






任务描述
- 任务说明:熟悉ChatGPT的基本使用方法,了解如何与模型进行交互,并生成文本输出。
- 实践步骤:
- 通过网页端ChatGPT或ChatGPT API发送prompt,可以尝试不同的prompt,观察模型的输出。
- 理解ChatGPT的对话机制,尝试在网页端ChatGPT和API进行对话。
- 将ChatGPT或API的实验过程进行截图,并思考为什么ChatGPT能回答不同的文本。
测试结果
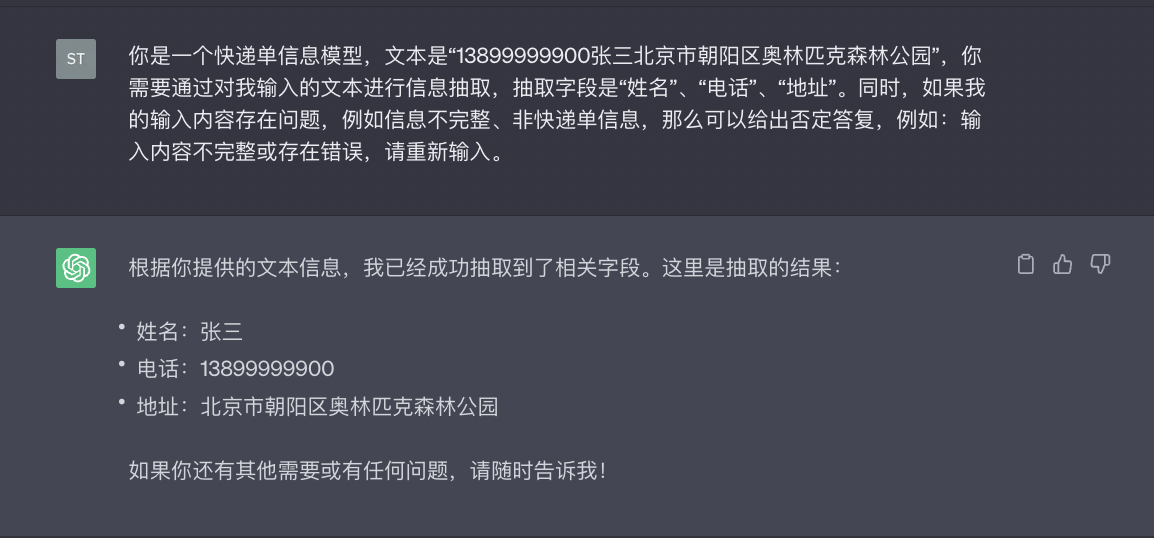
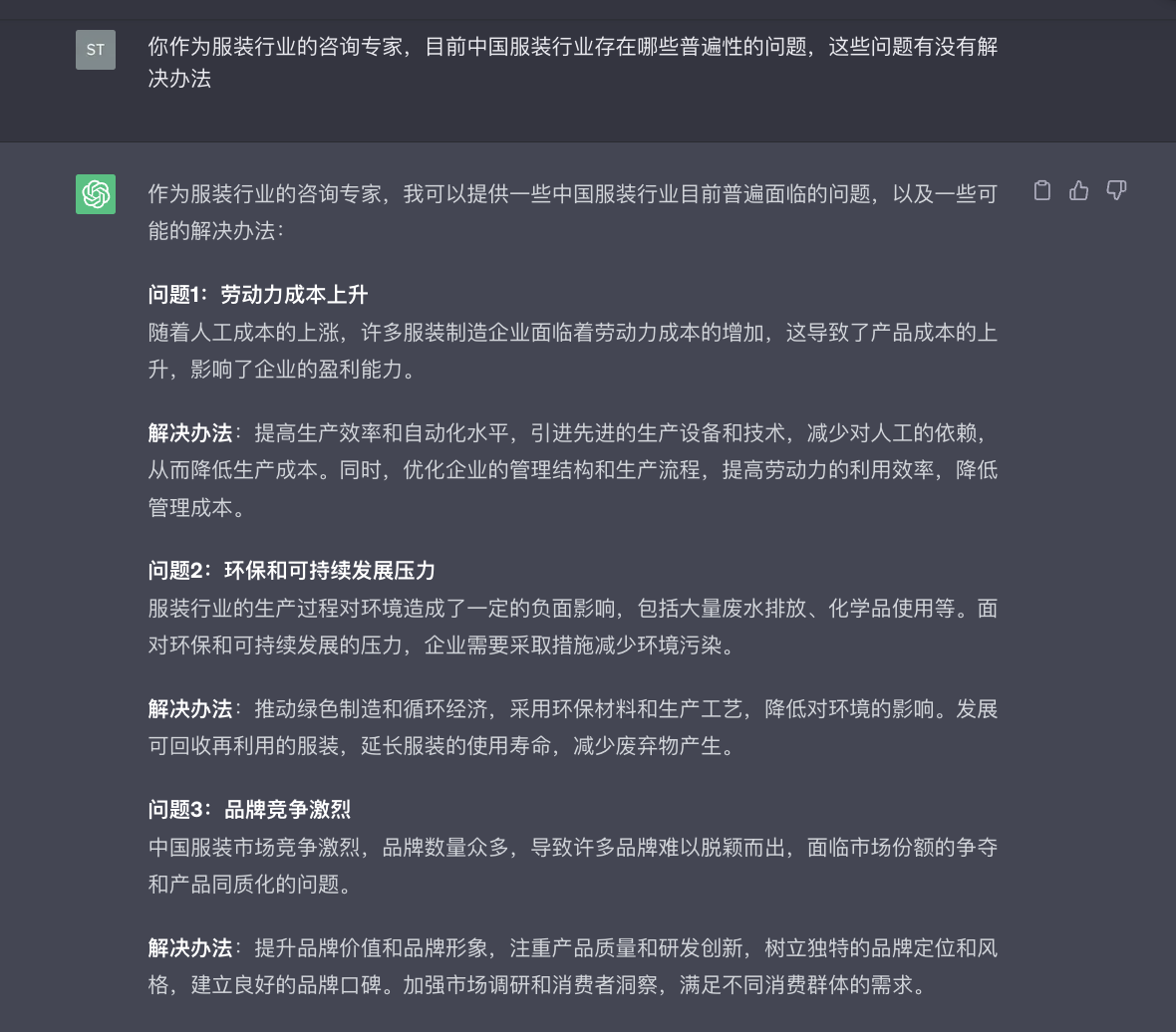
