






点击蓝字
关注我们,让开发变得更有趣
作者| 武卓博士 英特尔OpenVINO布道师
排版| 李擎
使用OpenVINO™在你的
AI PC上离线运行Llama3之快手指南
在人工智能领域,大型语言模型(LLMs)的发展速度令人震惊。2024年4月18日,Meta 正式开源了 LLama 系列的新一代大模型 Llama3,在这一领域中树立了新的里程碑。
Llama3 不仅继承了先前模型的强大能力,还通过技术革新,在多模态理解、长文本处理及语言生成等多个方面实现了质的飞跃。Llama3 的开放性和灵活性也为开发者提供了前所未有的便利。无论是进行模型微调,还是集成到现有的系统中,Llama3 都展现了极高的适应性和易用性。
除此之外,提到 Llama3 模型的部署,除了将其部署在云端之外,模型的本地化部署可以让开发者能够在不依赖云计算资源的情况下,实现数据处理和大模型运算的高效率和高隐私性。利用 OpenVINO™ 部署 Llama3 到本地计算资源,例如 AI PC,不仅意味着更快的响应速度和更低的运行成本,还能有效地保护数据安全,防止敏感信息外泄。这对于需要处理高度敏感数据的应用场景尤其重要,如医疗、金融和个人助理等领域。
本文将在简要介绍 Llama3 模型的基础上,重点介绍如何使用 OpenVINO™ 对 Llama3 模型进行优化和推理加速,并将其部署在本地的 AI PC上,进行更快、更智能推理的 AI 推理。

OpenVINO™
Llama3 模型简介
Llama3 提供了多种参数量级的模型,如8B和70B参数模型。其核心特点和优势可总结如下:
· 先进的能力与强大的性能:Llama3 模型提供了在推理、语言生成和代码执行等方面的 SOTA 性能,为大型语言模型(LLMs)设定了新的行业标准。
· 增强的效率:采用仅解码器的 Transformer 架构与群组查询注意力(GQA),优化了语言编码效率和计算资源使用,适用于大规模 AI 任务。
· 全面的训练与调优:在超过15万亿的 tokens 上进行预训练,并通过 SFT 和 PPO 等创新的指令微调技术,Llama3在处理复杂的多语言任务和多样化的AI应用中表现卓越。
· 开源社区焦点:作为 Meta 开源倡议的一部分发布, Llama3 鼓励社区参与和创新,开发者可以轻松访问其生态系统并贡献其发展。
OpenVINO™
利用 OpenVINO™ 优化和加速推理
如前所述,部署 Llama3 模型到本地设备上,不仅意味着更快的响应速度和更低的运行成本,还能有效地保护数据安全,防止敏感信息外泄。因此,本文将重点介绍如何利用 OpenVINO™ 将 Llama3 模型进行优化后部署到本地的 AI PC上。这个过程包括以下具体步骤,使用的是我们常用的OpenVINO™ Notebooks GitHub 仓库中的llm-chatbot 代码示例:https://github.com/openvinotoolkit/openvino_notebooks/tree/latest
详细信息和完整的源代码可以在这里找到:https://github.com/openvinotoolkit/openvino_notebooks/tree/latest/notebooks/llm-chatbot

由安装必要的依赖包开始
运行 OpenVINO™ Notebooks 仓库的具体安装指南在这里:https://github.com/openvinotoolkit/openvino_notebooks?tab=readme-ov-file#-installation-guide
运行这个llm-chatbot 的代码示例,需要安装以下必要的依赖包。

选择推理的模型
由于我们在 Jupyter Notebook 演示中提供了一组由 OpenVINO™ 支持的 多语种的大预言模型,您可以从下拉框中首先选择语言。针对Llama3,我们选择英语。
接下来选择 “llama-3-8b-instruct” 来运行该模型的其余优化和推理加速步骤。当然,很容易切换到其他列出的任意模型。

