







司南评测集社区 CompassHub 作为司南评测体系的重要组成部分,旨在打造创新性的基准测试资源导航社区,提供丰富、及时、专业的评测集信息,帮助研究人员和行业人士快速搜索和使用评测集。
2025 年 2 月,司南评测集社区新收录了近 30 个评测基准,覆盖多模态、具身智能和推理等方向。以下为部分新增评测集的介绍,欢迎大家下载使用。
司南评测集社区链接:
https://hub.opencompass.org.cn/home
MM-IQ
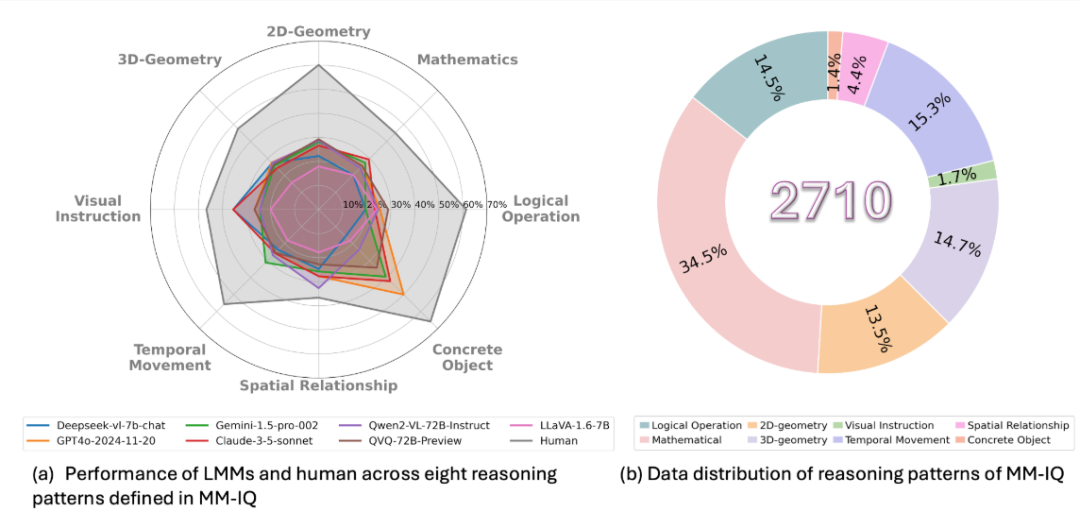
发布单位:
Tencent Hunyuan Team
发布时间:
2025-02-02
评测集简介:
MM-IQ 是一个多模态评估基准,包含 2,710 个测试题,涵盖了 8 种不同的推理范式:逻辑运算、数学、2D几何、3D几何、视觉指令、Temporal Movement、空间关系和 Concrete Object。评测结果显示,即使是最先进的大型多模态模型在这一基准上也仅达到 27.49% 的准确率,仅略高于随机猜测(25%),但远低于人类(高中及以上学历)平均水平表现(51.27%)。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/MM-IQ
BenchMAX
发布单位:
National Key Laboratory for Novel Software Technology, Nanjing University, etc.
发布时间:
2025-02-11
评测集简介:
BenchMAX 是一个全面、高质量的多向并行多语言基准,包含 10 个任务,旨在评估 17 种不同语言的关键能力。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/BenchMAX
ZeroBench
发布单位:
University of Cambridge, University of Alberta,etc.