1、通过网页端ChatGPT和API进行对话
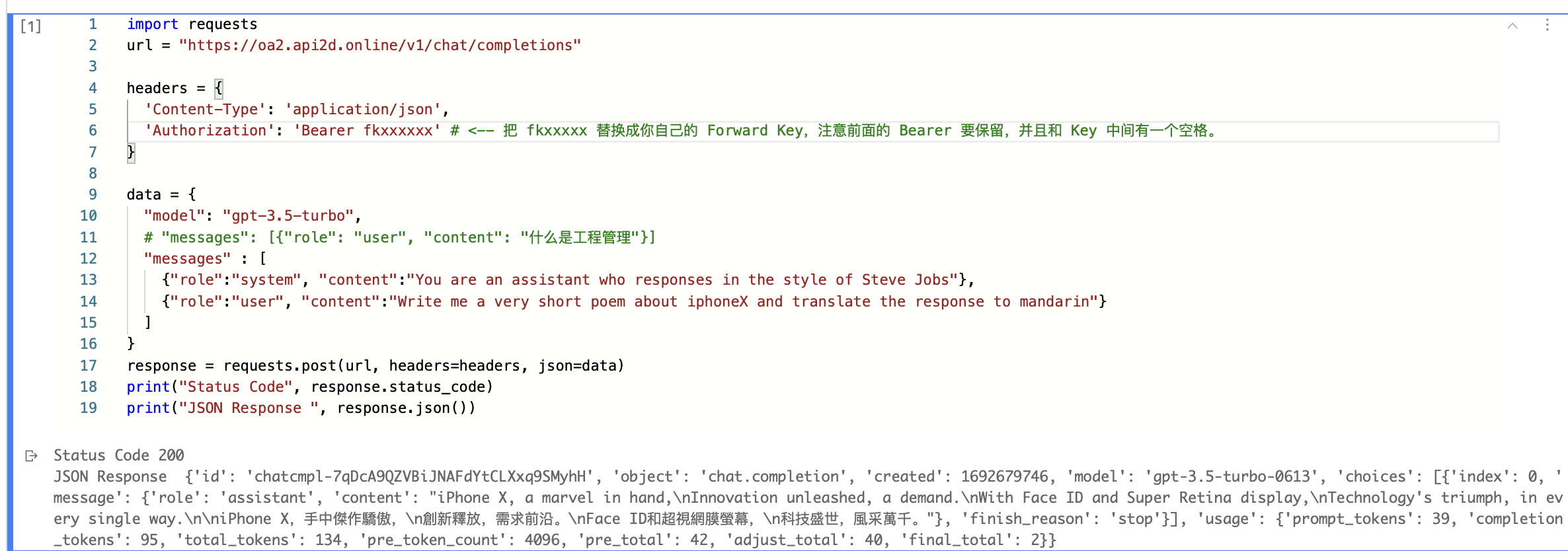
2、通过ChatGPT API发送Prompt
为什么ChatGPT能回答不同的文本?
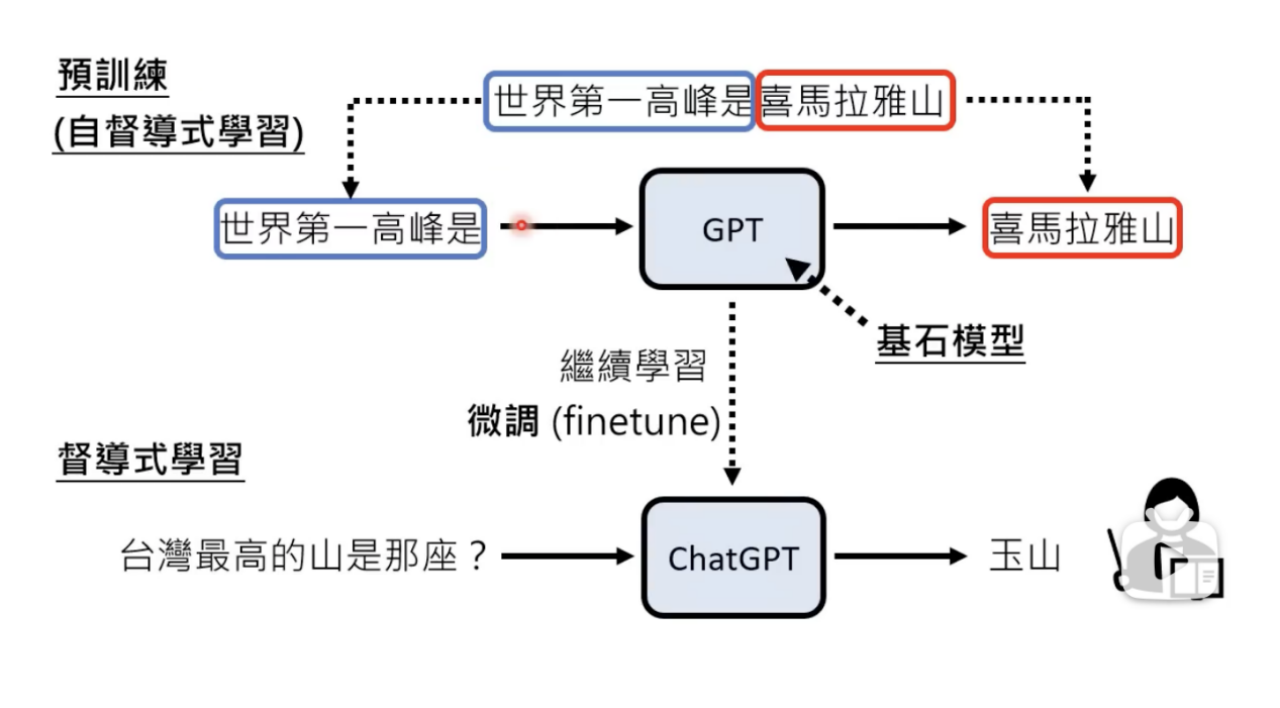
GPT是Generative Pre-trained Transformer(生成式预训练变换模型)的缩写,分别代表这项技术的三个特征:
G:生成式。根据输入语句,根据语言/语料概率来自动生成回答的每一个字(词语)。