







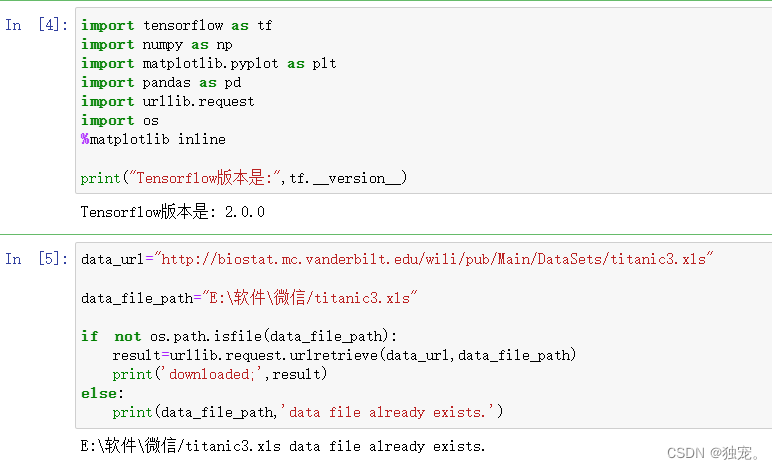
导入库
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import urllib.request
import os
%matplotlib inline
print("Tensorflow版本是:",tf.__version__)
data_url="http://biostat.mc.vanderbilt.edu/wili/pub/Main/DataSets/titanic3.xls"
data_file_path="E:\软件\微信/titanic3.xls"
if not os.path.isfile(data_file_path):
result=urllib.request.urlretrieve(data_url,data_file_path)
print('downloaded;',result)
else:
print(data_file_path,'data file already exists.')
data_file_path="E:\软件\微信/titanic3.xls这个是你自己要下载存放的路径
import numpy
import pandas as pd
from sklearn import preprocessing
# 读取数据文件,结果为DataFrame格式
df_data = pd.read_excel(data_file_path)
筛选提取字段
selected_cols=['survived','name','pclass','sex','age','sibsp','parch','fare','embarked']
selected_df_data=df_data[selected_cols]
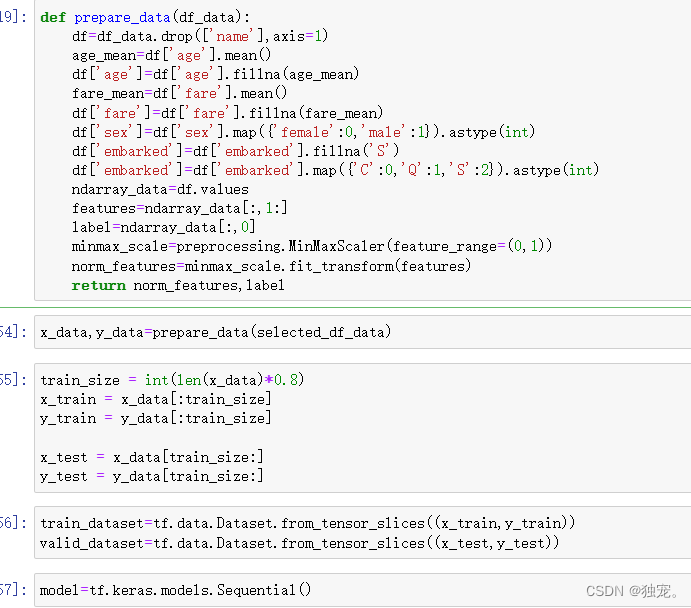
def prepare_data(df_data):
df=df_data.drop(['name'],axis=1)
age_mean=df['age'].mean()
df['age']=df['age'].fillna(age_mean)
fare_mean=df['fare'].mean()
df['fare']=df['fare'].fillna(fare_mean)
df['sex']=df['sex'].map({'female':0,'male':1}).astype(int)
