






点击蓝字
关注我们,让开发变得更有趣
OpenVINO™
本文从搭建环境开始,一步一步帮助读者实现基于Stable Diffusion 3 Medium模型在英特尔® 酷睿™ Ultra 处理器上一键生成创意海报。请把文中范例代码下载到本地:
git clone https://gitee.com/yiqiitech/stable-diffusion-3-openvino.git
OpenVINO™
Stable Diffusion 3 Medium简介
2024年6月,Stability AI发布了基于MMDiT(Multimodal Diffusion Transformer)架构,迄今为止最先进的文本生成图像模型Stable Diffusion 3 系列模型,并开源了Stable Diffusion 3 Medium的模型权重:https://huggingface.co/stabilityai/stable-diffusion-3-medium,让我们可以下载权重,并将其部署在本地。
Stable Diffusion 3 Medium模型(简称:SD3 Medium)在10亿张图像上进行了预训练,在3000万张高质量审美图像和300万张带偏好的图像上进行了微调,生成的图片具有极佳的整体质量和照片级真实感,能够满足公司大多数无版权图片需求场景,例如:海报/插图。

本文将介绍用OpenVINO™ 转换SD3 Medium模型,并在英特尔® 酷睿™ Ultra处理器上编写一键生成创意海报的程序。
OpenVINO™
英特尔® 酷睿™ Ultra处理器简介
英特尔® 酷睿™ Ultra处理器内置CPU+GPU+NPU 的三大 AI 引擎,赋能AI大模型在不联网的终端设备上进行推理计算。
OpenVINO™
搭建开发环境
在部署SD3 Medium模型前,首先需要搭建开发环境:
conda create -n sd3_ov python=3.11 #创建虚拟环境
conda activate sd3_ov #激活虚拟环境
python -m pip install --upgrade pip #升级pip到最新版本
pip install diffusers sentencepiece openvino nncf torch transformers protobuf opencv-python pillow peft --extra-index-url https://download.pytorch.org/whl/cpuOpenVINO™
下载SD3 Medium权重文件到本地
请从魔搭社区下载SD3 Medium的权重文件:
sd3_medium_incl_clips.safetensors。
下载链接:
https://www.modelscope.cn/models/AI-ModelScope/stable-diffusion-3-medium。
sd3_medium_incl_clips.safetensors权重文件包含了除了T5-XXL文本编码器之外的所有必要权重。在推理计算过程中,去掉47亿参数的T5-XXL文本编码器,可以在仅损失一点点图片生成质量的同时,极大的提升推理速度。
OpenVINO™
导出SD3 Medium的OpenVINO™ IR
格式模型
OpenVINO™ 提供两个函数用于将PyTorch格式模型转换并保存为OpenVINO™ IR格式模型:
1. ov.convert_model():把PyTorch格式模型转换为ov.Model类型的实例;
2. ov.save():把ov.Model类型的实例以文件形式保存到硬盘。
SD3 Medium模型需要转换并保存的模型和组件有:
Transformer架构的MMDiT,简记为“transformer”;
文本编码器CLIP-G/14,简记为“text_encoder”;
文本编码器CLIP-L/14,简记为“text_encoder_2”;
文本编码器T5-XXL,简记为“text_encoder_3”,如前所述,本文选择不导出;
配套CLIP-G/14的分词器,简记为“tokenizer”;
配套CLIP-L/14的分词器,简记为“tokenizer_2”;
配套T5-XXL的分词器,简记为“tokenizer_3”,本文选择不导出;
SD3模型逐步去噪生成图像的调度器,简记为“scheduler”。
使用OpenVINO™ 转换Pytorch格式的SD3 Medium模型的主要步骤有:
1. 加载SD3 Medium模型的预训练权重
2. 将模型中的各个组件转换为OpenVINO™ IR格式模型,并保存这些模型。
完整代码sd3_export_ov.py,如下所示:
import torch
from diffusers import StableDiffusion3Pipeline
import openvino as ov
#################################################################
