







基于深度学习的医学图像分割模型研究_曹祺炜
1.基于改进的3D-FCN+CRF以及MS-CapsNetGAN实现脑肿瘤图像分割
图像语义分割,简单而言就是给定一张图片,对图片上的每一个像素点分类,不同颜色代表不同类别。图像分割的主要步骤:图像预处理、数据准备以及图像特征提取、分类器分类和后期处理。前端使用FCN进行特征粗提取,后端使用CRF/MRF优化前端的输出,最后得到分割图。
- FCN-全卷积网络
此处的FCN主要使用了三种技术:卷积化(Convolutional),上采样(Upsample),跳跃结构(Skip Layer)。
卷积化即是将普通的分类网络丢弃全连接层,换上对应的卷积层即可。上采样即是反卷积,框架不同名字不同,Caffe和Kera里叫Deconvolution,而tensorflow里叫conv_transpose。忽略连接结构的作用就在于优化结果,因为如果将全卷积之后的结果直接上采样得到的结果是很粗糙的,所以作者将不同池化层的结果进行上采样之后来优化输出。
- MRF-马尔科夫随机场
随机场是由若干个位置组成的整体,当给每一个位置中按照某种分布随机赋予一个值之后,其全体就叫做随机场。举词性标注的例子:假如我们有一个十个词形成的句子需要做词性标注。这十个词每个词的词性可以在我们已知的词性集合(名词,动词...)中去选择。当我们为每个词选择完词性后,这就形成了一个随机场。
马尔科夫随机场是随机场的特例,它假设随机场中某一个位置的赋值仅仅与和它相邻的位置的赋值有关,和与其不相邻的位置的赋值无关。继续举十个词的句子词性标注的例子:如果我们假设所有词的词性只和它相邻的词的词性有关时,这个随机场就特化成一个马尔科夫随机场。比如第三个词的词性除了与自己本身的位置有关外,只与第二个词和第四个词的词性有关。
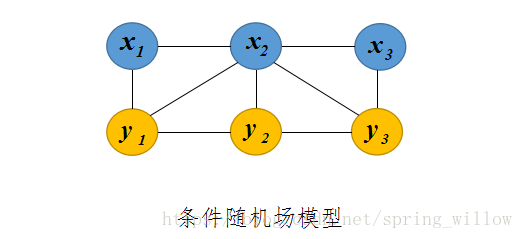
- CRF-条件随机场
CRF是马尔科夫随机场的特例,它假设马尔科夫随机场中只有和两种变量,一般是给定的,而一般是在给定的条件下我们的输出。这样马尔科夫随机场就特化成了条件随机场。在我们十个词的句子词性标注的例子中,是词,是词性。因此,如果我们假设它是一个马尔科夫随机场,那么它也就是一个CRF。
对于CRF,我们给出准确的数学语言描述:设与是随机变量,是给定时的条件概率分布,若随机变量构成的是一个马尔科夫随机场,则称条件概率分布是条件随机场。
①条件随机场保留了隐含马尔可夫模型的一些特性,比如图中的y1,y2,..y1,y2,..等状态的序列还是一个马尔可夫链。
②在图中,顶点x1,y1x1,y1代表一个个随机变量,顶点之间的弧代表他们之间的依赖关系,采用概率分布P(x1,y1)来描述。
③它的特殊性在于变量之间要遵守马尔可夫假设,即每个状态的转移概率只取决于相邻的状态,这一点,它和贝叶斯网络相同。不同之处在于贝叶斯网络是有向图,而条件随机场是无向图,
2.图像分割结果评判标准:
除对分割结果定性分析之外,对分割结果的定量比较显得更为重要。Dice 相似系数(Dice Similarity Coefficient, DSC)法被广泛应用于评估图像分割算法性能的度量,此外,准确率(Accuracy)、精确度(Precision)、召回率(Recall)、过分割率、欠分割率(Under-segmentation Error, UE)、真阳性率(True Positive Rate, TPR)和阳性预测值(positive predictive value, PPV)等指标也经常被用作评估算法的分割结果。 精确率指的是输出结果中正确像素点占总像素点的比例,召回率指的是正确像素点占传统人工分割结果中的比例,精确率与召回率的调和均值用 F1-score 表示,F1-score 值越高,则说明算法的分割效果越好,当 F1-score=1 时,表示试验所得的结果与参考标准一致。
https://blog.csdn.net/woshisunwen/article/details/84308996
3.图像分割方法的分类:基于阈值/边缘/区域/活动轮廓模型/模糊聚类算法/数学形态学/神经网络的图像分割
基于神经网络的图像分割:
通常,CNN 由卷积,池化和完全连接的神经网络层组成。卷积层利用空间相关性在输入图像中,通过共享滤波器内核权重来计算每个特征映射。池化层允许减少每个输入要素图的尺寸,同时保留最相关的要素响应。每个 CNN 层的输出通常馈送到非线性激活功能。使用非线性激活函数允许我们在输入图像和期望输出之间建模非常复杂的映射。