df['embarked']=df['embarked'].fillna('S')
df['embarked']=df['embarked'].map({'C':0,'Q':1,'S':2}).astype(int)
ndarray_data=df.values
features=ndarray_data[:,1:]
label=ndarray_data[:,0]
minmax_scale=preprocessing.MinMaxScaler(feature_range=(0,1))
norm_features=minmax_scale.fit_transform(features)
return norm_features,label
```train_dataset=tf.data.Dataset.from_tensor_slices((x_train,y_train))
valid_dataset=tf.data.Dataset.from_tensor_slices((x_test,y_test))
```bash
x_data,y_data=prepare_data(selected_df_data)
train_size = int(len(x_data)*0.8)
x_train = x_data[:train_size]
y_train = y_data[:train_size]
x_test = x_data[train_size:]
y_test = y_data[train_size:]
train_dataset=tf.data.Dataset.from_tensor_slices((x_train,y_train))
valid_dataset=tf.data.Dataset.from_tensor_slices((x_test,y_test))
model=tf.keras.models.Sequential()
模型设置
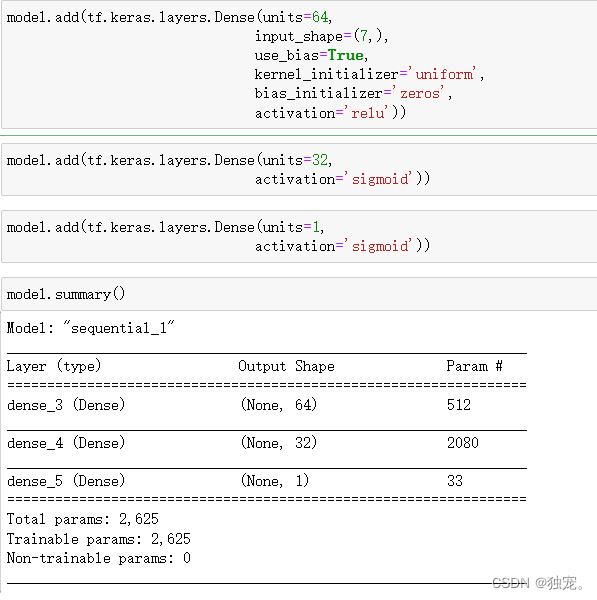
model.add(tf.keras.layers.Dense(units=64,
input_shape=(7,),
use_bias=True,
kernel_initializer='uniform',
bias_initializer='zeros',
activation='relu'))
model.add(tf.keras.layers.Dense(units=32,
activation='sigmoid'))
