






前沿科技速递🚀
9月26日Meta 推出了 Llama 3.2,这是一个前沿的多模态大语言模型系列。该系列包括轻量级文本模型(1B 和 3B)以及视觉模型(11B 和 90B),专为在边缘和移动设备上的高效应用而设计。这些模型经过预训练和指令调优,特别适合于实时处理和个性化需求,能够在多种任务中展现出卓越的表现,包括文本生成、图像理解和数据摘要。
来源:传神社区
01 模型简介
Meta 于2024年推出了 Llama 3.2,这是一个创新的多模态大语言模型系列。该系列包含轻量级文本模型(1B 和 3B)和视觉模型(11B 和 90B),旨在支持在边缘和移动设备上的高效应用。这些模型经过预训练和指令调优,特别适合于实时处理和个性化应用,能够在多种任务中提供卓越表现,包括文本生成、图像理解和数据摘要。

02 技术亮点
1. 多模态支持
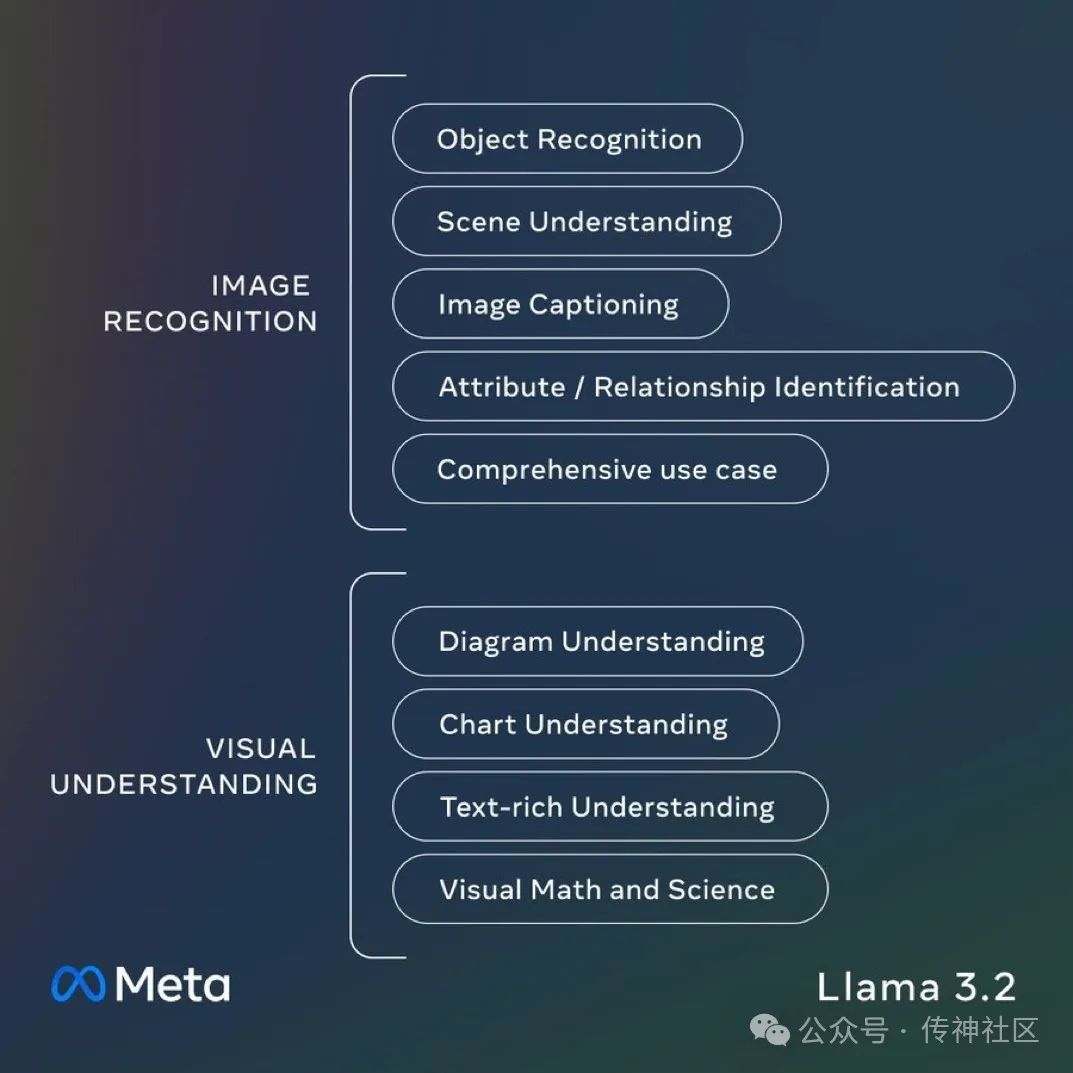
Llama 3.2 引入了图像推理功能,11B 和 90B 模型能够处理文本与图像的组合输入。通过整合视觉和语言模型,这些模型可用于生成图像说明、回答与图像相关的问题,并进行复杂的视觉推理。
2. 本地处理与隐私保护
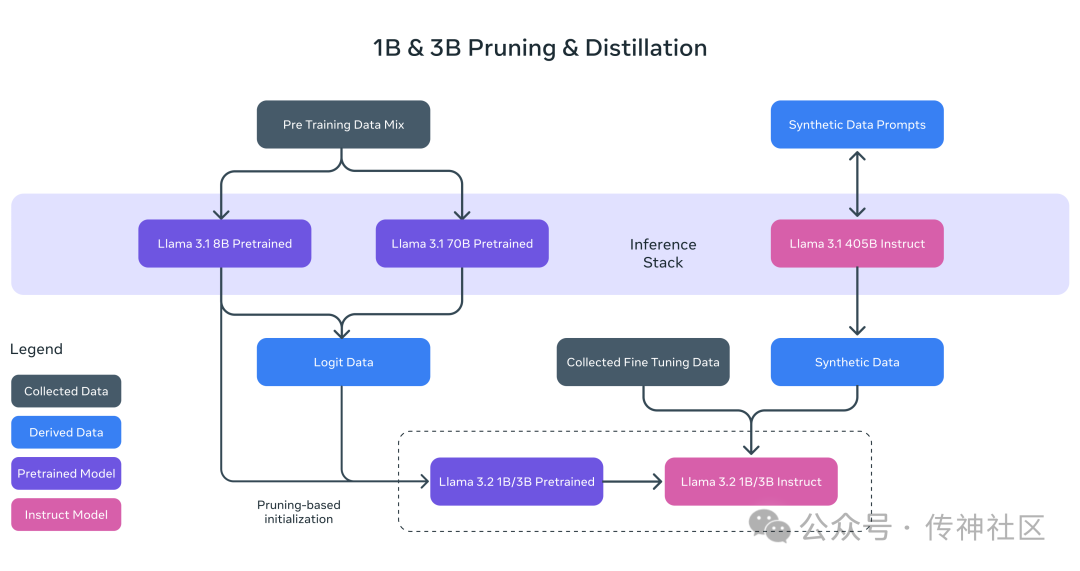