发布时间:
2025-02-13
评测集简介:
ZeroBench 是一个具有挑战性的视觉推理基准测试,专为大型多模态模型(LMMs)设计。它由 100 个高质量、手动策划的主要问题集组成,涵盖了多个领域、推理类型和图像类型。ZeroBench 中的问题经过精心设计和校准,其难度超出了当前前沿模型的能力范围,所有评估的模型均未能达到 non-zero pass@1 (with greedy decoding) 或 5/5 reliability score。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/ZeroBench
EmbodiedBench
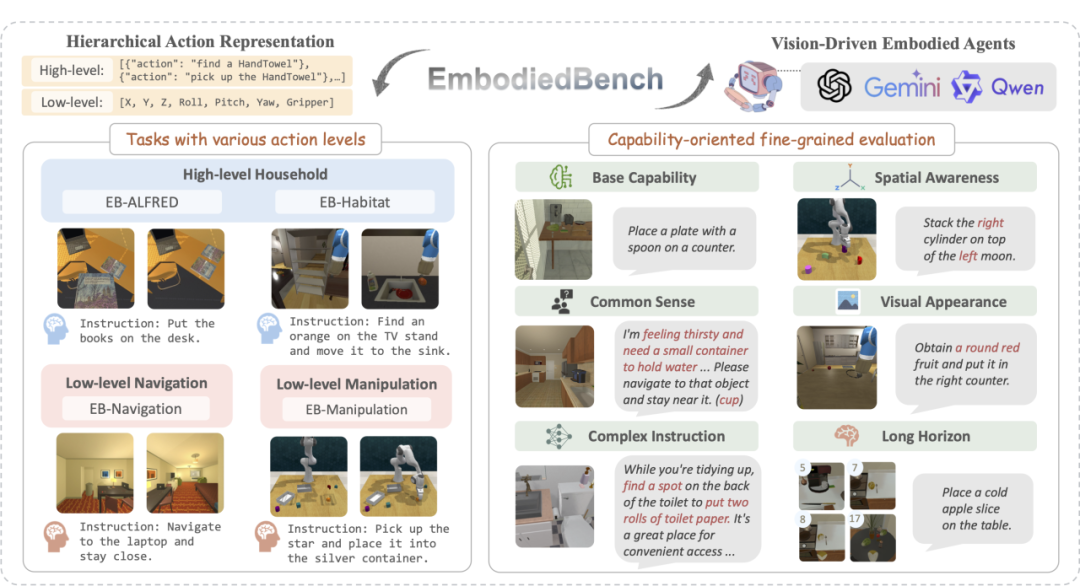
发布单位:
University of Illinois Urbana-Champaign, etc.
发布时间:
2025-02-13
评测集简介:
EmbodiedBench 是一个全面评估多模态大语言模型在视觉驱动具身智能任务中能力的基准测试集,包含 1,128 个测试任务,从高级任务(EB-ALFRED 和 EB-Habitat)到低级任务(EB-Navigation 和 EB-Manipulation)。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/EmbodiedBench
MME-CoT
发布单位:
CUHK MMLab, CUHK MiuLar Lab, ByteDance, etc.
发布时间:
2025-02-13
评测集简介:
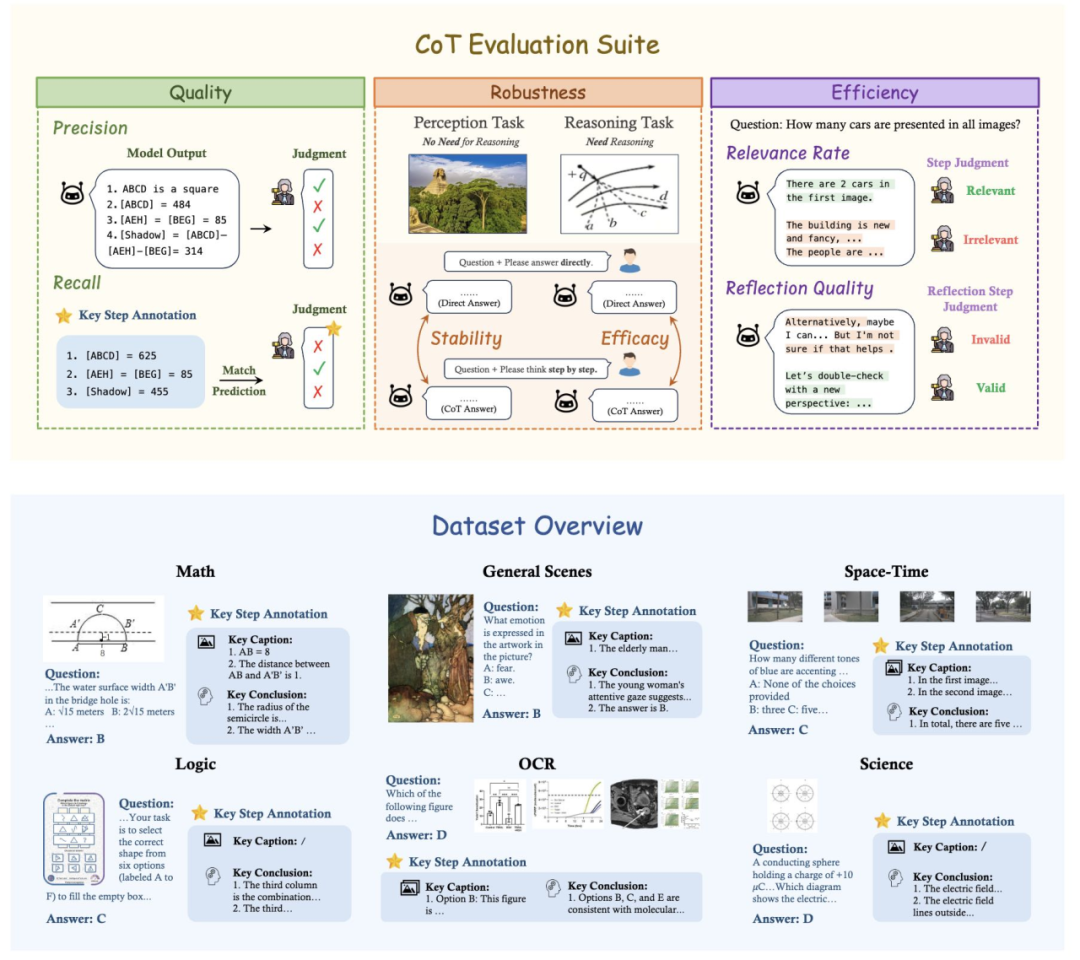
