-Wukong-Enterprise-Long模型。该模型通过强大的长文本生成能力,确保了生成数据的连贯性和内容深度。在数据生成过程中,OpenCSG团队为每种文体和内容类型设计了专门的prompt(提示词),以确保数据生成的风格与内容准确匹配。例如,对于教科书类型的内容,prompt会引导模型生成严谨且具有深度的学术文本,而对于故事类内容,则引导模型创造生动、引人入胜的情节。
我们用于生成各种格式的数据的prompt如下
大学教科书
这是一段来自网页的摘录:“{}”。请编写一个针对大学生的足够详细的教科书课程单元,该单元与给定的摘录中的某个概念或多个概念相关。不需要包含摘录中的所有内容,只需要发掘其中适合作为教科书内容的部分。你可以自由补充其他相关知识。不能仅仅列出概念,而是要深入发展和详细探讨每个概念,因为我们优先考虑深入理解主题内容,而不是广度。要求:1. 严谨性:确保对概念/章节的深入覆盖。2. 吸引性:用学术、专业且引人入胜的语气撰写,以吸引兴趣。3. 应用:融入具体的实践例子,例如微积分中要给出公式、严格证明,历史中要给出关键日期和人物,计算机操作中要给出代码。4.不需要给出参考文献。内容中不应包含广告或涉及隐私的信息。请记住,要针对大学生制作内容,他们可能拥有一些基础知识,但不是该领域的专家。内容应该详细且发人深省。请立即开始撰写教科书,不要使用图片,不要输出除了教科书以外的内容。
中学教科书
网页摘录:“{}”。创建一个与上述网页摘录中的某个概念相关的具有教育意义的内容,针对中学生,尽量长而详细。你可以自由补充其他相关知识。不能仅仅列出概念,而是要深入发展和详细探讨每个概念,因为我们优先考虑深入理解主题内容,而不是广度,不需要包含摘录中的所有内容。不应该使用像微积分这样的复杂大学级主题,因为这些通常不是中学的内容。如果主题是关于这些的,寻找一个更简单的科学替代内容来解释,并使用日常例子。例如,如果主题是“线性代数”,你可能会讨论如何通过将物体排列成行和列来解决谜题。避免使用技术术语和LaTeX,只讨论中学级别的主题。内容中不应包含广告或涉及隐私的信息。请直接开始撰写教育内容,不要输出除了教育内容以外的内容。
普通故事
写一个与以下文本片段相关的引人入胜的故事:“{}”。故事不需要提及片段中的所有内容,只需使用它来获得灵感并发挥创意!可以加入其它知识。故事应包括:1.小众概念或兴趣:深入研究特定的概念、爱好、兴趣或幽默情况 2.意想不到的情节转折或引人入胜的冲突,引入具有挑战性的情况或困境。3.对话:故事必须至少包含一个有意义的对话,以揭示人物深度、推进情节或揭开谜团的关键部分4.反思和洞察:以具有教育意义的新理解、启示的结论结束。5.故事中的人物应使用中国式的名字。请勿包含广告或涉及隐私的信息。请马上开始讲故事,不要输出除了故事以外的内容。
幼儿故事
网页摘录:“{}”创建一个与上述网页摘录中的某个概念相关的具有教育意义的儿童故事,重点针对对世界和人际交往零知识的5岁儿童。故事不需要提及片段中的所有内容,只需使用它来获得灵感并发挥创意。故事应该使用简单的术语。你可以补充额外的知识来帮助理解。使用易于理解的示例,并将 5 岁儿童可能提出的问题及其答案纳入故事中。故事应涵盖日常行为和常见物品的使用。不应该使用像微积分这样的复杂大学级主题,因为这些通常不是幼儿能理解的内容。如果主题是关于这些的,寻找一个更简单的科学替代内容来解释,并使用日常例子。例如,如果主题是“线性代数”,你可能会讨论如何通过将物体排列成行和列来解决谜题。请直接开始撰写故事,不要输出除了故事以外的内容。
wikihow教程
网页摘录:“{}”。以 WikiHow 的风格写一篇长而非常详细的教程,教程与此网页摘录有相关性。教程中需要包括对每个步骤的深入解释以及它如何帮助实现预期结果。你可以自由补充其他相关知识。确保清晰性和实用性,让读者能够轻松遵循教程完成任务。内容中不应包含广告或涉及隐私的信息。不要使用图像。请直接开始撰写教程。
我们诚邀对这一领域感兴趣的开发者和研究者关注和联系社区,共同推动技术的进步。敬请期待数据集的开源发布!
作者及单位
原文作者:俞一炅、戴紫赟、Tom Pei
单位:OpenCSG LLM Research Team

欢迎加入OpenCSG开源社区
OpenCSG作为一家大模型开源社区,基于线上线下一体的CSGHub平台上开源了丰富的训练数据资产、模型资产可以供广大的爱好者免费获取。其中OpenCSG的 Open是开源开放;C 代表 Converged resources,整合和充分利用的混合异构资源优势,算力降本增效;S 代表 Software Refinement,重新定义软件的交付方式,通过大模型驱动软件开发,人力降本增效;G 代表 Generative LM,大众化、普惠化和民主化的可商用的开源生成式大模型。OpenCSG的愿景是让每个行业、每个公司、每个人都拥有自己的模型。我们坚持开源开放的原则,将OpenCSG的大模型软件栈开源到社区。欢迎使用、反馈和参与共建,欢迎关注和Star⭐️
•贡献代码,与我们一同共建更好的OpenCSG
•Github主页
欢迎🌟:https:// github.com/OpenCSGs
•Huggingface主页
欢迎下载:https://huggingface.co/opencsg
•加入我们的用户交流群,分享经验

扫描上方二维码添加传神小助手
“ 关于OpenCSG
开放传神(OpenCSG)成立于2023年,是一家致力于大模型生态社区建设,汇集人工智能行业上下游企业链共同为大模型在垂直行业的应用提供解决方案和工具平台的公司。
关注OpenCSG

加入传神社区

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









