







书生·浦语是上海人工智能实验室和商汤科技联合研发的一款大模型,很高兴能参与本次第二期训练营,我也将会通过笔记博客的方式记录学习的过程与遇到的问题,并为代码添加注释,希望可以帮助到你们。
记得点赞哟(๑ゝω╹๑)
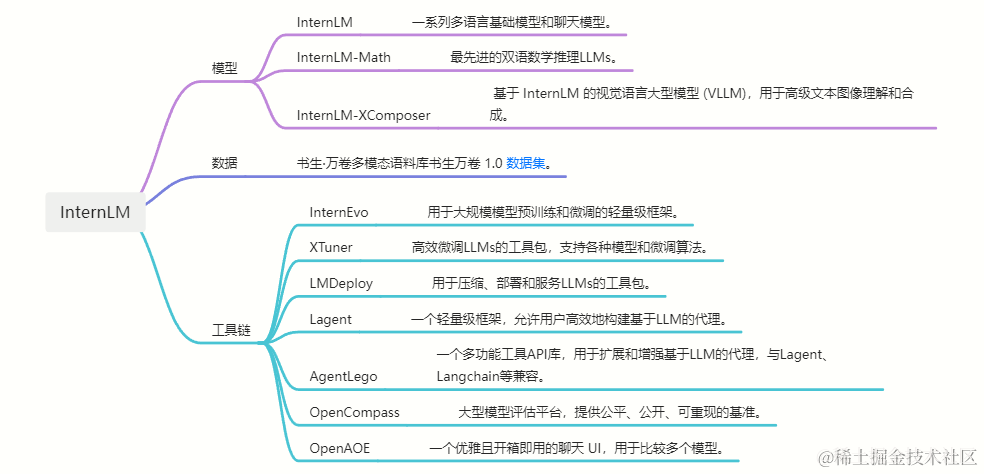
书生浦语大模型开源体系详细介绍
视频链接:
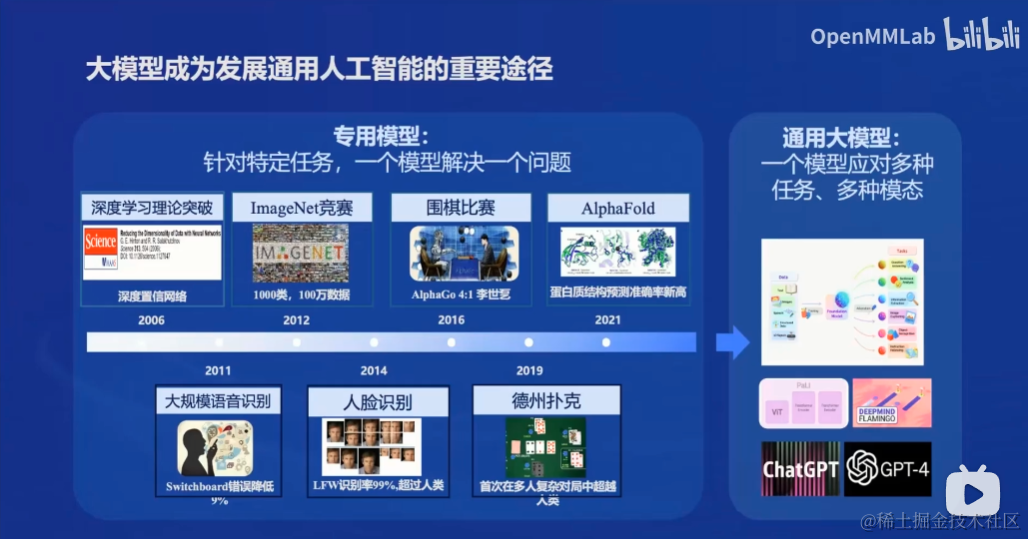
大模型成为发展人工智能的重要途径
专用模型:针对特定任务,一个模型解决一个问题
深度学习->大规模语音识别->人脸识别->ImageNet竞赛->围棋比赛->德州扑克->AlphaFold
通用大模型:一个模型应对多种任务、多种模态
书生浦语大模型开源历程
-
2023.6.7:InternLM千亿参数语言大模型发布
-
2023.7.6:InternLM千亿参数大模型全面升级,支持8K语境、26种语言。 全面开源,免费商用:InternLM-7B模型、全链条开源工具体系
-
2023.8.14:书生万卷1.0多模态预训练语料库开源发布
-
2023.8.21:升级版对话,模型InternLM-Chat-7B v1.1发布,开源智能体框架Lagent,支持从语言模型到智能体升级转换
-
2023.8.28:InternLM千亿参数模型参数量升级到123B
-
2023.9.20:增强型InternLM-20B开源,开源工具链全线升级
-
2024.1.17:InternLM2开源