使用 Optimum-CLI进行模型转换
Optimum Intel 是 Hugging Face Transformers 和 Diffuser 库与 OpenVINO™ 之间的接口,用于加速 Intel 体系结构上的端到端流水线。它提供了易于使用的cli接口,即命令行接口,用于将模型导出为 OpenVINO™ 中间表示(IR)格式。使用下面的一行命令,就可以完成模型的导出
optimum-cli export openvino --model <model_id_or_path> --task <task> <out_dir>其中,--model 参数是来自 HuggingFace Hub 的模型 ID 或带有模型 ID 的已经将模型下载到本地目录的路径地址(使用.save_pretrained方法保存),--task是导出模型应解决的支持任务之一。对于LLM,它将是 text-generation-with-past。如果模型初始化需要使用远程代码,则应额外传递--trust-remote-code远程代码标志。

模型权重压缩
尽管像 Llama-3-8B-Instruct 这样的 LLM 在理解和生成类人文本方面变得越来越强大和复杂,但管理和部署这些模型在计算资源、内存占用、推理速度等方面带来了关键挑战,尤其是对于AI PC这种客户端设备。权重压缩算法旨在压缩模型的权重,并可用于优化大型模型的模型占用空间和性能,其中权重的大小相对大于激活的大小,例如大型语言模型(LLM)。与INT8压缩相比,INT4压缩可以进一步压缩模型大小,并提升文本生成性能,但预测质量略有下降。因此,在这里我们选择模型权重压缩为INT4精度。


使用 Optimum-CLI进行权重压缩
当使用 Optimum-CLI 导出模型时,您还可以选择在线性、卷积和嵌入层上应用 FP16、INT8 位或 INT4 位权重压缩。使用方法非常的简便,就是将--weight格式分别设置为fp16、int8或int4。这种类型的优化允许减少内存占用和推理延迟。默认情况下,int8/int4的量化方案将是不对称的量化压缩。如果您需要使用对称压缩,可以添加--sym。
对 Llama-3-8B-Instruct 模型进行 INT4 量化,我们指定以下参数:
compression_configs = {
"llama-3-8b-instruct": {
"sym": True,
"group_size": 128,
"ratio": 0.8,
},
}--group size参数将定义用于量化的组大小,为128。
--ratio参数控制4位和8位量化之间的比率。这意味着80%的层将被量化为int4,而20%的层将量化为int8。
运行Optimum-CLI进行模型的下载及权重压缩的命令如下:
optimum-cli export openvino --model "llama-3-8b-instruct" --task text-generation-with-past --weight-format int4 --group-size 128 --ratio 0.8 –sym运行上述命令后,模型将从 Hugging Face Hub 自动下载 Llama-3-8B-Instruct 模型,并进行相应的模型压缩操作。
对于模型下载有困难的开发者,也可以从 ModelScope 开源社区的以下链接:
Meta-Llama-3-8B-Instruct:
https://modelscope.cn/models/LLM-Research/Meta-Llama-3-8B-Instruct
Meta-Llama-3-70B-Instruct:
https://modelscope.cn/models/LLM-Research/Meta-Llama-3-70B-Instruct
通过Git的方式进行下载:
git clone https://www.modelscope.cn/LLM-Research/Meta-Llama-3-8B-Instruct.git
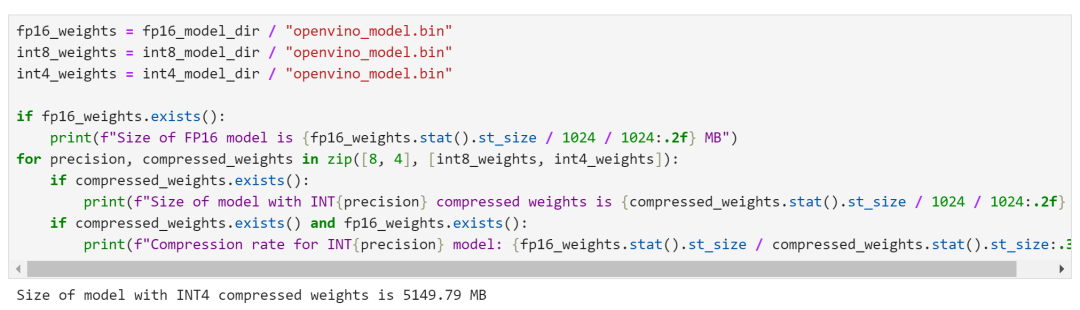
经过权重压缩后,我们可以看到,8B模型的体积大小已经被压缩为仅有5GB左右。

