






在PGConf.dev 2025全球开发者大会上, OpenAI 的Bohan Zhang分享了 OpenAI 使用 PostgreSQL 的最佳实践,让人们得以一窥这家最著名的独角兽公司之一的数据库使用情况。
在 OpenAI,我们采用了一个包含一个写入器和多个读取器的未分片架构,这证明了 PostgreSQL
可以在海量读取负载下优雅地扩展。——PGConf.dev 2025,来自 OpenAI 的 Bohan Zhang
张博涵是OpenAI基础设施团队成员,师从卡内基梅隆大学Andy Pavlo教授,并与其共同创立了OtterTune 。

背景
PostgreSQL 是 OpenAI 核心数据库,支撑着其大部分关键系统。如果 PostgreSQL 发生故障,OpenAI 的许多关键服务将直接受到影响。过去曾发生过数起 PostgreSQL 相关问题导致 ChatGPT 中断的案例。

OpenAI 使用 Azure 上的托管数据库(Azure Database for PostgreSQL),采用经典的 PostgreSQL 主-副本复制架构,无需分片。此设置包含一个主数据库和数十个副本。对于像 OpenAI 这样拥有数百万活跃用户的服务来说,可扩展性是一个重要的考量因素。
挑战
在 OpenAI 的主-副本 PostgreSQL 架构中,读取可扩展性非常出色。然而,“写入请求”已成为主要瓶颈。OpenAI 在这方面实施了多项优化,例如尽可能地卸载写入负载,并避免在主数据库中添加新服务。

PostgreSQL 的多版本并发控制 (MVCC) 设计存在一些已知问题,包括表和索引膨胀。调整自动垃圾收集(清理)可能很复杂,因为每次写入操作都会生成一个全新的版本,并且索引访问可能需要额外的可见性检查。这些设计方面在扩展只读副本时带来了挑战:例如,增加预写日志 (WAL) 可能会导致更大的复制延迟,并且随着副本数量的显著增长,网络带宽可能成为新的瓶颈。
措施
针对这些问题,我们从多方面做出了努力:
控制主数据库负载
第一个优化是平滑主数据库上的写入峰值,以最小化其负载。例如:
- 卸载所有可能的写入操作。
- 避免在应用程序级别进行不必要的写入。
- 使用惰性写入来平滑写入突发。
- 控制数据回填期间的频率。
此外,OpenAI 致力于将尽可能多的读取请求卸载到副本数据库。对于那些由于属于读写事务而无法从主数据库中移除的读取请求,需要更高的效率。

查询优化
第二项优化侧重于查询层。由于长事务会阻碍垃圾回收并消耗资源,因此配置了超时机制以避免出现长时间的“事务空闲”会话,超时设置分别在会话、语句和客户端级别进行。此外,我们还优化了复杂的多连接查询。演讲中还特别提到,使用 ORM 很容易导致查询效率低下,应谨慎使用。

解决单点故障
主数据库是单点故障;如果它发生故障,写入操作将无法进行。相比之下,我们拥有多个只读副本;如果一个副本发生故障,应用程序仍然可以从其他副本读取数据。事实上,许多关键请求都是只读的,因此即使主数据库发生故障,它们也可以继续从只读副本读取数据。
此外,我们区分低优先级和高优先级请求。对于高优先级请求,OpenAI 会分配专用的只读副本,以防止它们受到低优先级请求的影响。

模式管理
第四项措施是仅允许在此集群上进行轻量级架构更改。这意味着:
- 不允许创建新表或引入新的工作负载。
- 允许添加或删除列(超时时间为 5 秒),但不允许任何需要重写整个表的操作。
- 允许创建或删除索引,但必须使用 CONCURRENTLY 选项。
另一个提到的问题是,运行期间长时间运行的查询(> 1 秒)可能会持续阻塞模式更改,最终导致更改失败。解决方案是让应用程序优化或将这些查询卸载到只读副本,这样主节点上的模式更改就不会被阻塞。
结果
扩展 Azure 托管的 PostgreSQL 以处理整个集群中数百万的 QPS(组合读写),从而支持 OpenAI 的关键服务。
添加了数十个副本,但未增加复制滞后。
在保持低延迟的同时,跨不同地理区域部署只读副本。
过去九个月内仅经历过一次与 PostgreSQL 相关的 SEV0 事件。
为未来的增长预留了充足的容量。
事故案例
OpenAI 还分享了几个遇到的问题的案例研究:
第一种情况涉及缓存故障导致的连锁反应。