MME-CoT,一个专门用于评估 LMMs CoT 推理性能的基准,涵盖六个领域:数学、科学、OCR、逻辑、时空和一般场景。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/MME-CoT
PhysReason

发布单位:
Xi’an Jiaotong University, etc.
发布时间:
2025-02-17
评测集简介:
PhysReason是一个包含 1,200 个物理学科问题的综合性基准测试集,旨在评估大型语言模型(LLMs)的物理推理能力。该测试集分为知识型(25%)和推理型(75%)问题,覆盖范围 147 个物理定理,其中 81% 的问题包含图表,推理型问题分为简单、中等和困难三个等级。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/PhysReason
VLM2-Bench
发布单位:
HKUST, CMU, MIT
发布时间:
2025-02-17
评测集简介:
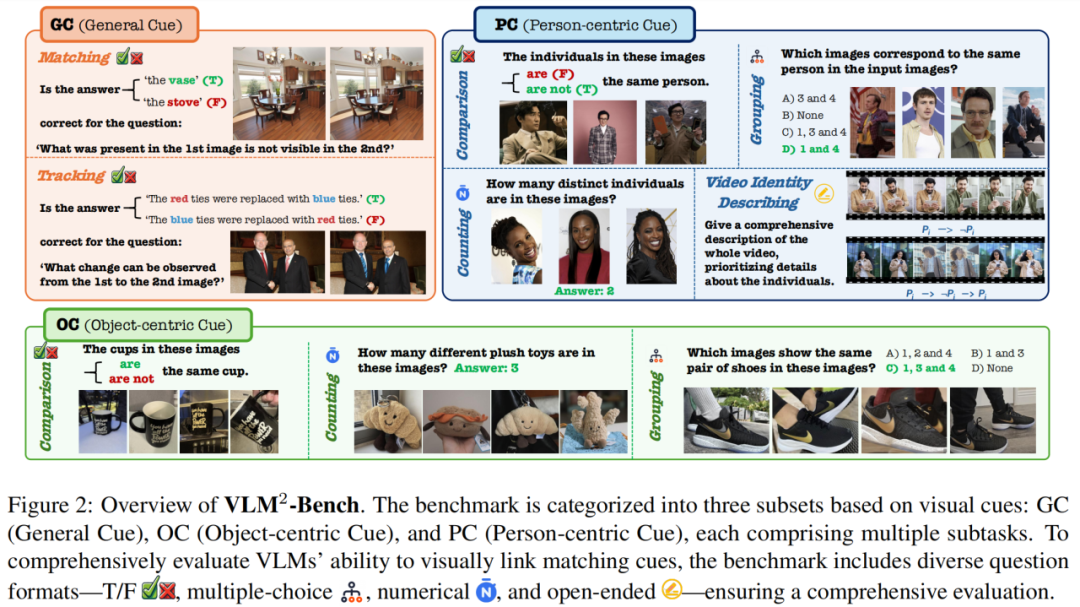
VLM²-Bench 是一个全面评估视觉语言模型(VLMs)在多图像序列和视频中视觉链接匹配线索能力的基准。该基准包括 9 个子任务,超过 3000 个测试案例。综合评估结果表明,即使是 GPT-4o 这样的先进模型在这类基础视觉任务上也比人类表现低 34.80 %,突显了多模态大模型在视觉线索关联方面的重大挑战。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/VLM2-Bench
Text2World
发布单位:
HKU, HIT, Shanghai AI Laboratory, etc.
