






任务描述
- 任务说明:在ChatGPT中编写和使用正则表达式,以实现文本匹配和模式提取的功能。
- 待匹配文本:
Enron Dataset: Over half a million anonymized emails from over 100 users. It’s one of the few publically available collections of “real” emails available for study and training sets.
Google Blogger Corpus: Nearly 700,000 blog posts from blogger.com. The meat of the blogs contain commonly occurring English words, at least 200 of them in each entry.
SMS Spam Collection: Excellent dataset focused on spam. Nearly 6000 messages tagged as legitimate or spam messages with a useful subset extracted directly from Grumbletext.
Recommender Systems Datasets: Datasets from a variety of sources, including fitness tracking, video games, song data, and social media. Labels include star ratings, time stamps, social networks, and images.
Project Gutenberg: Extensive collection of book texts. These are public domain and available in a variety of languages, spanning a long period of time.- 实践步骤:
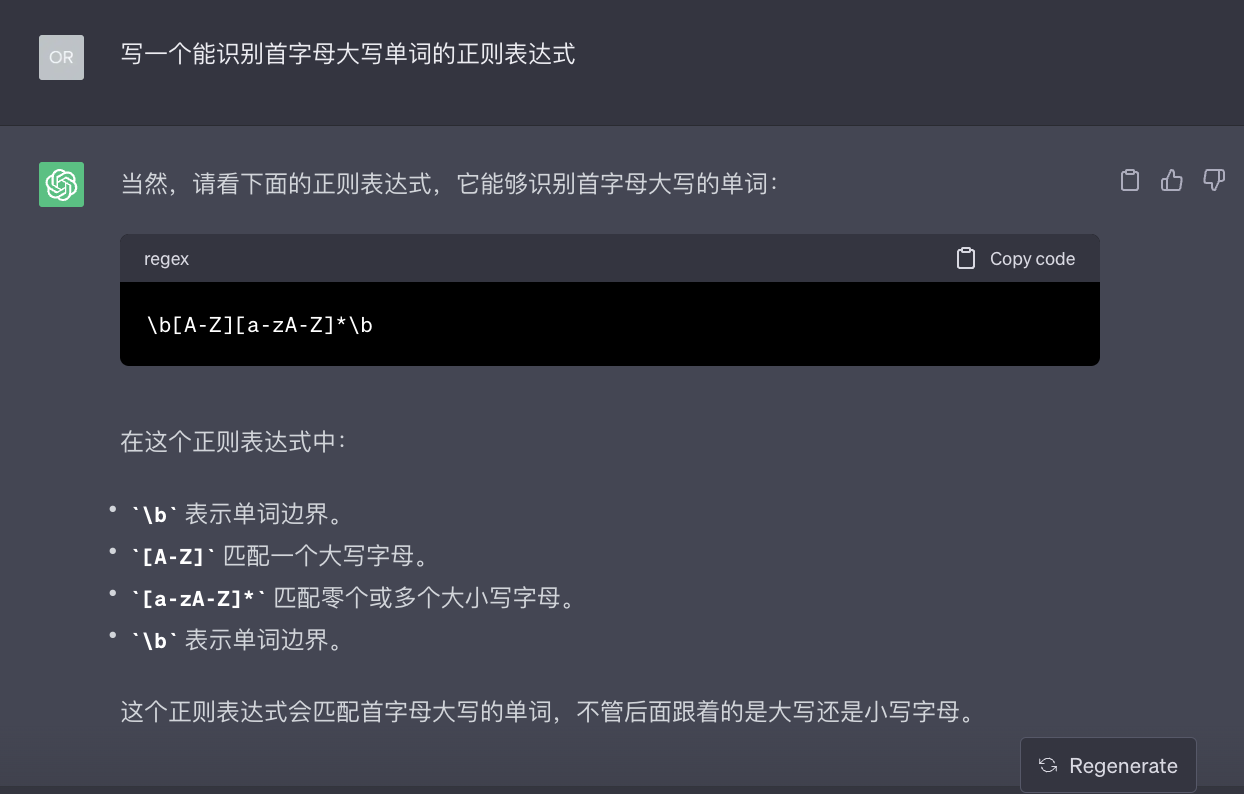
- 编写prompt让ChatGPT写一个能识别首字母大写单词的正则。
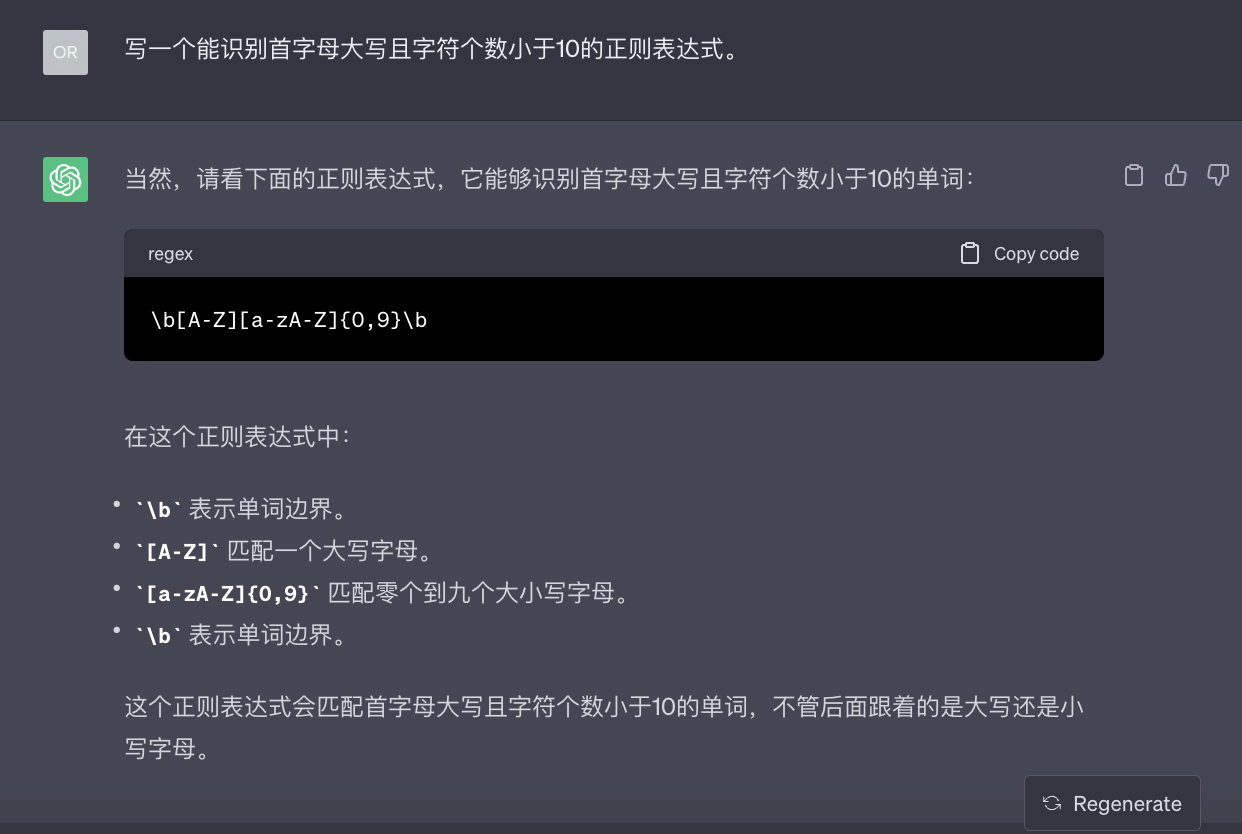