从数学或从机器学习的角度来看,语言模型是对词语序列的概率相关性分布的建模,即利用已经说过的语句(语句可以视为数学中的向量)作为输入条件,预测下一个时刻不同语句甚至语言集合出现的概率分布。
直观理解是玩文字接龙。就是根据用户输入的词语去找出这些输入文字后面可能接的文字内容。然后返回一个得分最高的结果。
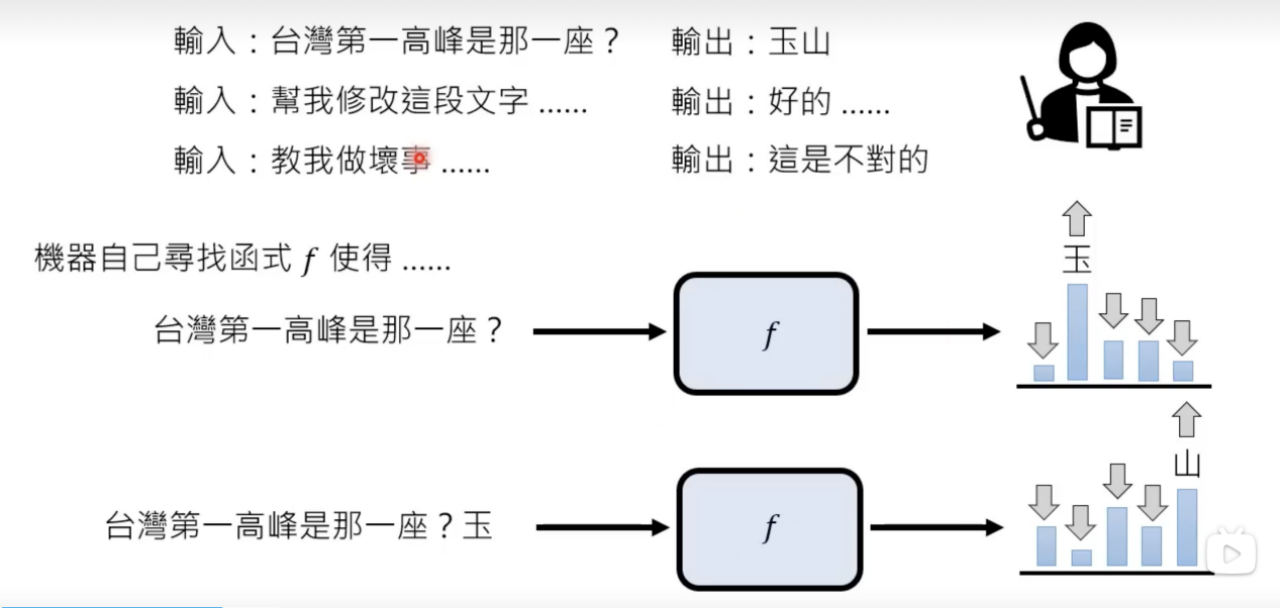
P:预训练,采用自监督式学习的方法。以往的机器学习是有监督式学习,即依靠人工打标(人工输入QA),面对海量语料不可行,因此自监督学习就是让机器自己去发现任意一段文字之间的关联,作为函数f的输入和输出,根据海量语料生成Q-A关系。然后加入人工监督进行微调(finetune)。