发布时间:
2025-02-18
评测集简介:
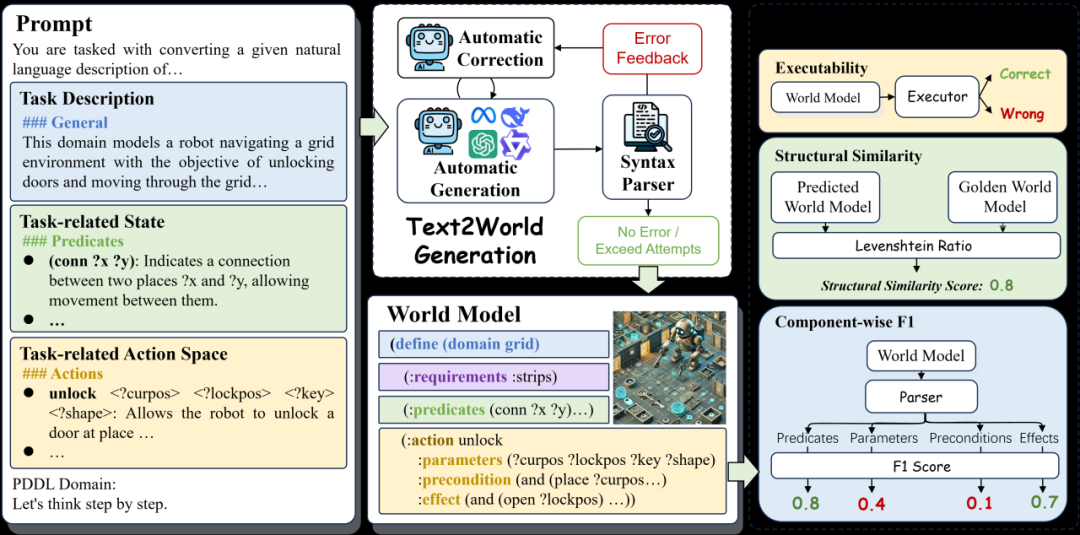
Text2World 基于规划领域定义语言 (PDDL),拥有数百个不同的领域,并采用多标准、基于执行的衡量标准来进行更鲁棒的评估大型语言模型(LLMs)从文本描述生成符号化世界模型能力。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/Text2World
MVL-SIB

发布单位:
University of Würzburg, University of Hamburg
发布时间:
2025-02-18
评测集简介:
MVL-SIB 是一个大规模多语言视觉-语言基准测试集,提供了涵盖 205 种语言和 7 个主题类别(如娱乐、地理、健康、政治、科技、体育和旅游)图文对。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/MVL-SIB
JL1-CD

发布单位:
Beijing National Research Center for Information Science and Technology,etc.
发布时间:
2025-02-19
评测集简介:
JL1-CD 是一个面向遥感影像变化检测的高分辨率、开源评测数据集。它包含 5000 对 512×512 像素的卫星影像,分辨率为 0.5 至 0.75 米,覆盖中国多个地区的各种地表变化。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/JL1-CD