书生浦语2.0(InternLM2)的体系
面向不同的使用需求,每个规格包含三个模型版本
按规格分类
7B:为轻量级的研究和应用提供了一个轻便但性能不俗的模型
20B:模型的综合性能更为强劲,可有效支持更加复杂的使用场景
按使用需求分类
InternLM2-Base:高质量和具有很强可塑性的模型基座,是模型进行深度领域适配的高质量起点
InternLM2:在Base基础上,在多个能力方向进行了强化,在评测中成绩优异,同时保持了很好的通用语言能力,是我们推荐的在大部分应用中考虑选用的优秀基座
InternLM2-Chat:在Base基础上,经过SFT和RLHF,面向对话交互进行了优化,具有很好的指令遵循,共情聊天和调用工具等能力

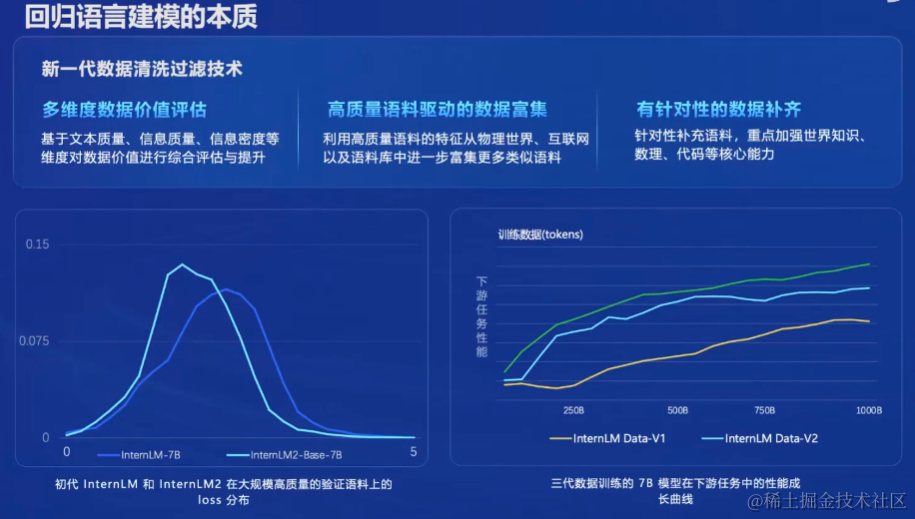
回归语言建模的本质
新一代清洗过滤技术
1.多维度数据价值评估:基于文本质量、信息质量、信息密度等维度对数据价值进行综合评估与提升
2.高质量语料驱动的数据富集:利用高质量语料的特征从物理世界、互联网以及语料库中进一步富集更多类似语料
3.有针对性的数据补齐:针对性补充语料,重点加强世界知识、数理、代码等核心能力
书生浦语2.0(InternLM2)主要亮点
-
超长上下文:模型在20万token上下文中,几乎完美实现”大海捞针“
-
综合性能全面提升:推理、数学、代码提升显著InternLM2-Chat-20B在重点评测上比肩ChatGPT
-
优秀的对话和创作体验:精准指令跟随,丰富的结构化创作,在AlpacaEval2超越GPT3.5和Gemini Pro
-
工具调用能力整体升级:可靠支持工具多轮调用,复杂智能体搭建
-
突出的数理能力和使用的数据分析功能:强大的内生计算能力,加入代码解释后,在GSM8K和MATH达到和GPT-4相仿水平

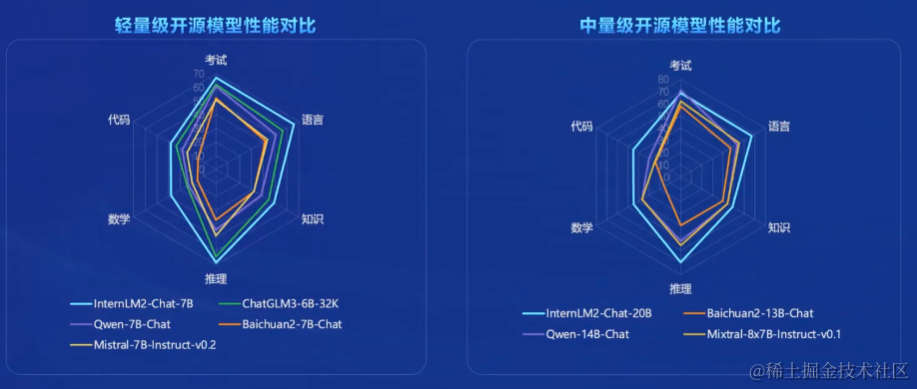
性能全方位提升
在各能力维度全面进步,在推理、数学、代码等方面的能力提升尤为显著,综合性能达到同量级开源模型的领先水平,在重点能力评测上InternLM2-Chat-20B甚至可以达到比肩ChatGPT(GPT3.5)的水平
贴心可靠、充满人文关怀、具备丰富想象力
工具调用能力升级
工具调用能够极大地拓展大预言模型的能力边界,使得大语言模型能够通过搜索、计算、代码解释器等获取最新的知识冰处理更加复杂的问题,InternLM2进
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 680
680

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