第二起事件特别有趣:在 CPU 使用率极高的情况下,触发了一个错误,即使在 CPU 水平恢复正常之后,WALSender 进程仍会继续循环旋转,而不是正确地将 WAL 日志发送到副本,从而导致复制滞后增加。

功能请求
最后,Bohan 向 PostgreSQL 开发者社区提出了几个问题和功能请求:
关于索引管理:未使用的索引可能会导致写入放大和额外的维护开销。OpenAI 希望移除不必要的索引,但为了最大限度地降低风险,他们提出了索引的“禁用”功能。这将允许在永久删除索引之前监控性能指标以确保稳定性。
关于可观察性:目前,pg_stat_statements仅提供每种查询类型的平均响应时间,缺乏对 p95 和 p99 延迟指标的直接访问。他们希望提供更多类似于直方图和百分位延迟的指标。
关于模式变化:他们希望 PostgreSQL 记录模式变化事件的历史记录,例如添加或删除列和其他 DDL 操作。
监控视图语义:他们观察到一个会话state = Active持续wait_event = ClientRead了两个多小时。这表明在 QueryStart 之后,连接仍然保持活跃状态,并且此类连接无法通过idle_in_transaction超时终止。他们试图了解这是否是一个 bug,以及如何解决它。
最后,他们建议优化 PostgreSQL 的默认参数,并指出当前的默认值过于保守。他们询问是否可以实现更好的默认值或基于启发式的设置。
老冯的评论
虽然 PGConf.Dev 2025 主要关注开发,但也经常分享用户端用例,例如 OpenAI 使用 PostgreSQL 的可扩展性实践。这类话题对核心开发人员来说其实相当有趣,因为他们中的许多人并不了解 PostgreSQL 在极端实际场景中的使用方法。
自2017年底以来,老冯在探探管理着数十个PostgreSQL集群。当时,探探是中国互联网领域规模最大、最复杂的部署之一:数十个PostgreSQL集群处理着约250万次每秒的查询速度。当时,他们最大的核心集群使用了一个拥有33个副本的主节点,处理着约40万次每秒的查询速度。单节点写入性能也存在瓶颈,最终他们通过在应用程序端进行分库分表来解决了这个问题。
可以说,OpenAI 演讲中遇到的问题和应用的解决方案都是他们以前处理过的事情。当然,现在的情况不同了,如今的顶级硬件比八年前强大得多。这使得像 OpenAI 这样的初创公司可以使用单个 PostgreSQL 集群(无需分片或分区)来服务其整个业务。这无疑为“分布式数据库是虚假需求”的观点提供了又一个强有力的证据。
OpenAI 在 Azure 上使用托管 PostgreSQL,并配备顶级服务器规格。其副本数量相对较高,包括一些跨区域副本。这个庞大的集群总共可处理数百万的 QPS(读取 + 写入)。他们使用 Datadog 进行监控,其服务通过 Kubernetes 内部的应用程序端 PgBouncer 连接池访问 Azure Database for Postgres 集群。
由于 OpenAI 是战略级客户,Azure PostgreSQL 团队提供了非常实际的支持。但显然,即使是顶级的云数据库服务,用户仍然需要具备强大的应用和运维意识和能力。即使有 OpenAI 的智慧支撑,他们在实践中仍然会在 PostgreSQL 运维中遇到陷阱。
会议结束后,晚上的社交活动上,老冯和Bohan以及其他两位数据库创始人聊到了凌晨。私下的谈话非常精彩,不过老冯没能透露更多细节——哈哈。