SuperGPQA
发布单位:
M-A-P,ByteDance , 2077.AI
发布时间:
2025-02-20
评测集简介:
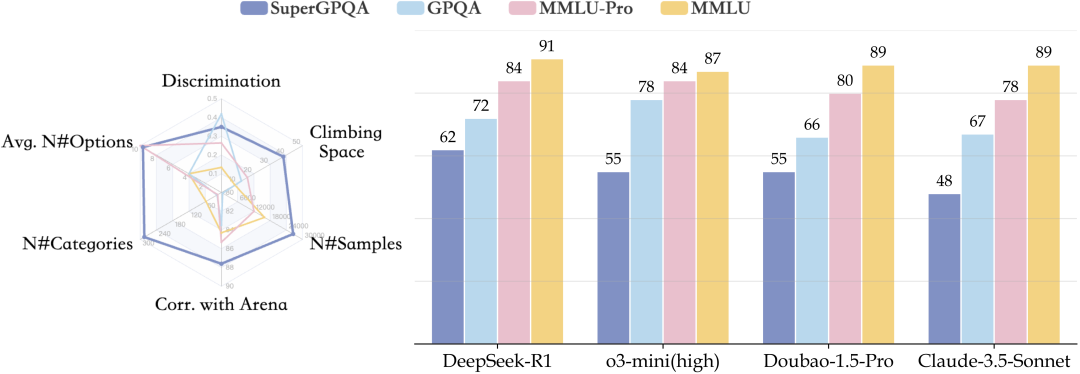
SuperGPQA 是一个全面的评测集,旨在评估大型语言模型(LLMs)在涵盖 285 个研究生级别学科的知识与推理能力,包含 26,529 个问题,覆盖 13 大学科、72 个领域及 285 个子领域,即使表现最佳的模型(如 DeepSeek-R1,准确率 61.82%)仍有较大改进空间。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/SuperGPQA
MedHallu
发布单位:
University of Texas at Austin, UNC Chapel Hill, Drexel University
发布时间:
2025-02-20
评测集简介:
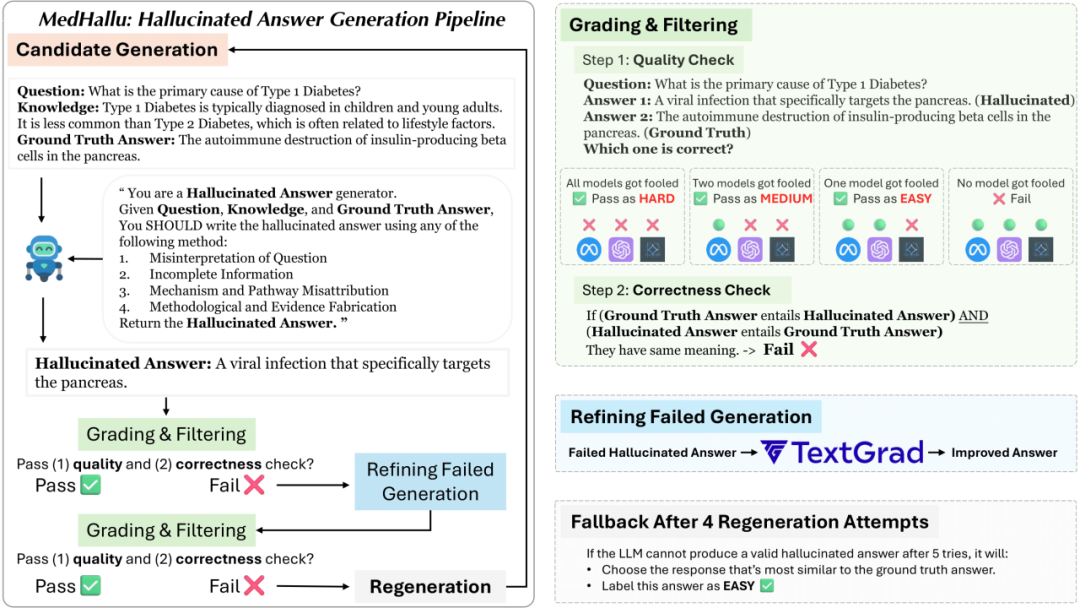
MedHallu 是一个专为检测大型语言模型(LLMs)在医疗领域中的幻觉现象而设计的综合性基准数据集,包含从 PubMedQA 衍生的 10,000 个高质量问答对,数据集通过受控生成流程系统性地引入幻觉答案,并按检测难易度分为简单、中等和困难三个层次。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/MedHallu
CodeCriticBench
发布单位:
NJU,M-A-P, etc.