轻量级的 1B 和 3B 模型专为本地设备优化,支持最大128K的上下文长度。这使得应用能够在本地实时运行,减少延迟,同时保障用户数据的隐私,避免将敏感信息上传到云端。
3. Llama Stack 生态系统
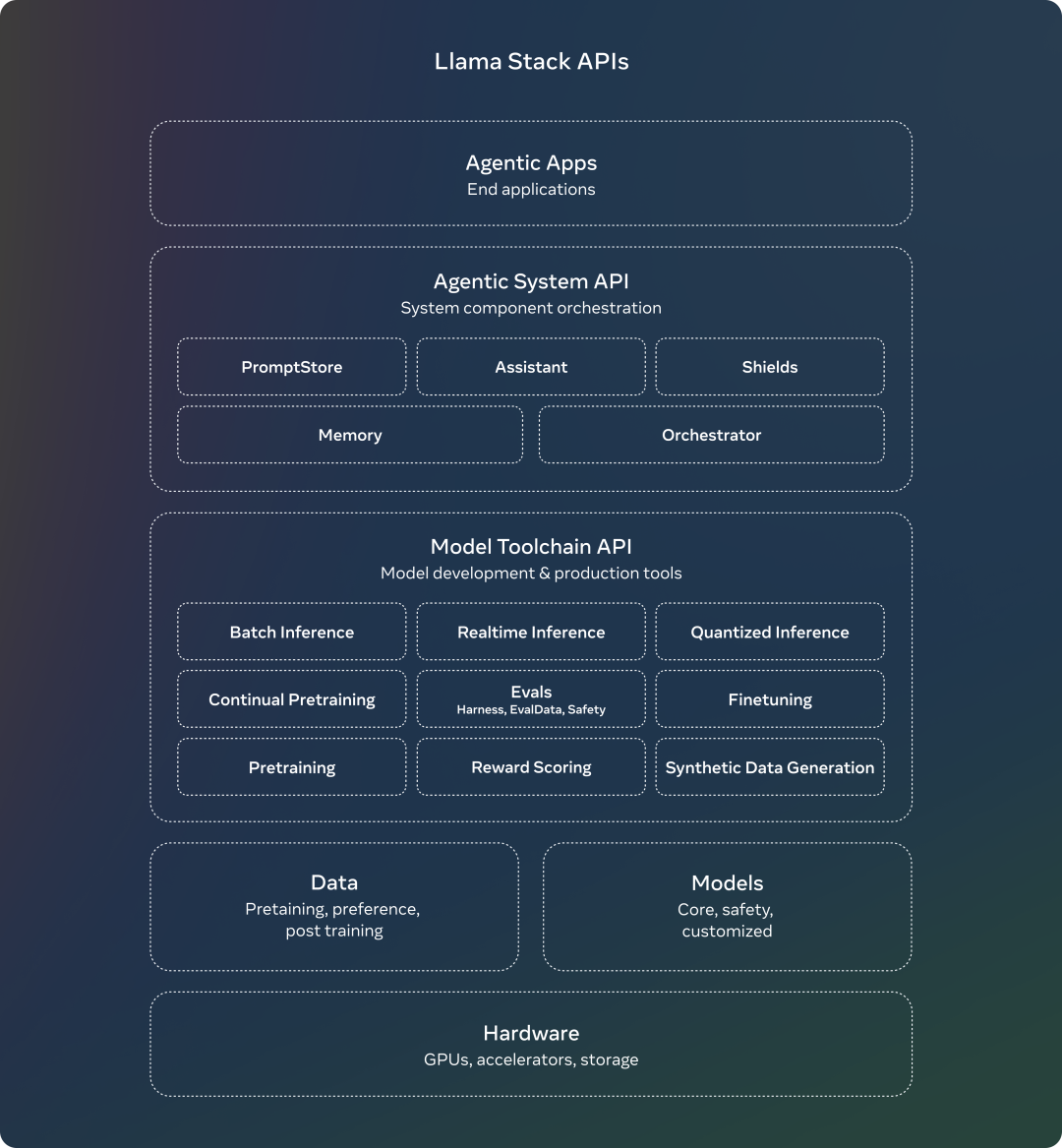
Meta 推出了 Llama Stack,一个用于简化模型开发和部署的框架。Llama Stack 提供了一系列API,支持开发者在单节点、本地、云和边缘环境中无缝操作,促进了模型的高效应用和集成。
4. 安全与责任
Meta 强调安全性,推出了 Llama Guard 3,用于过滤输入和输出,以保护用户和开发者的利益。新的安全机制使得模型在处理复杂任务时更加可靠,降低潜在风险。