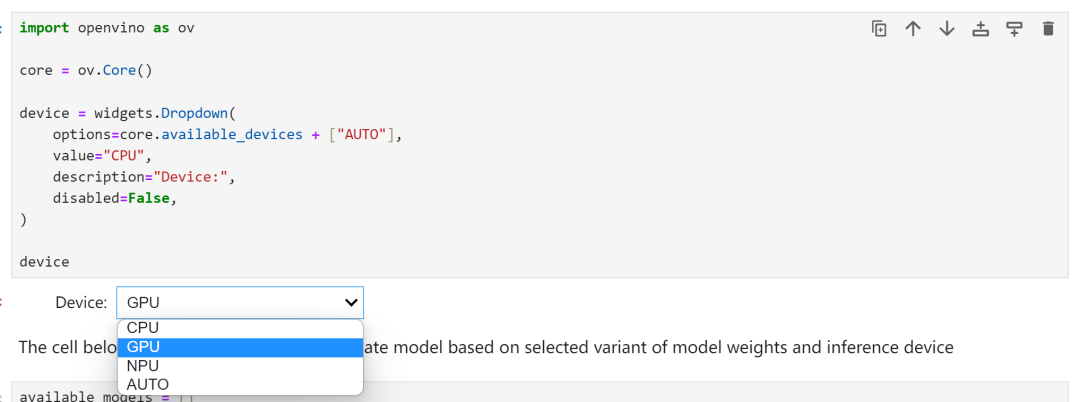
选择推理设备和模型变体
由于 OpenVINO™ 能够在一系列硬件设备上轻松部署,因此还提供了一个下拉框供您选择将在其上运行推理的设备。考虑到要对模型尺寸和性能需求,在这里我们选择搭载了英特尔®酷睿™ Ultra7 155H 处理器的 AI PC 上的 GPU 作为推理设备。

使用 Optimum Intel 实例化模型
Optimum Intel 可用于从将下载到本地并完成了权重压缩后的模型进行加载,并创建推理流水线,通过Hugging FaceAPI 使用 OpenVINO Runtime 运行推理。在这种情况下,这意味着我们只需要将 AutoModelForXxx 类替换为相应的 OVModelForXxx 类。