发布时间:
2025-02-23
评测集简介:
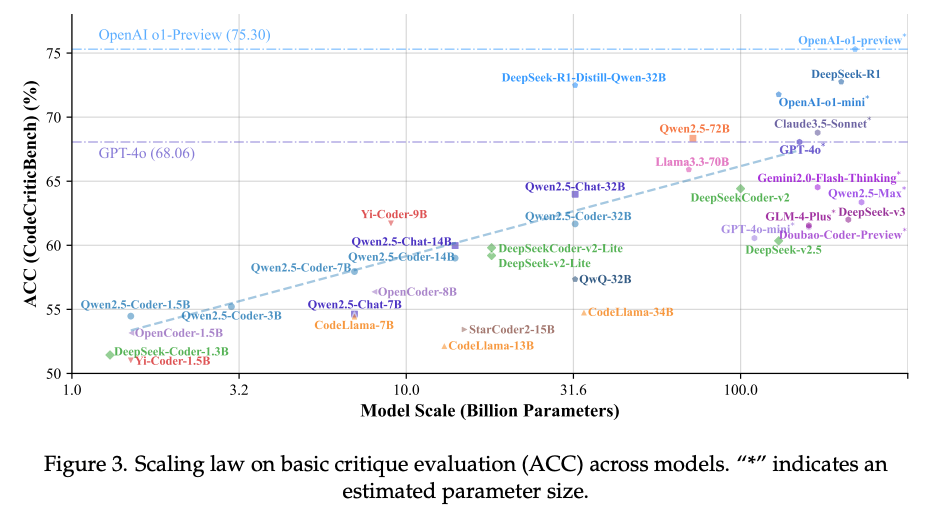
CodeCriticBench 是一个针对大型语言模型(LLMs)代码批判能力的全面评测基准,该评测集包含代码生成与代码问答两大主流任务,共计4300个样本,涵盖简单、中等和困难三种难度级别。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/CodeCriticBench
KITAB-Bench
发布单位:
MBZUAI,etc.
发布时间:
2025-02-20
评测集简介:
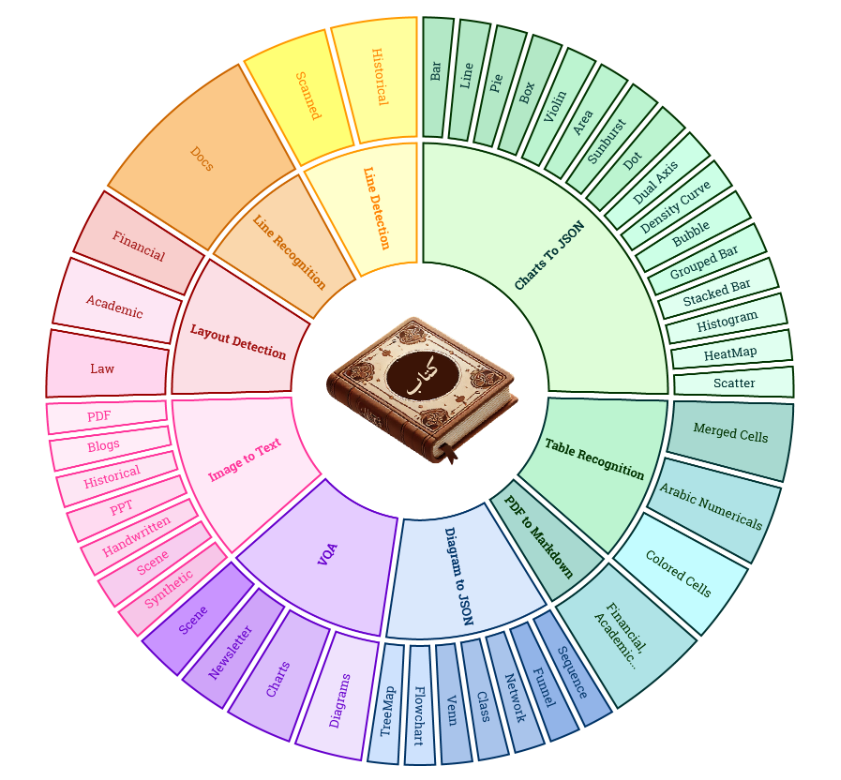
KITAB-Bench是一个全面多领域阿拉伯文 OCR 和文档理解基准,包含 36 个子领域,超过 8,809 个样本,经过精心挑选,以严格评估阿拉伯文 OCR 和文档分析所需的基本技能,研究表明现代视觉-语言模型(如 GPT-4、Gemini 和 Qwen)在字符错误率(CER)方面比传统 OCR 方法(如 EasyOCR、PaddleOCR 和 Surya)平均高出 60%, 领先模型 Gemini-2.0-Flash 也仅达到 65% 的准确率,体现了在准确识别阿拉伯语文本方面的挑战。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/KITAB-Bench
StructFlowBench

发布单位:
Jilin University, etc.