老冯问答
对于 Bohan 提出的问题和功能请求,Lao Feng 在这里给出了一些答案。事实上,OpenAI 所寻求的大部分功能在 PostgreSQL 生态系统中已经存在——只是核心 PostgreSQL 或 Azure Database for Postgres 中可能没有提供。
关于禁用索引
PostgreSQL 实际上确实有一个禁用索引的功能。您只需在 pg_index 系统目录中将 indisvalid 字段设置为 false 即可。这会使规划器忽略该索引,尽管在 DML 操作期间它仍会保留。从技术角度来看,这完全没问题——这与通过 isready 和 isvalid 标志并发创建索引时使用的机制相同。这并不是什么黑魔法。
话虽如此,但可以理解为什么 OpenAI 不能使用这种方法——Azure Database for Postgres 不授予超级用户权限,因此您不能直接修改系统目录来实现这一点。
但回到最初的目标——避免意外删除索引——有一个更简单的解决方案:只需通过监控视图确认该索引在主服务器和副本服务器上均未被使用即可。如果长时间未访问,则可以安全删除。
使用Pigsty监控系统,可以观察PGSQL表的实时索引切换过程。
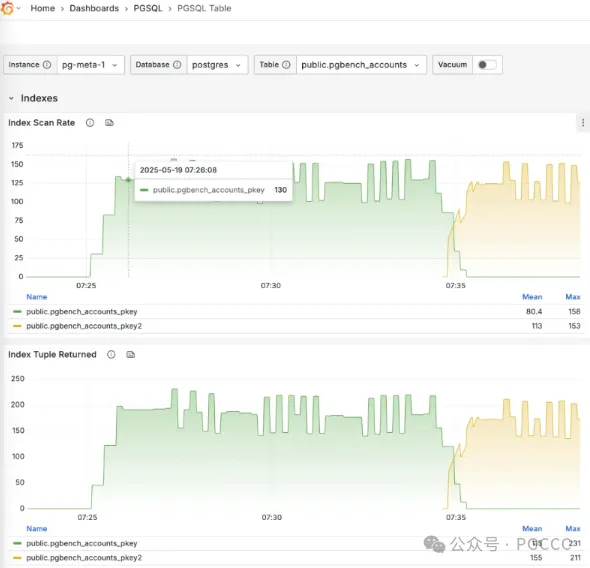
CREATE UNIQUE INDEX CONCURRENTLY pgbench_accounts_pkey2
ON pgbench_accounts USING BTREE(aid);
-- Mark the original index as invalid (won’t be used) but still maintained
UPDATE pg_index SET indisvalid =false
WHERE indexrelid ='pgbench_accounts_pkey'::regclass;
关于可观察性
pg_stat_statements 可能不会很快提供 P95 或 P99 百分位指标,因为这会大幅增加扩展的内存占用——可能增加数十倍。虽然现代服务器可以处理这个问题,但极其保守的环境可能无法处理。我咨询了 pg_stat_statements 的维护者,他表示不太可能实现。我还咨询了 pgbouncer 的维护者 Jelte,他表示短期内也不太可能实现这样的功能。
但这个问题是可以解决的。首先,pg_stat_monitor 扩展确实提供了详细的百分位延迟 (RT) 指标,而且肯定有效,尽管您需要考虑收集此类指标的性能开销。第二个选项是使用 eBPF 被动收集 RT 指标,当然,最简单的方法是直接在应用程序的数据访问层 (DAL) 中添加查询延迟监控。
最优雅的解决方案可能是基于 eBPF 的侧通道收集,但由于他们使用的是 Azure 托管的 PostgreSQL,没有服务器访问权限,因此此选项可能不可行。
关于架构变更历史
实际上,PostgreSQL 日志已经提供了此功能——只需将 log_statement 设置为 ddl(或者更详细地,mod 或 all),所有 DDL 语句都会被记录下来。pgaudit 扩展也提供了类似的功能。
但我怀疑他们真正想要的不是日志,而是一个可以通过 SQL 查询的系统视图。在这种情况下,另一个选择是使用 CREATE EVENT TRIGGER 将 DDL 事件直接记录到数据表中。pg_ddl_historization 扩展提供了一种更简单的方法,我已经编译并打包了这个扩展。
但是,创建事件触发器也需要超级用户权限。AWS RDS 有一些特殊处理来实现这一点,但 Azure 的 PostgreSQL 似乎不支持。
监控视图的语义