03 评测结果
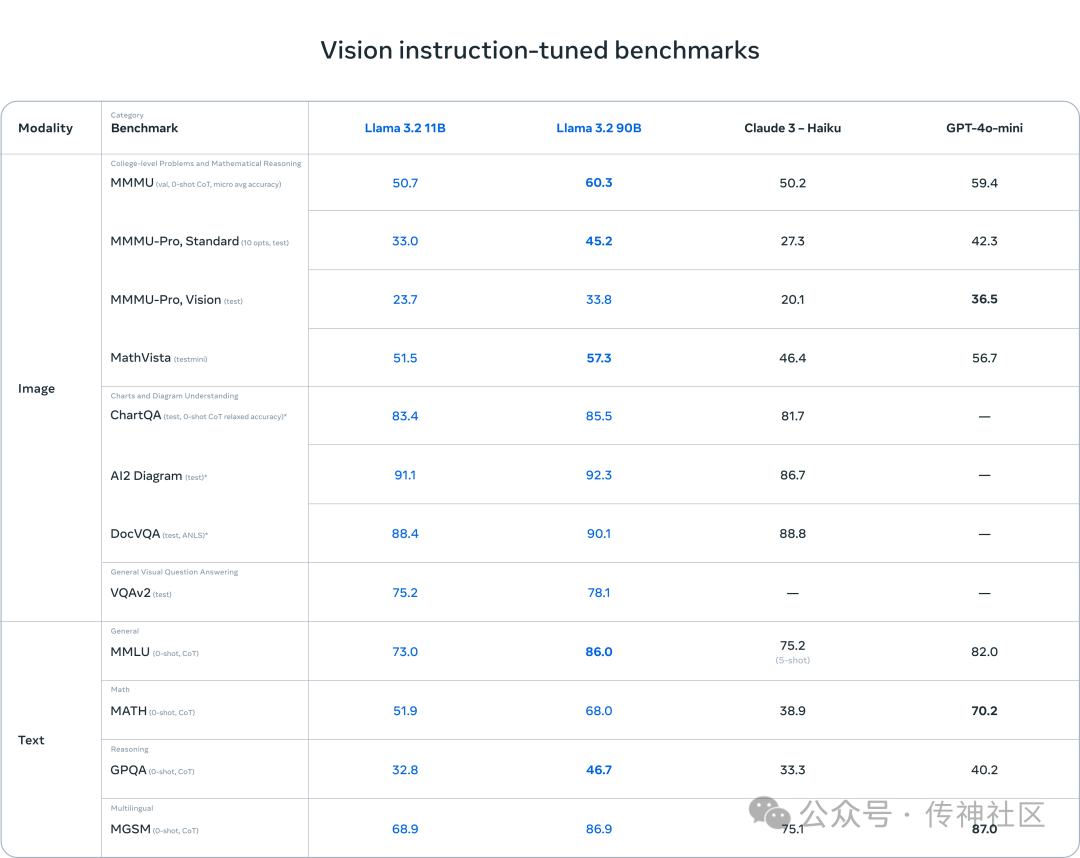
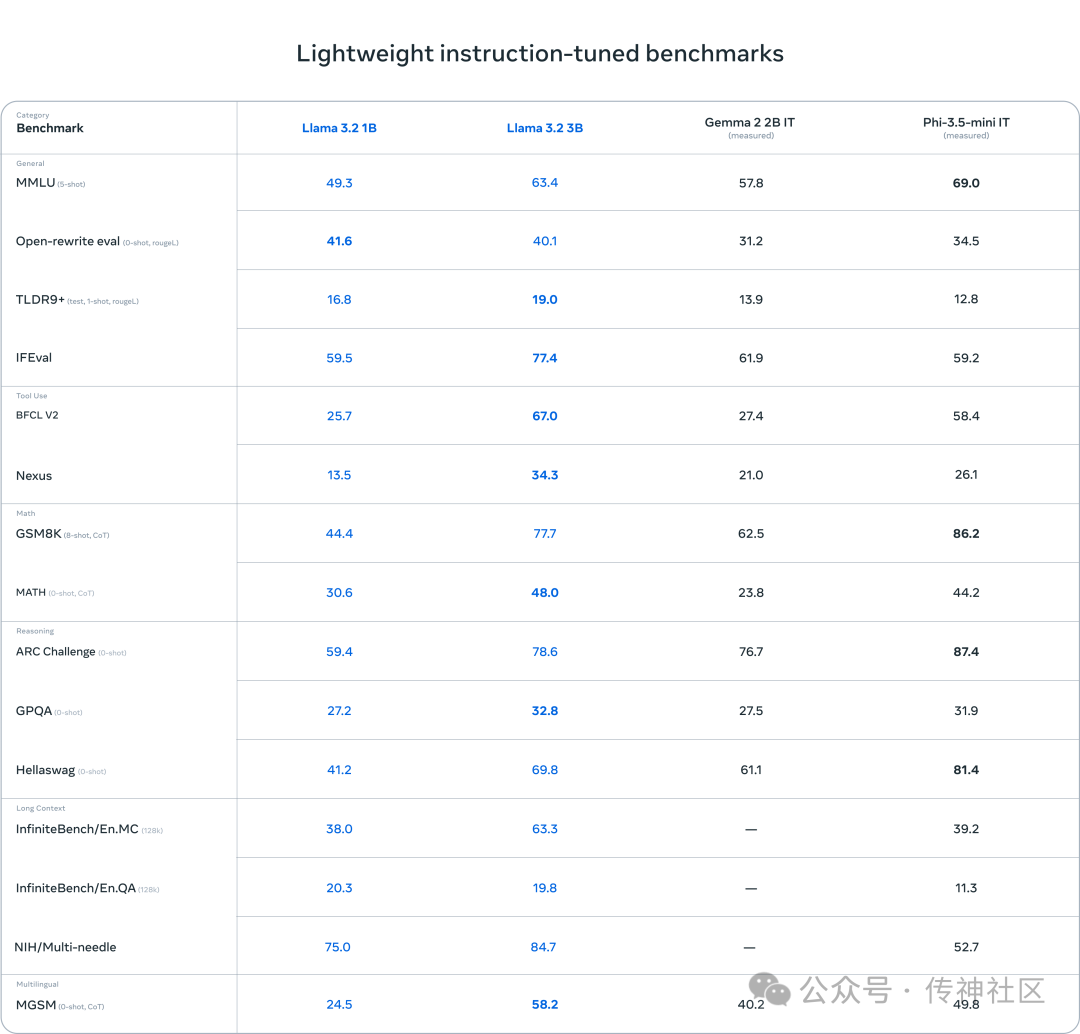
Llama 3.2 在多个基准测试中表现出色,特别是在视觉理解和推理任务上,与 Claude 3 Haiku 和 GPT4o-mini 等领先模型相比具有竞争力。在150多个数据集上的评测结果显示,Llama 3.2 的 3B 模型在指令跟随、总结、文本重写等任务上超越了其他同类模型。
-