model.add(tf.keras.layers.Dense(units=1,
activation='sigmoid'))
模型参数信息
model.summary()
训练模型
model.compile(optimizer=tf.keras.optimizers.Adam(0.003),
loss='binary_crossentropy',
metrics=['accuracy'])
- optimizer可以是优化器的名字,如’adam’,也可以是优化器的实例
- loss是损失函数名⁻用sigmoid作为激活函数,一般损失函数选用binary_crossentropy
- binary_crossentropy⁻用softmax作为激活函数,一般损失函数选用categorical_crossentropy
- categorical_crossentropy•metrics模型要训练和评估的度量值
train_dataset=train_dataset.shuffle(buffer_size=10000)
train_dataset=train_dataset.batch(40)
train_history=model.fit(train_dataset,
epochs=100,
validation_data=train_dataset,
verbose=2)
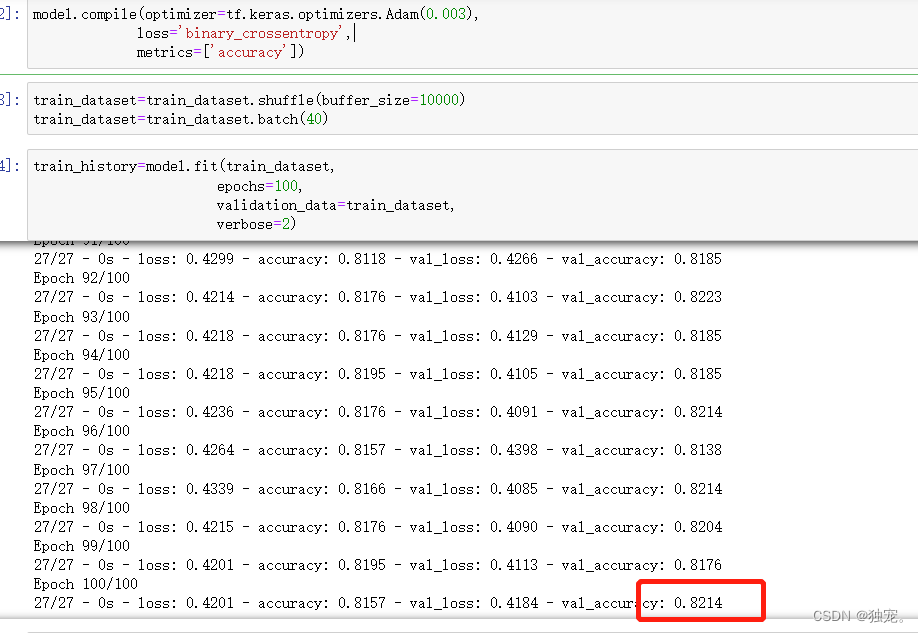
准确率为80%
train_history.history
train_history.history.keys()
可视化
import matplotlib.pyplot as plt
%matplotlib inline
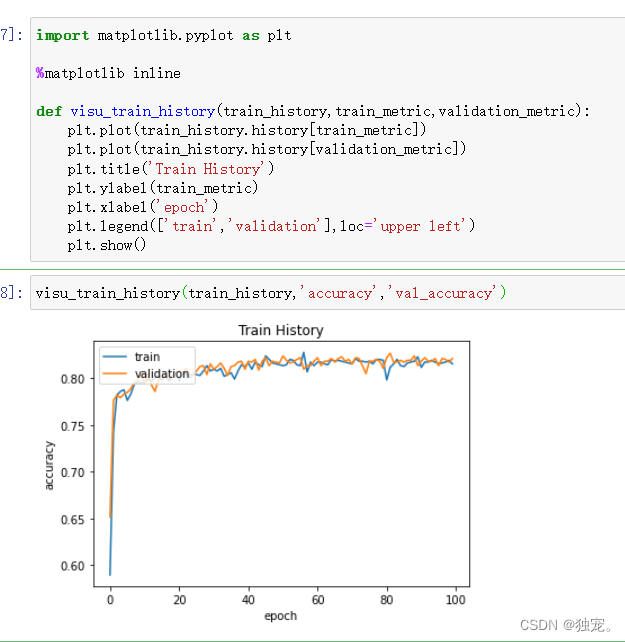
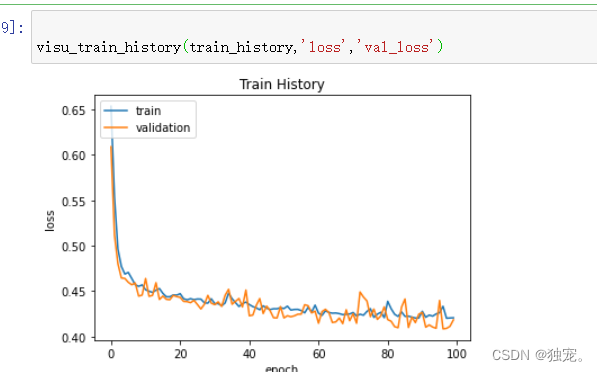
def visu_train_history(train_history,train_metric,validation_metric):
plt.plot(train_history.history[train_metric])
plt.plot(train_history.history[validation_metric])
plt.title('Train History')
plt.ylabel(train_metric)
plt.xlabel('epoch')
plt.legend(['train','validation'],loc='upper left')