CNN 的一个缺点是当卷积特征被馈送到网络的完全连接层时,图像的空间信息丢失。然而,空间信息对于语义分割任务尤其重要。因此,Long 等人提出全卷积网络FCN 克服这个限制。在 FCN 中,CNN 的最终密集连接层由转置卷积层代替,以便将学习的上采样应用于网络内的低分辨率特征映射。该操作可以在执行语义分割的同时恢复输入图像的原始空间维度。类似的网络结构已成功应用于医学成像中的语义分割任务和生物医学图像的分割。从共聚焦显微镜等模式扩展到 3D 生物医学成像数据或磁共振成像。在典型的 FCN 架构中,可以利用跳过连接来连接网络的不同级别,以便保留更接近原始图像的图像特征。这有助于网络实现更详细的分割结果。
https://blog.csdn.net/caoniyadeniniang/article/details/76014526
4.模糊聚类算法FCM(FCM算法是目前比较流行的一种模糊聚类算法)
- (1)基于模糊关系的分类法:其中包括谱系聚类算法(又称系统聚类法)、基于等价关系的聚类算法、基于相似关系的聚类算法和图论聚类算法等等。它是研究比较早的一种方法,但是由于它不能适用于大数据量的情况,所以在实际中的应用并不广泛。
- (2)基于目标函数的模糊聚类算法:该方法把聚类分析归结成一个带约束的非线性规划问题,通过优化求解获得数据集的最优模糊划分和聚类。该方法设计简单、解决问题的范围广,还可以转化为优化问题而借助经典数学的非线性规划理论求解,并易于计算机实现。因此,随着计算机的应用和发展,基于目标函数的模糊聚类算法成为新的研究热点。
- (3)基于神经网络的模糊聚类算法:它是兴起比较晚的一种算法,主要是采用竞争学习算法来指导网络的聚类过程。
5.体素
体素是体积元素(Volume Pixel)的简称,包含体素的立体可以通过立体渲染或者提取给定阈值轮廓的多边形等值面表现出来。一如其名,是数字数据于三维空间分割上的最小单位,体素用于三维成像、科学数据与医学影像等领域。
体素成像是一种在二维图像显示器上显示体数据的方法。这些体数据可能是在三维空间物体采样的结果,例如人脑的磁共振图像。通过体素成像,三维空间采样点的集合可以转换成计算机二维屏幕上有意义的图像。体素成像与传统图形显示方法的思想截然不同,它的最大特点就在于放弃了传统图形学中体由面构造这一约束,在不构造物体表面几何描述的情况下直接对体数据进行显示,采用体绘制光照模型直接从三维数据场中绘制出各种物理量的分带晴况,也就是说,直接研究光线穿过三维体数据场时的变化,得到最终的绘制结果。能够描述物体内部结构是体素成像最大的优势。
6.胶囊网络
解决了CNN的问题:CNN的组件的朝向和空间上的相对关系对它来说不重要,它只在乎有没有特征。还有就是池化层:不仅减少了参数,还可以避免过拟合。但是,它的确抛弃了一些信息,比如位置信息。同一物体,尽管拍摄的角度不同,但你的大脑可以轻易的辨识这是同一对象,CNN却没有这样的能力。所以,CapsNet应运而生。
例如输入一张手写字的图片。首先对这张图片做了常规的卷积操作,得到ReLU Conv1;然后再对ReLU Conv1做卷积操作,并将其调整成适用于CapsNet的向量神经元层PrimaryCaps,而不是以往的标量神经元。
神经网络和胶囊网络区别: 神经网络每个神经元输出的是一个标量,胶囊网络输出是一个向量。所谓胶囊就是一个向量,它可包含任意个值,每个值代表了当前需要识别的物体的一个特征。结合之前对传统CNN的学习,我们知道,卷积层的每个值,都是上一层某一块区域和卷积核完成卷积操作,即线性加权求和的结果,它只有一个值,所以是标量。而我们的胶囊网络,它的每一个值都是向量,也就是说,这个向量不仅可表示物体的特征、还可以包括物体的方向、状态等。
PrimaryCaps到DigitCaps层的传播也就是CapsNet和以往CNN操作的最大区别。DigitCaps中一共10个向量,每个向量中元素的个数为16。对这10个向量求模,求得模值最大的那个向量代表的就是图片概率最大的那个分类。因为胶囊网络中:用向量模的大小衡量某个实体出现的概率,模值越大,概率越大。















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