视觉模型表现: 11B 和 90B 模型在图像理解任务中取得了显著成绩,能够在复杂场景中进行准确推理,表现优于传统的封闭模型。
-
文本模型表现: 1B 和 3B 模型在多语言生成和工具调用能力方面表现突出,特别是在应用场景中提供了即时响应。
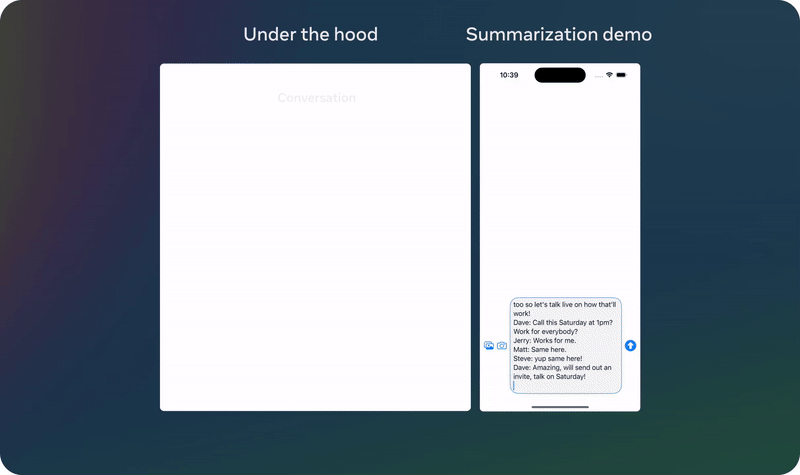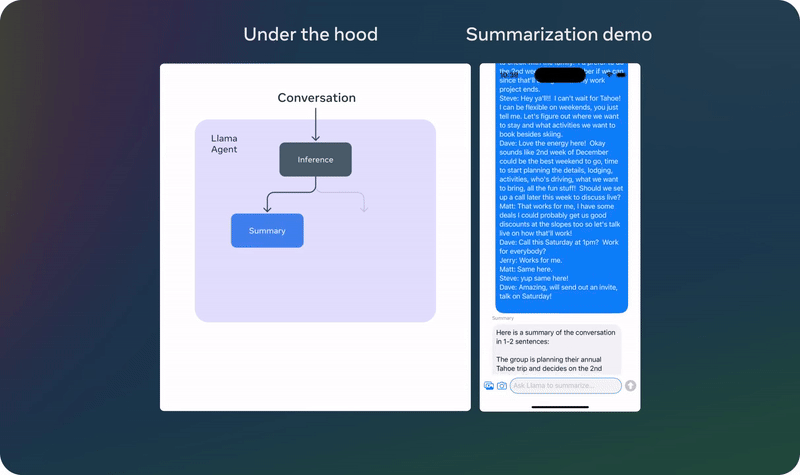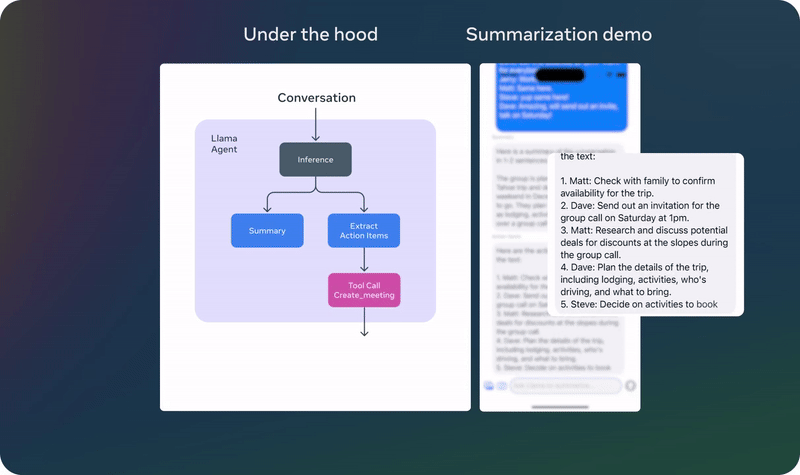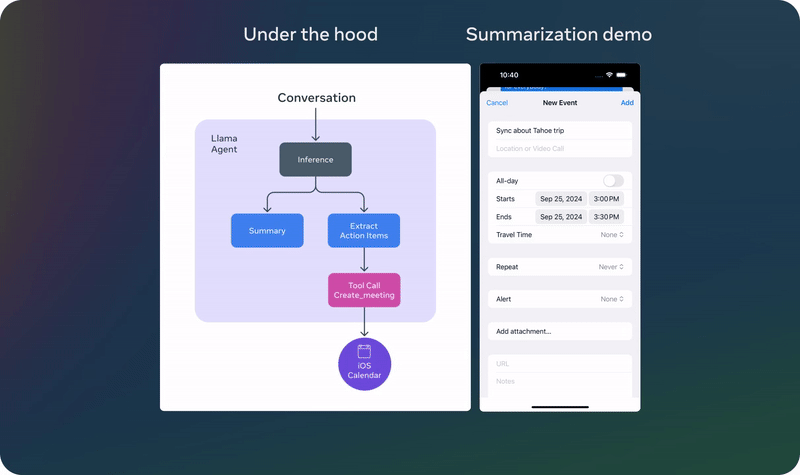
04 实例展示
