






近日,上海人工智能实验室(上海AI实验室)联合复旦大学、博观创新(上海)大数据有限公司共同开源大规模学术成果数据库“智创”(Intelligent Innovation Dataset)。数据库涵盖数亿条学术论文、科研项目、专利信息等多种类型的学术成果数据,历史跨度120余年。
数据作为学术研究的重要基础设施,其共享与流通是推动科学进步的关键因素之一。智创数据库可用于量化研究成就,揭露学术趋势,剖析合作模式,评价学科演化及项目资助情况,辅助科学政策制定。助力研究者深入洞察科学领域的内在结构、发展动态及其影响力,赋能知识的流传与学术创新。
与此同时,数据库中的专利信息是助力技术创新和市场竞争力分析的优质数据,助力监测技术动向,评估并保护知识产权,指导研发活动,辅助市场策略,优化专利措施,为政策优化和学术研究提供坚实的实证支持。
● 数据集下载链接:https://opendatalab.com/Gracie/IIDS
● 数据集论文引用链接:https://doi.org/10.48550/arXiv.2409.06936
一、智创数据库介绍
智创数据库由复旦大学社会智能研究中心、博观创新(上海)大数据科技有限公司以及上海人工智能实验室共同开发。
智创数据库强调用数据展现科技创新的全景,广泛地涵盖了科研成果和专利相关数据,目前主要包括学术论文、科研项目、专利等多种类型的学术成果数据。目前数据库规模为735.1GB,其中论文数据量9231万余条,论文引用关系信息数据量18亿余条;科研基金信息数据量3万余条,论文基金关系6128万余条;专利数据量1亿余条,专利法律状态相关数据1.1亿余条。特点如下:
● 覆盖范围广:智创数据库涵盖了自然学科、医学、社会科学、生命科学四大类,27个大学科,334个小学科,收录内容全面且广泛。
● 收录内容丰富:不仅收录了期刊文章,还包括会议论文以及欧洲专利局提供的全世界各国专利数据,为研究者提供了全面的知识产权信息。
● 超长历史跨度:智创数据库包含了120余年(参与计算数据)的来自不同国家的论文、专利等详细信息,为用户提供了广泛的研究视角和历史数据参考。
总的来说,智创数据库凭借其广泛的数据覆盖范围、专利数据的集成,以及开放获取的特点,为学术研究提供了便捷的一站式信息服务,有望成为全世界从事相关研究的科研人员的重要资源。
二、数据组成
智创数据库中一共包含六张表,分别是paper表、paper引用关系表、funding表、funding关系表、patent表和patent法律状态表,具体内容如下:
(1)paper表和paper引用关系表:
内含期刊论文数据,包括学者在正规系统收录的期刊中正式发表的英文论文以及与论文相关的会议数据、文章引用关系数据。未正式发表的、在预发表数据库中的、非期刊出版的网络文章、发表状态为“Online”的期刊论文等情况均不在收录范围内。此数据主要来源于Scopus数据库。
