







认识决策树
一、决策树
决策树思想的来源非常朴素,程序设计中的条件分支结构就是if-then结构,最早的决策树就是利用这类结构分割数据的一种分类学习方法。
二、实例:猜谁是世界杯冠军

每猜一次给一块钱,告诉我是否猜对了,那么我需要掏多少钱才能知道谁是世界冠军?我可以把球编上号,从1到32,然后提问:冠军在1-16号吗?依次询问,只需要五次就可以知道结果。
信息熵
“谁是世界杯冠军”的信息量应该比5比特少。香农指出,它的准确信息量应该是:
![]()
● H的专业术语称之为信息熵,单位为比特。
● 公式:
![]()
当这32支球队夺冠的几率相同时,对应的信息熵等于5比特。
信息和消除不确定性是相联系。
三、实例:银行贷款

针对这个问题,决策树的实际划分:

划分的依据是,越靠前的条件能更大得减少信息的不确定性。
决策树的划分依据之一-信息增益
特征A对训练数据集D的信息增益g(D,A),定义为集合D的信息熵H(D)与特征A给定条件下D的信息条件熵H(D|A)之差,即公式为:g(D,A)=H(D)-H(D|A)
注:信息增益表示得知特征X的信息而使得类Y的信息的不确定性减少的程度
信息增益的计算
结合前面的贷款数据来看我们的公式:
信息熵的计算:
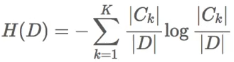
条件熵的计算:

注:Ck表示属于某个类别的样本数,
既然我们有了这两个公式,我们可以根据前面的是否通过贷款申请的例子来通过计算得出我们的决策特征顺序。那么我们首先计算总的经验熵为:
H(D)=-9/15log(9/15)+(6/15)log(6/15)=0.971
然后我们让A1,A2,A3,A4分别表示年龄、有工作、有自己的房子和信贷情况4个特征,则计算出年龄的信息增益为ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 333
333











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









