






1.目标
实现人脸情绪实时检测,通过摄像头拍摄人脸并显示出相应情感类别。
代码地址:
2.Emotion-Detection-RealTime
2.1 目录结构

2.2 代码结构
模块导入
参数设置
数据处理
模型构建
训练脚本
展示脚本
2.3 具体代码
import numpy as np
import argparse
import cv2
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.python.layers.core import Dense, Dropout, Flatten
# from tensorflow.python.layers.convolutional import Conv2D
from keras.optimizers import Adam
# from tensorflow.python.layers import Conv2D
from tensorflow.keras.layers import Conv2D, Dense, Flatten,Dropout,MaxPooling2D
# from tensorflow.python.layers.pooling import MaxPooling2D
from keras.preprocessing.image import ImageDataGenerator
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import matplotlib as mpl
mpl.use('TkAgg')
import matplotlib.pyplot as plt
import tensorflow as tf
# command line argument
ap = argparse.ArgumentParser()
ap.add_argument("--mode",default='train',help="train/display")
a = ap.parse_args()
mode = a.mode
def plot_model_history(model_history):
"""
Plot Accuracy and Loss curves given the model_history
"""
fig, axs = plt.subplots(1,2,figsize=(15,5))
# summarize history for accuracy
axs[0].plot(range(1,len(model_history.history['acc'])+1),model_history.history['acc'])
axs[0].plot(range(1,len(model_history.history['val_acc'])+1),model_history.history['val_acc'])
axs[0].set_title('Model Accuracy')
axs[0].set_ylabel('Accuracy')
axs[0].set_xlabel('Epoch')
axs[0].set_xticks(np.arange(1,len(model_history.history['acc'])+1),len(model_history.history['acc'])/10)
axs[0].legend(['train', 'val'], loc='best')
# summarize history for loss
axs[1].plot(range(1,len(model_history.history['loss'])+1),model_history.history['loss'])
axs[1].plot(range(1,len(model_history.history['val_loss'])+1),model_history.history['val_loss'])
axs[1].set_title('Model Loss')
axs[1].set_ylabel('Loss')
axs[1].set_xlabel('Epoch')
axs[1].set_xticks(np.arange(1,len(model_history.history['loss'])+1),len(model_history.history['loss'])/10)
axs[1].legend(['train', 'val'], loc='best')
fig.savefig('plot.png')
plt.show()
# Define data generators
train_dir = 'data/data/train'
val_dir = 'data/data/test'
num_train = 28709
num_val = 7178
batch_size = 64
num_epoch = 50
train_datagen = ImageDataGenerator(rescale=1./255)
val_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(48,48),
batch_size=batch_size,
color_mode="grayscale",
class_mode='categorical')
validation_generator = val_datagen.flow_from_directory(
val_dir,
target_size=(48,48),
batch_size=batch_size,
color_mode="grayscale",
class_mode='categorical')
# Create the model
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=(48,48,1)))
model.add(Conv2D(64, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2),strides=(2,2)))
model.add(Dropout(0.25))
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2),strides=(2,2)))
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2),strides=(2,2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(1024, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(7, activation='softmax'))
# If you want to train the same model or try other models, go for this
if mode == "train":