发布时间:
2025-02-20
评测集简介:
StructFlowBench 是一个集成多轮结构流框架的新型指令跟随基准,研究团队使用该框架对 13 个领先的开源和闭源大语言模型进行了系统性评估。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/StructFlowBench
PosterSum
发布单位:
University of Edinburgh
发布时间:
2025-02-24
评测集简介:
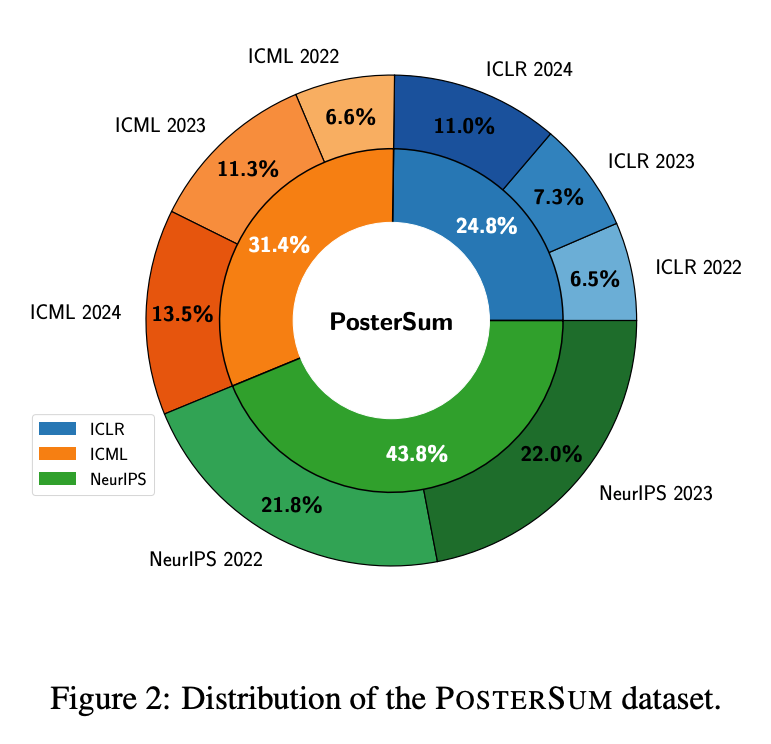
PosterSum 数据集是一个多模态基准数据集,包含从 2022-2024 年的主要机器学习会议(包括 ICLR、ICML 和 NeurIPS)收集的 16,305 篇学术海报,涵盖了 137 个不同研究主题。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/PosterSum
MM-AlignBench
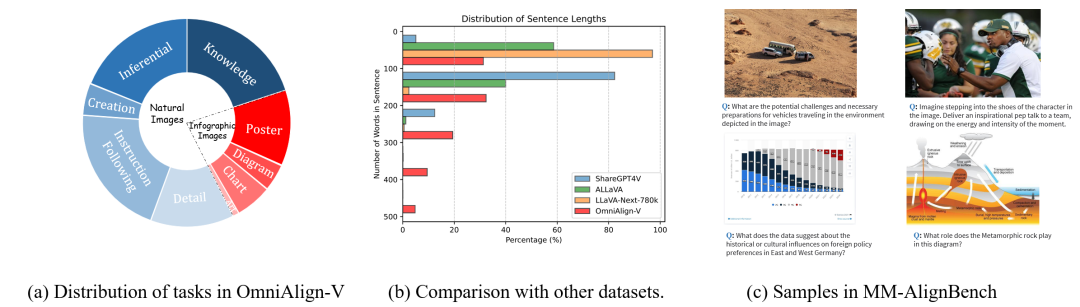
发布单位:
Shanghai Jiaotong University,Shanghai AI Laboratory,etc.
发布时间:
2025-02-25
评测集简介:
MM-AlignBench 是一个专门设计用于评估多模态大语言模型(MLLMs)与人类偏好对齐能力的高质量基准测试集,该评测集包含 252 个样本,涵盖多样化的图像来源和问题类型,评估方式采用 GPT-4o 作为评判模型。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/MM-AlignBench
MMKE-Bench

发布单位:
BIGAI, USTC, PKU, BIT
发布时间:
2025-02-27
评测集简介:
MMKE-Bench是一个综合性多模态知识编辑基准,旨在评估大型多模态模型(LMM)在真实场景中编辑各类视觉知识的能力,包括 33 个广泛类别中的 2,940 条知识和 8,363 张图像。
评测集社区链接:
https://hub.opencompass.org.cn/dataset-detail/MMKE-Bench

















 851
851

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