在 OpenAI 的示例中,State = Active 表示后端进程仍处于单个 SQL 语句的生命周期内——它尚未向前端发送 ReadyForQuery 消息,因此 PostgreSQL 仍认为该语句“尚未完成”。因此,行锁、缓冲区引脚、快照和文件句柄等资源仍被视为“正在使用中”。WaitEvent = ClientRead 表示进程正在等待来自客户端的输入。当两者同时出现时,典型情况是 COPY FROM STDIN 处于空闲状态,但也可能是由于 TCP 阻塞或卡在 BIND 和 EXECUTE 之间。因此,很难明确地说这是否是一个 bug——这取决于连接的实际操作。
有人可能会认为,从 CPU 的角度来看,等待客户端 I/O 应该算作“空闲”。但 State 跟踪的是语句的执行状态,而不是进程是否正在主动使用 CPU。查询可以处于 Active 状态但不在 CPU 上运行(当 WaitEvent 为 NULL 时),也可以在 CPU 上循环等待客户端输入(即 ClientRead)。
回到核心问题——有办法解决这个问题。例如,在 Pigsty 中,当通过 HAProxy 访问 PostgreSQL 时,主服务在负载均衡器级别设置了最大连接寿命(例如 24 小时)。在更严格的环境中,这个寿命可能短至 1 小时。这意味着超过寿命的连接将被终止。理想情况下,客户端连接池应该主动强制执行连接寿命,而不是强制断开连接。对于离线、只读服务,不需要此超时设置——允许长时间运行的查询,这些查询可能持续数天。这种方法为连接处于活动状态但正在等待 I/O 的情况提供了安全保障。
话虽如此,目前尚不清楚 Azure PostgreSQL 是否提供这种控制。
关于默认参数
PostgreSQL 的默认参数极其保守。例如,它默认内存只有 256 MB(最低可以设置为 256 KB!)。好处是 PostgreSQL 几乎可以在任何环境下启动和运行。缺点呢?我见过一个拥有 1 TB 物理内存的生产环境,仍然以默认的 256 MB 配置运行……(得益于双缓冲,它实际上运行了相当长一段时间。)
总的来说,我认为保守的默认值并非坏事。这个问题可以通过更灵活的动态配置来解决。Azure Database for Postgres 和 Pigsty 等服务提供了精心设计的启发式初始参数调优方法,这已经很好地解决了这个问题。即便如此,此功能仍然可以内置到 PostgreSQL 命令行工具中——例如,在 initdb 期间,该工具可以自动检测 CPU、内存、磁盘大小和类型,并相应地设置合理的默认值。
自托管?
OpenAI 设置中的真正挑战并非源于 PostgreSQL 本身,而是在 Azure 上使用托管 PostgreSQL 的限制。一种解决方案是使用 Azure 或其他云的 IaaS 层在本地 NVMe SSD 实例上部署自托管 PostgreSQL 集群,从而绕过这些限制。
事实上,Pigsty是由老冯专门为解决这种规模的 PostgreSQL 挑战而构建的——它本质上是一个自托管的 Azure Database for Postgres 解决方案,并且具有良好的扩展性。OpenAI 遇到的(或即将遇到的)许多问题,都已经在 Pigsty 中得到了解决方案,Pigsty 是开源且免费的。
如果 OpenAI 感兴趣,我很乐意提供帮助。话虽如此,但当一家公司像他们一样快速扩张时,调整数据库基础架构可能并非当务之急。幸运的是,他们拥有一些优秀的 PostgreSQL DBA,可以继续推进并探索这些路径。
#PostgreSQL培训 #PostgreSQL 培训 #postgreSQL考试 #postgreSQL 考试

















 923
923

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