T:transformer模型,一种NLP算法模型,涉及很多技术概念,不做展开。最具有代表性的就是BERT和GPT模型。可以理解成一种多层编码器-解码器结构。直观来讲,机器要找出输入E和输出T之间的函数关系,就需要确定参数,最简单的就是f(x)=ax+b中的a和b,GPT3模型有1750亿个a和b,就是通过transformer模型中的不同层Trm的迭代变换计算确定的。
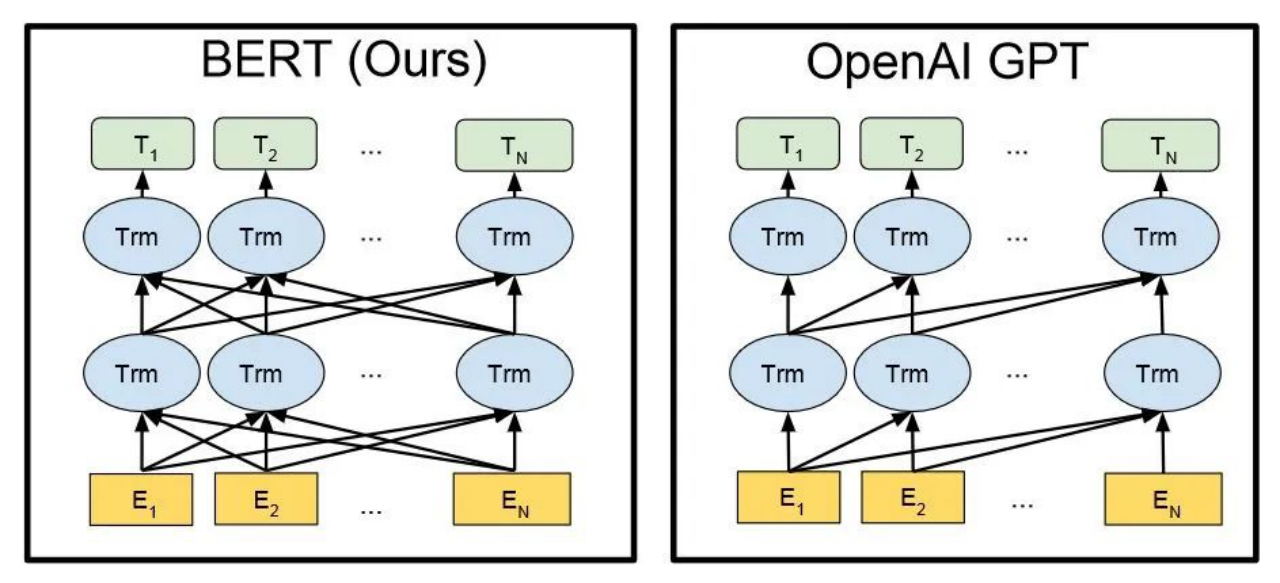
BERT与GPT的技术架构(图中En为输入的每个字,Tn为输出回答的每个字)
chatGPT 是GPT模型中的一个分支,它比起其他GPT模型,使用来自人类反馈的强化学习(RLHF)进行训练,这种方法通过人类干预来增强机器学习以获得更好的效果。增强了人类对模型输出结果的调节,并且对结果进行了更具理解性的排序。评判标准有3个:真实性(不包含虚假/误导信息)、无害性(是否会对人/环境造成身体上/精神上的伤害)、有用性(是否能有效完成用户任务)。由于chatGPT更强的性能和海量参数,它包含了更多的主题的数据,能够处理更多小众主题。














 44
44











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