plt.show()
isu_train_history(train_history,'accuracy','val_accuracy')
visu_train_history(train_history,'loss','val_loss')
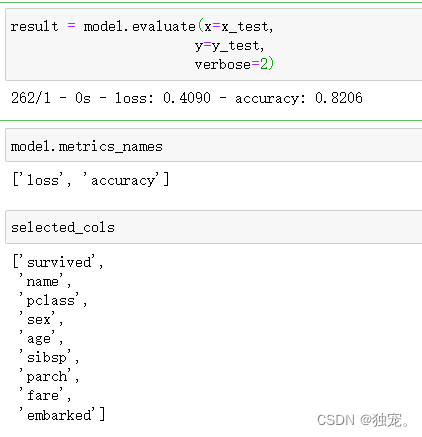
模型评估
result = model.evaluate(x=x_test,
y=y_test,
verbose=2)
model.metrics_names
selected_cols
插入数据
Jack_info=[0,'Jack',3,'male',23,1,0,5.0000,'S']
Rose_info=[1,'Rose',1,'female',20,1,0,100.0000,'S']
new_passenger_pd=pd.DataFrame([Jack_info,Rose_info],columns=selected_cols)
all_passenger_pd=selected_df_data.append(new_passenger_pd)
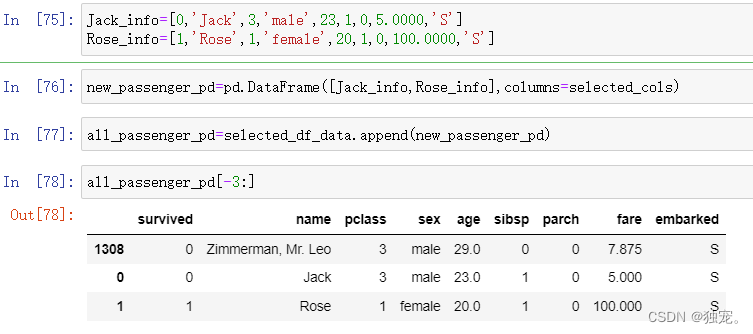
显示后三条数据
all_passenger_pd[-3:]
x_features,y_label=prepare_data(all_passenger_pd)
surv_probability=model.predict(x_features)
surv_probability[:5]
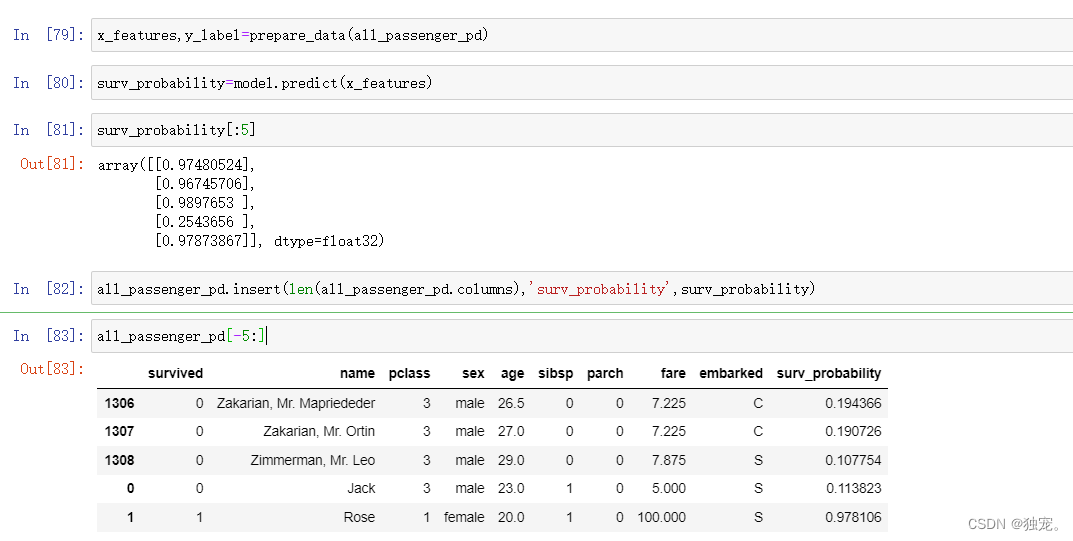
all_passenger_pd.insert(len(all_passenger_pd.columns),'surv_probability',surv_probability)
all_passenger_pd[-5:]
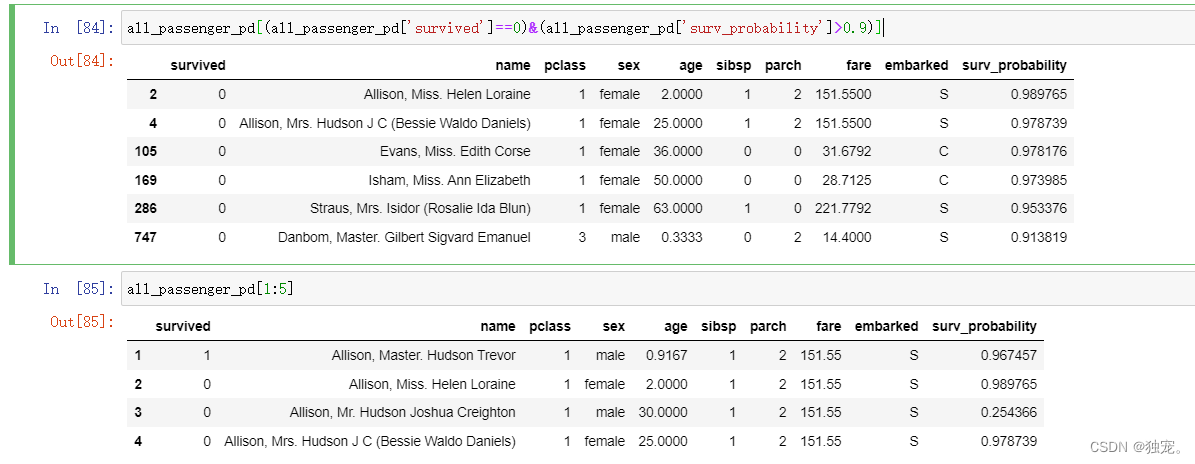
打印存活率大于90%的
all_passenger_pd[(all_passenger_pd['survived']==0)&(all_passenger_pd['surv_probability']>0.9)]
all_passenger_pd[1:5]















 799
799











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