- 编写prompt让ChatGPT写一个能识别首字母大写且字符个数小于10的正则。
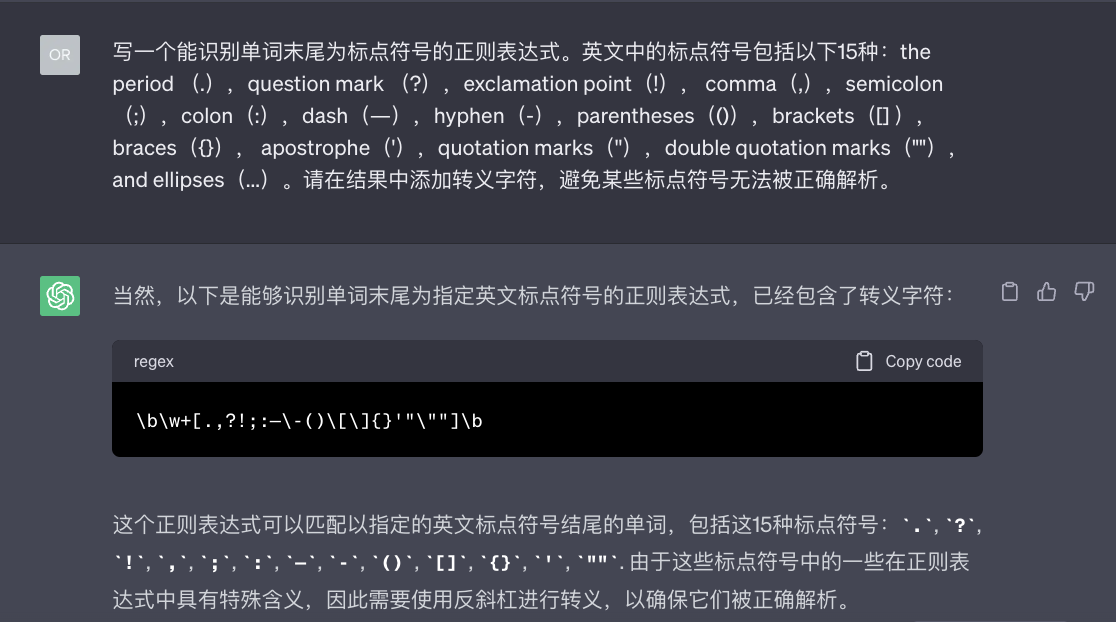
- 编写prompt让ChatGPT写一个能识别单词末尾为标点符号的正则。
- 上述实验过程进行截图,通过Python代码验证ChatGPT输出正则的有效性。
ChatGPT Prompt
1、让ChatGPT写一个能识别首字母大写单词的正则
2、让ChatGPT写一个能识别首字母大写且字符个数小于10的正则。
3、编写prompt让ChatGPT写一个能识别单词末尾为标点符号的正则。
Prompt:写一个能识别单词末尾为标点符号的正则表达式。英文中的标点符号包括以下15种:the period (.),question mark (?),exclamation point(!), comma(,),semicolon(;),colon(:),dash(—),hyphen(-),parentheses(()),brackets([] ),braces({}), apostrophe('),quotation marks(''),double quotation marks(""),and ellipses(...)。请在结果中添加转义字符,避免某些标点符号无法被正确解析。
Python代码验证
源代码:
import re
# 读取文件内容
def read_file(file_path):
with open(file_path, 'r') as file:
content = file.read()
return content
# 识别首字母大写单词的正则,并输出这些单词
def find_capitalized_words(text):
pattern = r'\b[A-Z][a-zA-Z]*\b'
capitalized_words = re.findall(pattern, text)
return capitalized_words
# 识别首字母大写且字符个数小于10的正则,并输出这些单词
def find_short_capitalized_words(text):
pattern = r'\b[A-Z][a-zA-Z]{0,9}\b'
short_capitalized_words = re.findall(pattern, text)
return short_capitalized_words