# 加载SD3 Medium模型的预训练权重 #
#################################################################
# 指定Stable Diffusion 3模型文件路径
sd3_model_file = r"d:\sd3_medium_incl_clips.safetensors"
# 从单个文件加载Stable Diffusion 3 Pipeline,设置数据类型为float32,并不加载第三个文本编码器
pipe = StableDiffusion3Pipeline.from_single_file(
sd3_model_file,
torch_dtype=torch.float32,
text_encoder_3=None
)
#################################################################
# 将模型中的各个组件转换为OpenVINO™ IR格式模型,并保存这些模型 #
#################################################################
# 获取Pipeline中的Transformer模块,并设置为评估模式
transformer = pipe.transformer
transformer.eval()
# 使用torch.no_grad()来禁用梯度计算,加快模型推理速度
with torch.no_grad():
# 将Transformer模块转换为OpenVINO模型
ov_transformer = ov.convert_model(
transformer,
example_input={ # 提供示例输入以帮助OpenVINO优化模型
"hidden_states": torch.zeros((2, 16, 64, 64)),
"timestep": torch.tensor([1, 1]),
"encoder_hidden_states": torch.ones([2, 154, 4096]),
"pooled_projections": torch.ones([2, 2048]),
},
)
# 保存转换后的OpenVINO模型
ov.save_model(ov_transformer, "transformer.xml")
print("Transformer is exported successfully!") # 输出转换成功的消息
# 获取Pipeline中的第一个文本编码器,并设置为评估模式
text_encoder = pipe.text_encoder
text_encoder.eval()
# 使用functools.partial修改forward方法以返回隐藏状态和字典形式的结果
from functools import partial
with torch.no_grad():
text_encoder.forward = partial(text_encoder.forward, output_hidden_states=True, return_dict=False)
# 将第一个文本编码器转换为OpenVINO模型
ov_text_encoder = ov.convert_model(text_encoder, example_input=torch.ones([1, 77], dtype=torch.long))
# 保存转换后的OpenVINO模型
ov.save_model(ov_text_encoder, "text_encoder.xml")
print("text_encoder is exported successfully!") # 输出转换成功的消息
# 获取Pipeline中的第二个文本编码器,并设置为评估模式
text_encoder_2 = pipe.text_encoder_2
text_encoder_2.eval()
with torch.no_grad():
text_encoder_2.forward = partial(text_encoder_2.forward, output_hidden_states=True, return_dict=False)
# 将第二个文本编码器转换为OpenVINO模型
ov_text_encoder_2 = ov.convert_model(text_encoder_2, example_input=torch.ones([1, 77], dtype=torch.long))
# 保存转换后的OpenVINO模型
ov.save_model(ov_text_encoder_2, "text_encoder_2.xml")
print("text_encoder_2 is exported successfully!") # 输出转换成功的消息
