







/1 SE-Net《Squeeze-and-Excitation Networks》
Jie Hu, Li Shen, and Gang Sun. Squeeze-and-excitation networks. In IEEE Conf. Comput. Vis. Pattern Recog., pages 7132–7141, 2018
代码 https://github.com/miraclewkf/SENet-PyTorch
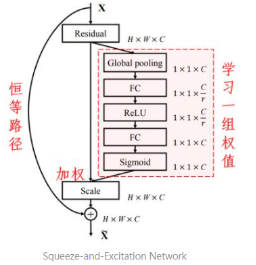
通过一个小型的子网络,自动获得一组权重,对各个特征通道进行加权
在数据含有较多噪声时,可以考虑把“特征加权”给换成“软阈值化”。
软阈值化是信号降噪算法的常用步骤。软阈值化的梯度,要么为0,要么为1,这是和ReLU一样的,也有利于避免梯度消失和爆炸
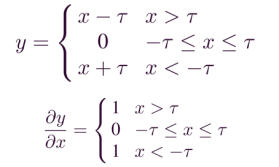
/2 《ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks》
Qilong Wang, Banggu Wu, Pengfei Zhu, Peihua Li, Wangmeng Zuo, and Qinghua Hu. Eca-net: Effificient channel attention for deep convolutional neural networks. In IEEE Conf. Comput. Vis. Pattern Recog., pages 11534–11542, 2020.
代码 https://github.com/BangguWu/ECANet
基于SE-Net的扩展,其认为SE block的两个FC层之间的维度缩减是不利于channel attention的权重学习的,这个权重学习的过程应该直接一一对应。
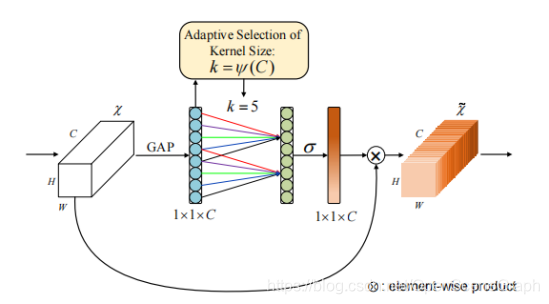
ECA-Net的做法为:(1)Global Avg Pooling得到一个1*1*C的向量;(2)通过一维卷积来完成跨channel间的信息交互。
一维卷积的卷积核大小通过一个函数来自适应,使得channel数较大的层可以更多地进行cross channel 交互。自适应卷积核大小k,γ= 2 , b = 1,odd表示t最接近的奇数。

***block的结构:(1)global avg pooling产生1 ∗ 1 ∗ C 大小的feature maps;(2)两个fc层(中间有维度缩减)来产生每个channel的weight。
***ECA-Net的结构:(1)global avg pooling产生1 ∗ 1 ∗ C 大小的feature maps;(2)计算得到自适应的kernel_size;(3)应用kernel_size于一维卷积中,得到每个channel的weight。
(ECA)模块图。考虑到由global average pooling (GAP)获得的聚合特征the aggregated features,ECA通过执行大小为k的快速一维卷积生成channel权值,其中k通过channel维数C的映射自适应确定。
/3 CBAM: Convolutional Block Attention Module
Sanghyun Woo, Jongchan Park, Joon-Young Lee, and In So Kweon. Cbam: Convolutional block attention module. In Eur. Conf. Comput. Vis., pages 3–19, 2018
代码 https://github.com/luuuyi/CBAM.PyTorch
基于SE-Net,该attention方法只关注了通道层面上哪些层会具有更强的反馈能力,但是在空间维度上并不能体现出attention的意思。CBAM作为本文的亮点,将attention同时运用在channel和spatial两个维度上,CBAM与SE Module一样,可以嵌入了目前大部分主流CNN网络中,在不显著增加计算量和参数量的前提下能提升网络模型的特征提取能力。
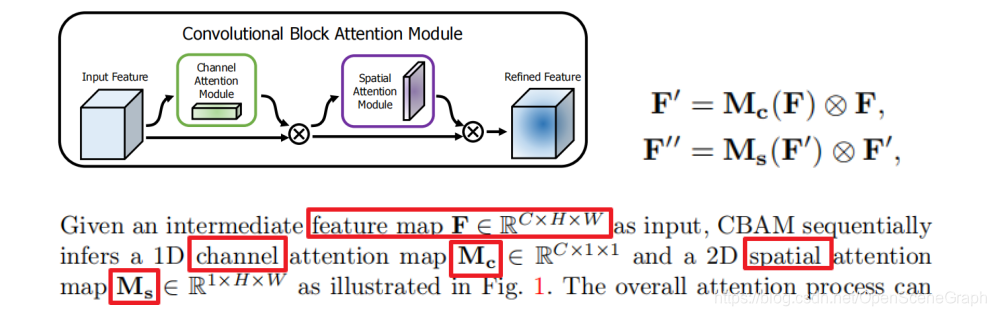
子模块:
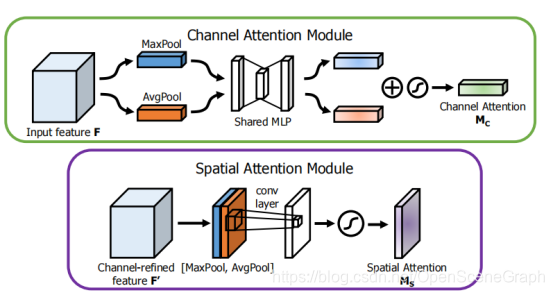
通道子模块在共享网络中同时利用了最大池化输出和平均池化输出。
空间子模块利用类似的两个输出,沿着通道轴汇集,并将它们传送到卷积层。
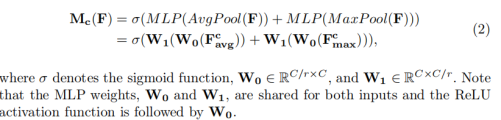
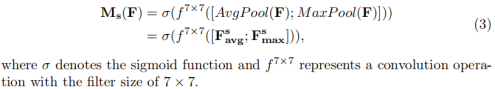

















 6136
6136

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