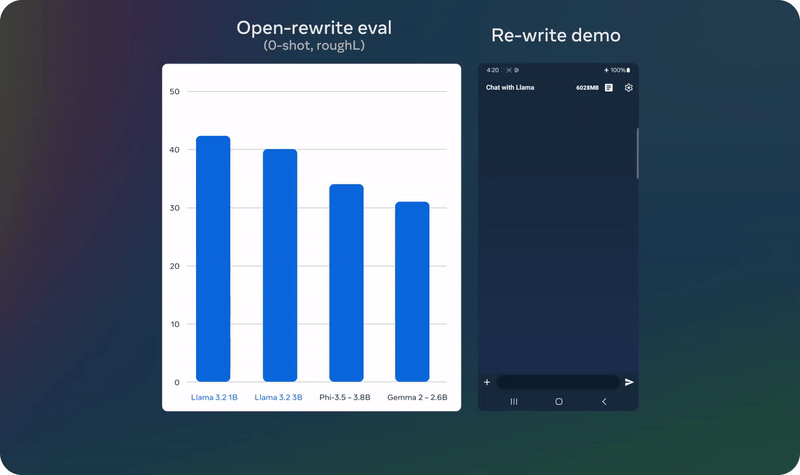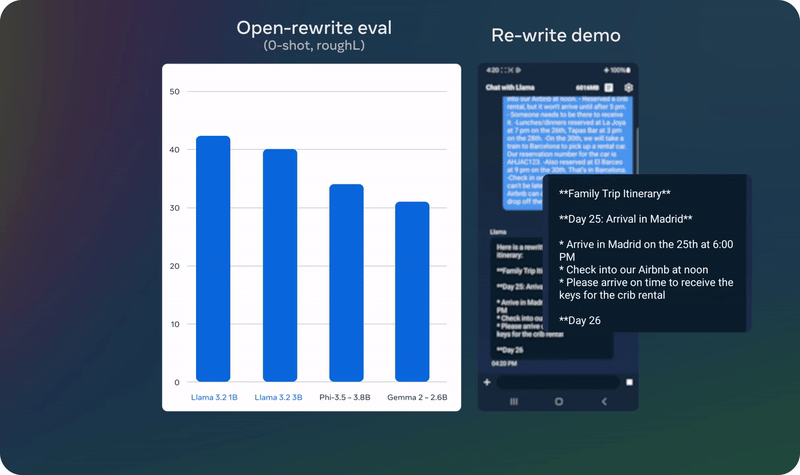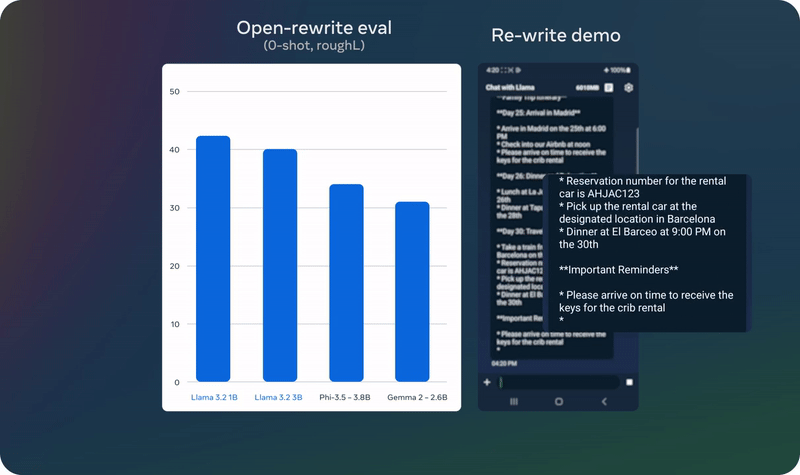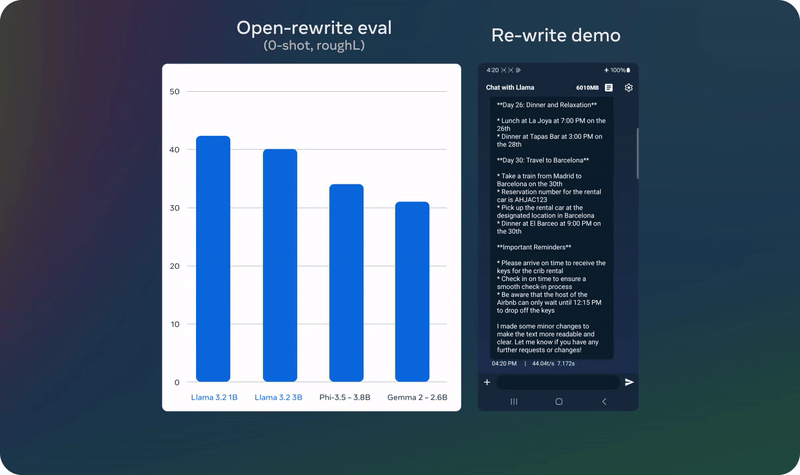
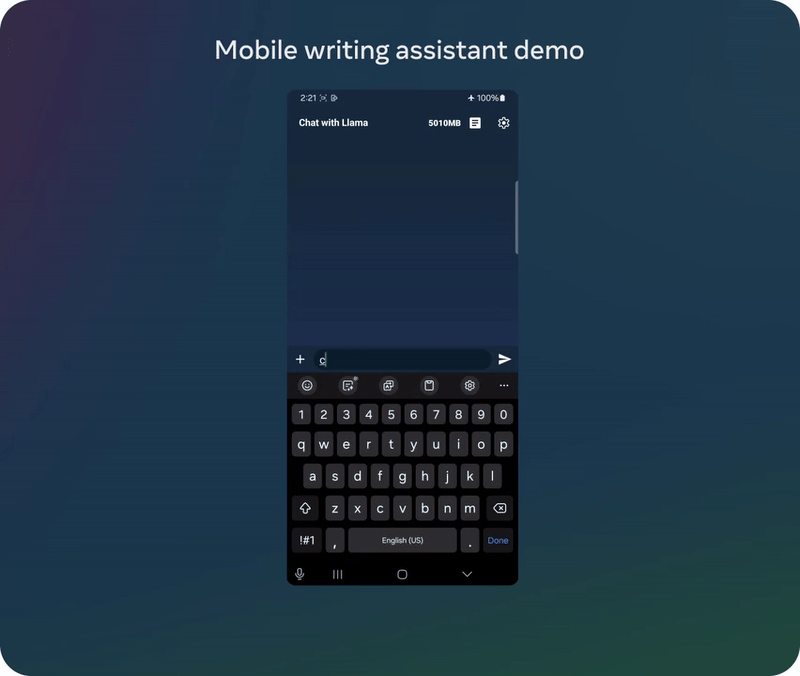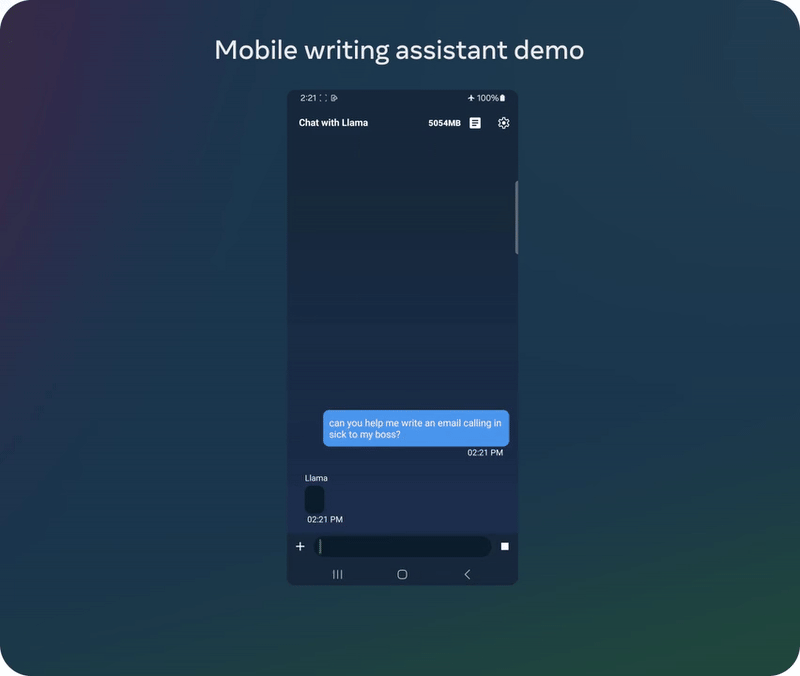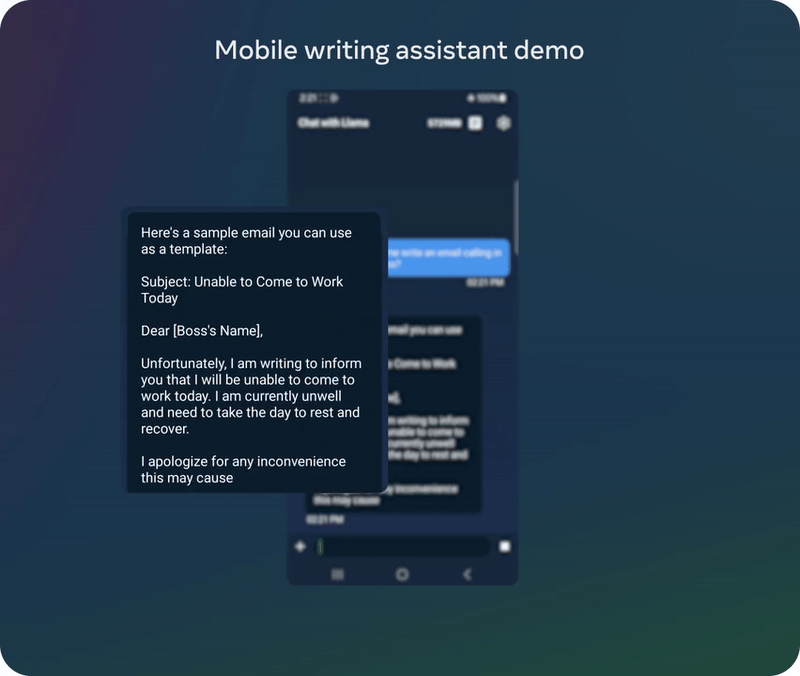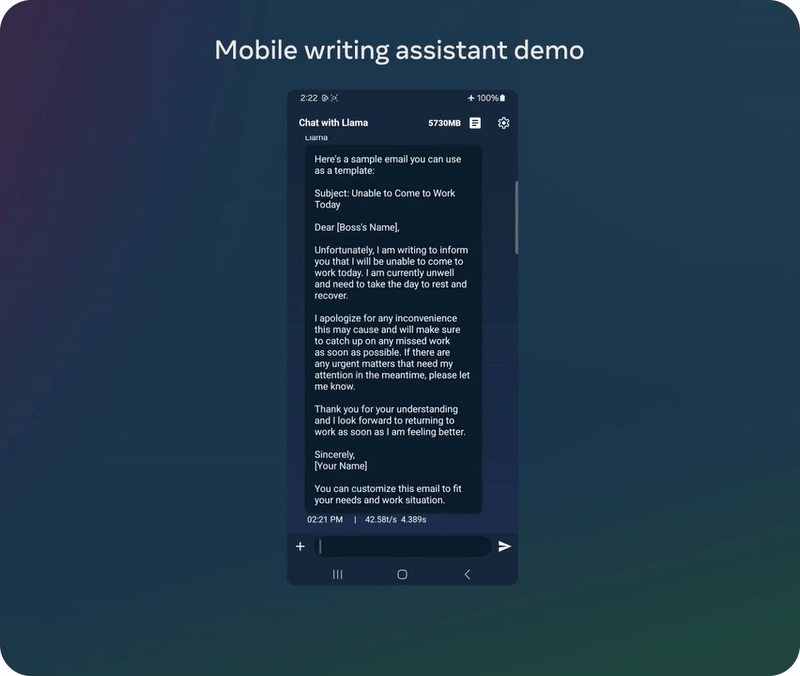
05 模型下载
传神社区:
https://opencsg.com/models/meta-llama/Llama-3.2-1B
https://opencsg.com/models/meta-llama/Llama-3.2-3B
huggingface:
https://huggingface.co/meta-llama/Llama-3.2-1B
https://huggingface.co/meta-llama/Llama-3.2-3B
欢迎加入传神社区
•贡献代码,与我们一同共建更好的OpenCSG
•Github主页
欢迎🌟:https://github.com/OpenCSGs
•Huggingface主页
欢迎下载:https://huggingface.co/opencsg
•加入我们的用户交流群,分享经验

扫描上方二维码添加传神小助手
“ 关于OpenCSG
开放传神(OpenCSG)成立于2023年,是一家致力于大模型生态社区建设,汇集人工智能行业上下游企业链共同为大模型在垂直行业的应用提供解决方案和工具平台的公司。
关注OpenCSG

加入传神社区


















 124
124

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