# 获取Pipeline中的VAE解码器,并设置为评估模式
vae = pipe.vae
vae.eval()
with torch.no_grad():
# 修改forward方法为decode方法
vae.forward = vae.decode
# 将VAE解码器转换为OpenVINO模型
ov_vae = ov.convert_model(vae, example_input=torch.ones([1, 16, 64, 64]))
# 保存转换后的OpenVINO模型
ov.save_model(ov_vae, "vae_decoder.xml")
print("vae is exported successfully!") # 输出转换成功的消息
# 保存Pipeline中的分词器
pipe.tokenizer.save_pretrained("tokenizer")
# 保存Pipeline中的第二个分词器
pipe.tokenizer_2.save_pretrained("tokenizer_2")
# 保存Pipeline中的调度器
pipe.scheduler.save_pretrained("scheduler")
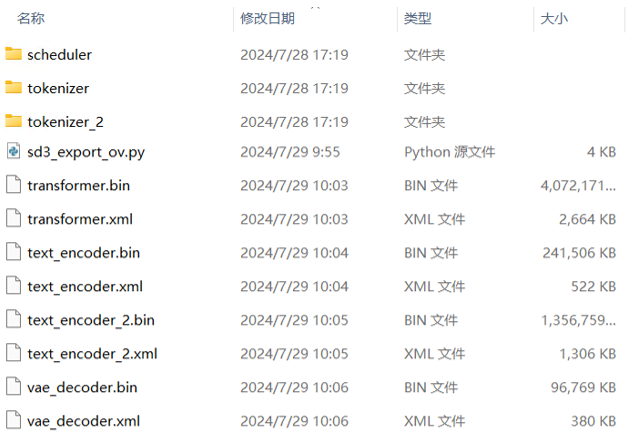
print("tokenizer, tokenizer_2 and scheduler are exported successfully!") # 输出转换成功的消息sd3_export_ov.py执行成功后,得到的OpenVINO™ IR格式模型文件,如下所示:
注意:转换过程中,若遇到网络连接问题,请读者自行解决,例如:
requests.exceptions.ProxyError: (MaxRetryError("HTTPSConnectionPool(host='huggingface.co', port=443): Max retries exceeded with url: /api/models/stabilityai/stable-diffusion-3-medium-diffusers/revision/main (Caused by ProxyError('Unable to connect to proxy', NewConnectionError('<urllib3.connection.HTTPSConnection object at 0x00000286C0BA7A10>: Failed to establish a new connection: [WinError 10061] 由于目标计算机积极拒绝,无法连接。')))"), '(Request ID: 5a9bc8b0-701b-42ba-82ff-e1d381b291bd)')OpenVINO™
编写推理代码,实现一键生成创意海报
导出SD3 Medium IR格式模型后,使用OpenVINO™ 的core.compile_model()方法载入模型,然后使用OVStableDiffusion3Pipeline类创建SD3 Medium模型的工作流水线并执行图片生成的推理计算,最后自动将生成图片合并入海报背景图片,实现一键生成创意海报。
整个过程的典型步骤有:
1. 使用core.compile_model()方法载入模型到指定的计算设备,比如:GPU;
2. 使用OVStableDiffusion3Pipeline类创建SD3 Medium模型的工作流水线;
3. 执行流水线ov_pipe,生成图片;
4. 将生成的图片保存并合并入海报背景图片。
完整代码sd3_ov_poster.py,请下载:
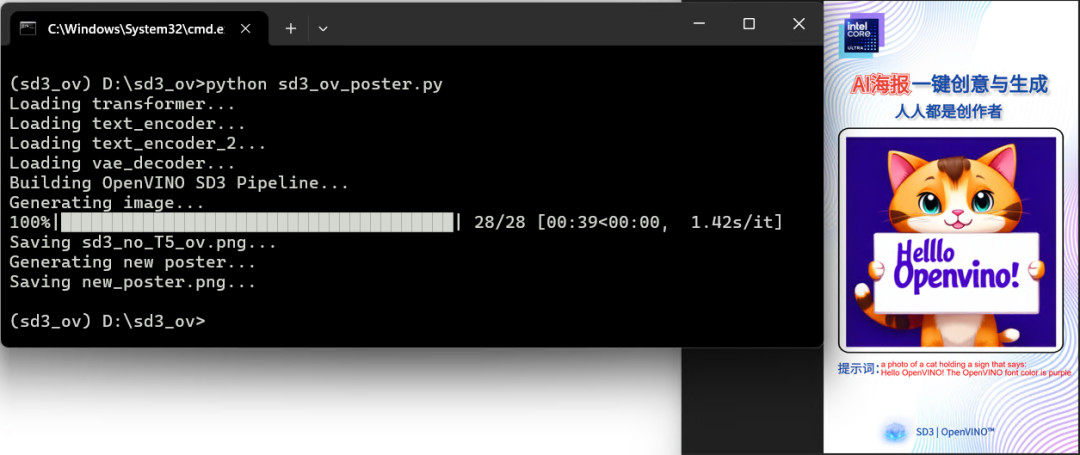
git clone https://gitee.com/yiqiitech/stable-diffusion-3-openvino.git运行结果如下所示:
OpenVINO™
总结
使用OpenVINO™ 可以方便的将SD3 Medium 的Pytorch格式模型转换为IR格式模型,并很容易实现SD3 Medium模型在英特尔® 酷睿™ Ultra 处理器上本地化部署。
OpenVINO™
---------------------------------------
*OpenVINO and the OpenVINO logo are trademarks of Intel Corporation or its subsidiaries.
-----------------------------
OpenVINO 中文社区
微信号 : openvinodev
B站:OpenVINO中文社区
“开放、开源、共创”
致力于通过定期举办线上与线下的沙龙、动手实践及开发者交流大会等活动,促进人工智能开发者之间的交流学习。
○ 点击 “ 在看 ”,让更多人看见
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