# 识别单词末尾为标点符号的正则,并输出这些单词
def find_words_with_punctuation(text):
pattern = r'\b\w+[.,?!;:—\(\)\[\]{}\'\"“”‘’"](?=[a-zA-Z]|\s|$)'
words_with_punctuation = re.findall(pattern, text)
words_without_punctuation = [word[:-1] for word in words_with_punctuation]
return words_without_punctuation
# 主函数
def main():
# file_path = 'your_file.txt' # 替换为你的文件路径
file_path = '/home/aistudio/data/input.txt'
content = read_file(file_path)
capitalized_words = find_capitalized_words(content)
print("Capitalized words:", capitalized_words)
short_capitalized_words = find_short_capitalized_words(content)
print("Short capitalized words:", short_capitalized_words)
words_with_punctuation = find_words_with_punctuation(content)
print("Words with punctuation:", words_with_punctuation)
if __name__ == "__main__":
main()
验证截图:
任务3 chatGPT输出的prompt识别有误,经过人工优化后得到新的正则表达式
\b\w+[.,?!;:—\(\)\[\]{}\'\"“”‘’"](?=[a-zA-Z]|\s|$)
(?=[a-zA-Z]|\s|$): 这是一个非捕获组,匹配字母字符(大小写)或空白字符(\s)或字符串结尾($)的条件。
在百度飞桨平台上运行后输出:
















 46
46











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