(2)funding表和funding关系表:
包含全球主要国家发布的科研项目信息,主要来源为美国、中国、日本、加拿大等国家,比如中国的自然科学基金项目、社会科学基金项目等。关系表包含论文与基金之间的连接关系,同时还包含基金的部分信息。
(3)patent表和patent法律状态表:
仅包含专利数据、专利每阶段法律信息,分为有效专利、有价值专利两类进行不同模型计算。主要来源于欧洲专利局官网的专利数据,覆盖范围从1950年至今。(https://worldwide.espacenet.com/)
三、数据样例
(1) paper表和paper引用关系表
● paper表(表1)
包含了从1900年到2023年期间的9200多万条论文记录。其中包括论文的标题、摘要、期刊信息、作者信息、被引用次数以及发表年份等重要数据,同时还涵盖了不同类型和语种的论文。具体字段请参见表1,其中字段eid具有唯一性,可用于实现数据集中多个表的交叉引用。
表1 entity_paper
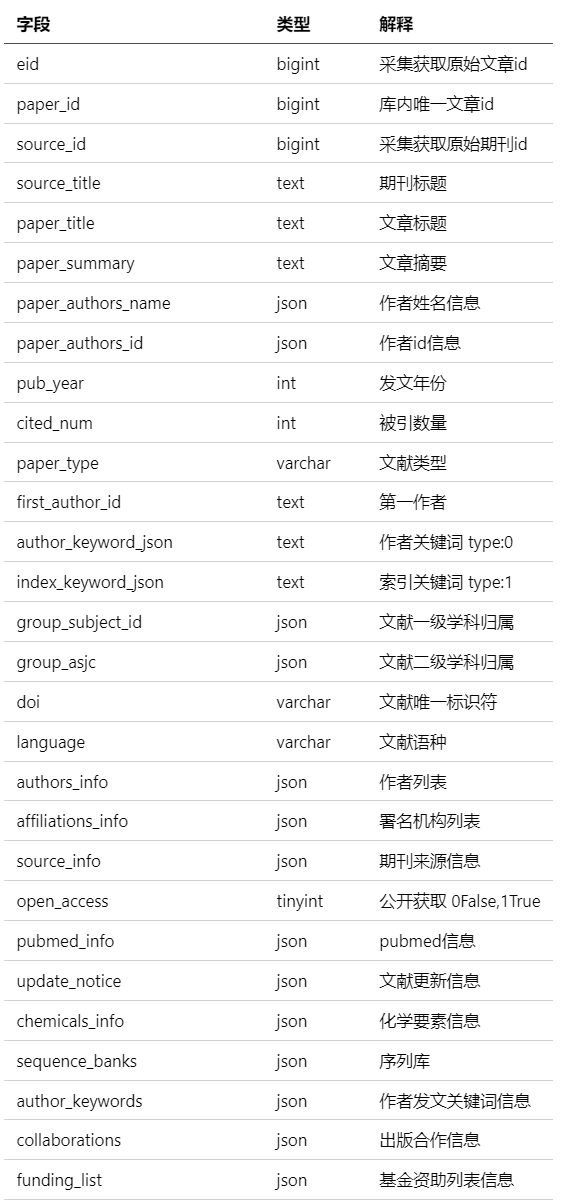

(篇幅有限,此处样例未展示,完整信息可查看论文:https://arxiv.org/pdf/2409.06936)
● paper引用关系表(表2)
包含了引文关系。包含了来自表1(entity_paper)的论文引用关系,分为 ref_id和cited_id(本质上都是eid)。可以通过eid与表1 进行匹配。
表 2 reference_citation_re

(2) funding表和funding关系表
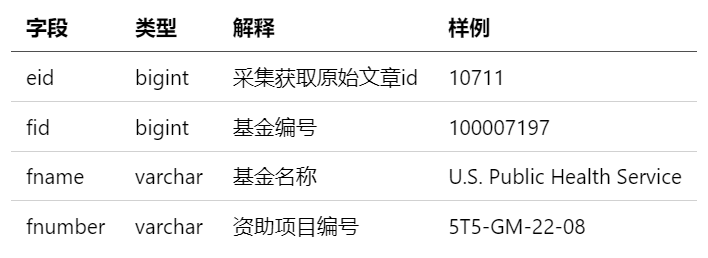
● funding关系表(表3)
包含与论文相关的资助信息,可根据“eid”与表1(entity_paper)匹配,根据“fid”(即“findid”)与funding表4(entity_fund_info)匹配。
表 3 entity_funds_re
● funding表(表4)
包含25840条基金相关信息,包括基金类型、创建时间、基金官网、基金描述等。它收集了截至2021年来自157个国家的基金信息。可以使用“fundid”与表3 (entity_funds_re)进行匹配。值得注意的是,“fundid”以JSON格式出现在表1 (entity_paper)的funding_list列中。
表4 entity_fund_info
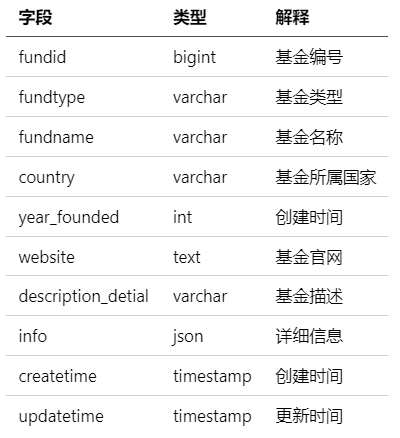
(篇幅有限,此处样例未展示,完整信息可查看论文:https://arxiv.org/pdf/2409.06936)