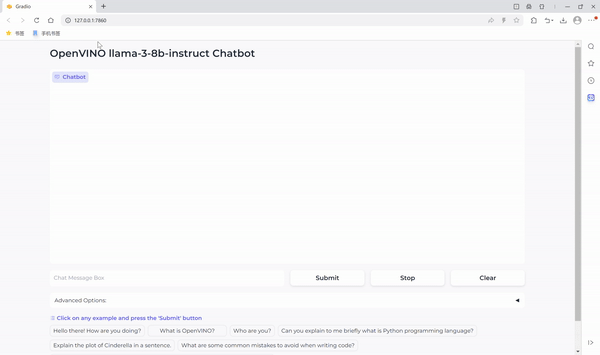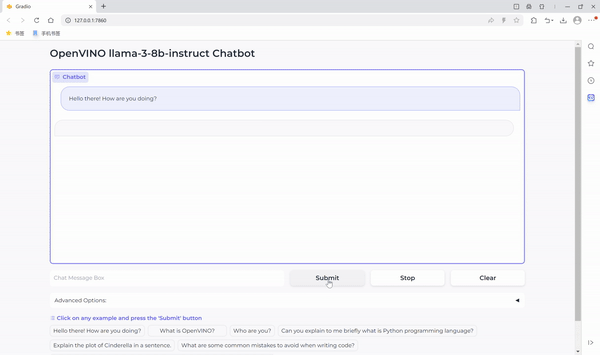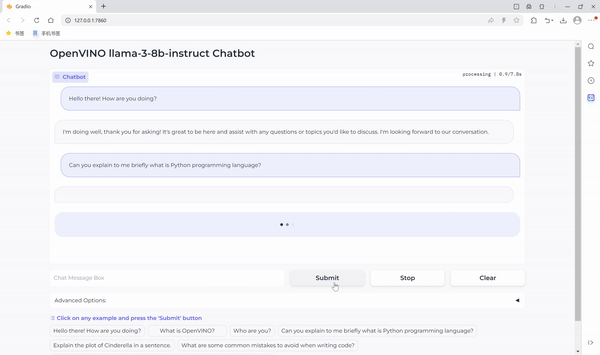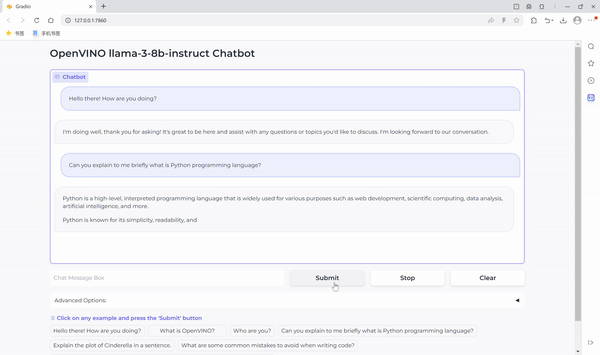
运行聊天机器人
现在万事具备,在这个 Notebook 代码示例中我们还提供了一个基于 Gradio 的用户友好的界面。现在就让我们把聊天机器人运行起来吧。
OpenVINO™
小结:
整个的步骤就是这样!现在就开始跟着我们提供的代码和步骤,动手试试用 OpenVINO™ 在AI PC上运行基于Llama3大语言模型的聊天机器人吧。
关于英特尔 OpenVINO™ 工具套件的详细资料,包括其中我们提供的三百多个经验证并优化的预训练模型的详细资料,请您点击https://www.intel.com/content/www/us/en/developer/tools/openvino-toolkit/overview.html
除此之外,为了方便大家了解并快速掌握 OpenVINO™ 的使用,我们还提供了一系列开源的 Jupyter notebook demo。
运行这些 notebook,就能快速了解在不同场景下如何利用 OpenVINO™ 实现一系列、包括计算机视觉、语音及自然语言处理任务。
OpenVINO™ notebooks 的资源可以在 GitHub 下载安装:https://github.com/openvinotoolkit/openvino_notebooks 。
OpenVINO™
--END--
点击下方图片,让我们一起成为“Issues 猎手”,共创百万用户开源生态!你也许想了解(点击蓝字查看)⬇️➡️ 隆重介绍 OpenVINO™ 2024.0: 为开发者提供更强性能和扩展支持➡️ 隆重推出 OpenVINO 2023.3 ™ 最新长期支持版本➡️ OpenVINO™ 2023.2 发布:让生成式 AI 在实际场景中更易用➡️ 开发者实战 | 介绍OpenVINO™ 2023.1:在边缘端赋能生成式AI➡️ 基于 ChatGLM2 和 OpenVINO™ 打造中文聊天助手➡️ 基于 Llama2 和 OpenVINO™ 打造聊天机器人➡️ OpenVINO™ DevCon 2023重磅回归!英特尔以创新产品激发开发者无限潜能➡️ 5周年更新 | OpenVINO™ 2023.0,让AI部署和加速更容易➡️ OpenVINO™5周年重头戏!2023.0版本持续升级AI部署和加速性能➡️ 开发者实战系列资源包来啦!➡️ 以AI作画,祝她节日快乐;简单三步,OpenVINO™ 助你轻松体验AIGC扫描下方二维码立即体验
OpenVINO™ 工具套件 2024.0点击 阅读原文 立即体验OpenVINO™ 2024.0,评论区已开放,欢迎大家留言评论!
文章这么精彩,你有没有“在看”?















 1642
1642

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