(3) patent表和patent法律状态表
● patent表(表5)
包含近1亿条专利相关数据,其中包括专利号、专利标题、申请人、申请年份等重要信息。
表5 base_patent_detail
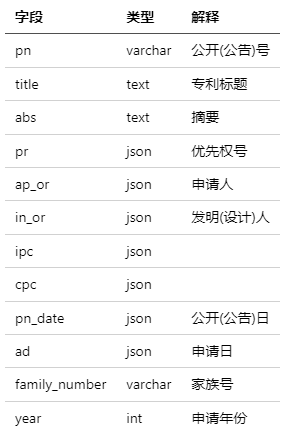
(篇幅有限,此处样例未展示,完整信息可查看论文:https://arxiv.org/pdf/2409.06936)
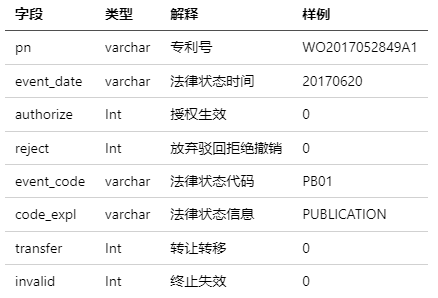
● patent法律状态表 (表6)
包含专利各阶段法律信息。它可以使用“pn”与表5 (base_patent_detail)匹配。
表6 base_patent_law_status
四、数据处理方法
为保证数据的规范性,对数据进行了清洗、整合处理,以保证数据质量满足要求。主要数据处理手段包括冗余数据处理、数据缺失处理、异常值处理、数据整合、数据子集摘取。
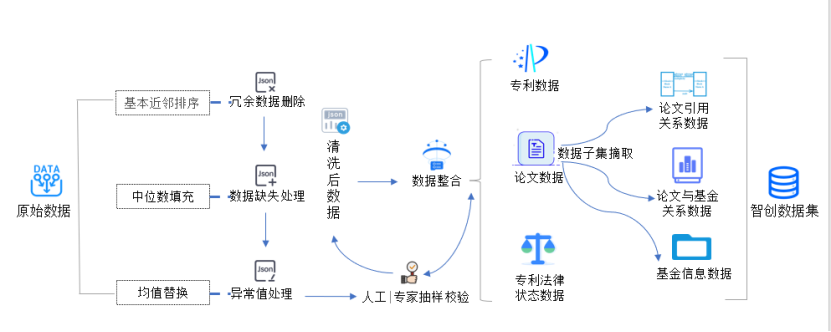
(1)冗余数据处理:根据数据标准要求,对输入的数据字段进行比对判别,将重复冗余字段和数据自动删除。
(2)数据缺失处理:由于系统异常、人工录入失误等因素,可能存在某些记录缺失,针对此情况提供灵活的数据补足方式。
(3)异常值处理:根据判定规则进行数据的自动判断与处理,支持设置业务规则,并按照业务规则进行处理,如将异常值剔除,或者设为均值等等。
(4)数据分类整合: 对论文、专利等不同类型数据进行整合处理解决重复性、一致性、唯一性问题:
● 对全球主流期刊上发表的论文数据进行了整合,尤其是解决了不同来源的期刊论文重复的问题。同时,还解决了因字符串差异而导致的错误识别重复论文的问题。
● 对全球主要学术会议上发表的论文数据进行了整合,重点解决向不同会议上投稿相同论文的重复性问题。
● 对全球专利数据进行了整合,对相同优先权在不同国家申请和授权的专利进行去重,确保专利内容的一致性。
● 对全球各个国家的科研基金信息数据进行了整合,对不同来源的科研项目数据进行去重,确保数据的唯一性。
(5)数据子集摘取:在使用或分析大数据时,可能需要只摘取部分数据,通过数据子集摘取来实现该功能。
五、许可
智创数据库整体采用Apache 2.0 许可协议。
● 数据集下载链接:https://opendatalab.com/Gracie/IIDS
● 数据集论文引用链接:https://doi.org/10.48550/arXiv.2409.06936


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