# 使用旧版本的Adam优化器
# optimizer = tf.keras.optimizers.legacy.Adam(learning_rate=0.001, decay=1e-6)
# model.compile(loss='categorical_crossentropy',optimizer=Adam(learning_rate=0.0001, decay=0.9),metrics=['accuracy'])
model.compile(loss='categorical_crossentropy', optimizer = tf.keras.optimizers.Adam(lr=0.001, decay=1e-6),metrics=['accuracy'])
model_info = model.fit_generator(
train_generator,
steps_per_epoch=num_train // batch_size,
epochs=num_epoch,
validation_data=validation_generator,
validation_steps=num_val // batch_size)
plot_model_history(model_info)
model.save_weights('model.h5')
# emotions will be displayed on your face from the webcam feed
elif mode == "display":
model.build((None, 48, 48, 1))
model.load_weights(r'E:\pycharm_item\pyqt\EmotionDetection_RealTime-master\model.h5')
# prevents openCL usage and unnecessary logging messages
cv2.ocl.setUseOpenCL(False)
# dictionary which assigns each label an emotion (alphabetical order)
emotion_dict = {0: "Angry", 1: "Disgusted", 2: "Fearful", 3: "Happy", 4: "Neutral", 5: "Sad", 6: "Surprised"}
# start the webcam feed
cap = cv2.VideoCapture(0)
while True:
# Find haar cascade to draw bounding box around face
ret, frame = cap.read()
facecasc = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = facecasc.detectMultiScale(gray,scaleFactor=1.3, minNeighbors=5)
for (x, y, w, h) in faces:
cv2.rectangle(frame, (x, y-50), (x+w, y+h+10), (255, 0, 0), 2)
roi_gray = gray[y:y + h, x:x + w]
cropped_img = np.expand_dims(np.expand_dims(cv2.resize(roi_gray, (48, 48)), -1), 0)
prediction = model.predict(cropped_img)
maxindex = int(np.argmax(prediction))
cv2.putText(frame, emotion_dict[maxindex], (x+20, y-60), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 255, 255), 2, cv2.LINE_AA)
# show the output frame
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
cap.release()
cv2.destroyAllWindows()
2.4 代码分析
2.4.1 模块导入
import numpy as np
import argparse
import cv2
from keras.models import Sequential
from tensorflow.python.layers.core import Dense, Dropout, Flatten
from tensorflow.python.layers.convolutional import Conv2D
from keras.optimizers import Adam
from tensorflow.python.layers.pooling import MaxPooling2D
from keras.preprocessing.image import ImageDataGenerator
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import matplotlib as mpl
mpl.use('TkAgg')
import matplotlib.pyplot as plt
import tensorflow as tf(1)import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
设置TensorFlow的日志级别为仅显示错误信息:
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
- TensorFlow 默认会输出一些额外的信息,这行代码将日志级别设置为2,表示只显示错误信息,可以减少不必要的输出,使输出更清晰
(2) import matplotlib as mpl
mpl.use('TkAgg')
配置Matplotlib以在TkAgg后端上运行:
mpl.use('TkAgg')
- Matplotlib 是一个用于绘图的 Python 库,在使用 Matplotlib 时,需要指定后端以确定图形如何显示。
TkAgg是一个 Matplotlib 的后端,使用 Tkinter 提供的 GUI 工具包来显示图形。- 这行代码将 Matplotlib 的后端设置为
TkAgg,确保图形能够在 Tkinter GUI 上正确显示。
2.4.2 参数设置
ap = argparse.ArgumentParser()
ap.add_argument("--mode",default='display',help="train/display")
a = ap.parse_args()
mode = a.mode 这段代码使用了 Python 的 argparse 模块来解析命令行参数,并定义了一个名为 "mode" 的参数,其默认值为 "display"。具体解释如下:
1.ap = argparse.ArgumentParser(): 创建了一个参数解析器对象。
2.ap.add_argument("--mode", default='display', help="train/display"): 向参数解析器中添加了一个名为 "--mode" 的参数。其中:
3."--mode" 表示参数的名称;
4.default='display' 表示参数的默认值为 "display";
5.help="train/display" 提供了关于参数的简短描述,提示用户可以设置参数为 "train" 或 "display"。
6.a = ap.parse_args(): 解析了命令行参数,并将结果存储在变量 a 中。
7.mode = a.mode: 从解析结果中获取了参数 "--mode" 的值,并将其存储在变量 mode 中。这样,通过命令行可以指定 --mode 参数的值为 "train" 或 "display",而在代码中可以通过 mode 变量来获取这个值,从而控制程序的行为。例如,如果用户在命令行中设置了 --mode train,那么在代码中 mode 的值将为 "train",程序将以训练模式运行。
2.4.3 数据处理
train_dir = 'data/data/train'
val_dir = 'data/data/test'
num_train = 28709
num_val = 7178
batch_size = 64
num_epoch = 50
train_datagen = ImageDataGenerator(rescale=1./255)
val_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(48,48),
batch_size=batch_size,
color_mode="grayscale",
class_mode='categorical')
validation_generator = val_datagen.flow_from_directory(
val_dir,
target_size=(48,48),
batch_size=batch_size,
color_mode="grayscale",
class_mode='categorical')(1)train_datagen = ImageDataGenerator(rescale=1./255)
这行代码使用 Keras 中的 ImageDataGenerator 类来创建一个图像数据生成器对象 train_datagen,用于对训练图像进行数据增强和预处理。
参数说明:1.rescale=1./255:将图像的像素值缩放到 [0, 1] 的范围内。这样做是为了将原始图像的像素值(通常为整数值在 [0, 255] 范围内)归一化到 0 到 1 之间,以便更好地进行模型训练。
通过数据生成器对象,可以在训练过程中实时生成经过预处理和数据增强的图像批次,以供模型训练使用。数据增强技术有助于增加训练数据的多样性,提高模型的泛化能力,从而改善模型的性能。
(2) train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(48,48),
batch_size=batch_size,
color_mode="grayscale",
class_mode='categorical')
2.4.4 模型构建
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=(48,48,1)))
model.add(Conv2D(64, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2),strides=(2,2)))
model.add(Dropout(0.25))
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2),strides=(2,2)))
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2),strides=(2,2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(1024, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(7, activation='softmax'))这段代码定义了一个卷积神经网络模型,使用了 Keras 的 Sequential 模型。以下是模型的层次结构和参数说明:
输入层:
- 输入图像的大小为 (48, 48, 1),即图像的高度为 48 像素,宽度为 48 像素,通道数为 1(灰度图像)。
卷积层1:
- 32 个大小为 (3, 3) 的卷积核。
- ReLU 激活函数。
卷积层2:
- 64 个大小为 (3, 3) 的卷积核。
- ReLU 激活函数。
最大池化层1:
- 池化窗口大小为 (2, 2)。
- 步幅为 (2, 2)。
Dropout 层1:
- 丢弃率为 0.25,用于减少过拟合。
卷积层3:
- 128 个大小为 (3, 3) 的卷积核。
- ReLU 激活函数。
最大池化层2:
- 池化窗口大小为 (2, 2)。
- 步幅为 (2, 2)。
卷积层4:
- 128 个大小为 (3, 3) 的卷积核。
- ReLU 激活函数。
最大池化层3:
- 池化窗口大小为 (2, 2)。
- 步幅为 (2, 2)。
Dropout 层2:
- 丢弃率为 0.25,用于减少过拟合。
Flatten 层:
- 将多维输入展平为一维。
全连接层1:
- 1024 个神经元。
- ReLU 激活函数。
Dropout 层3:
- 丢弃率为 0.5,用于减少过拟合。
全连接层2(输出层):
- 7 个神经元,对应于输出类别的数量(假设是 7 类)。
- 使用 softmax 激活函数,用于多类别分类问题。
这个模型结构是一个经典的卷积神经网络结构,用于图像分类任务。
2.4.5 训练脚本
if mode == "train":
# 使用旧版本的Adam优化器
# optimizer = tf.keras.optimizers.legacy.Adam(learning_rate=0.001, decay=1e-6)
# model.compile(loss='categorical_crossentropy',optimizer=Adam(learning_rate=0.0001, decay=0.9),metrics=['accuracy'])
model.compile(loss='categorical_crossentropy', optimizer = tf.keras.optimizers.legacy.Adam(learning_rate=0.001, decay=1e-6),metrics=['accuracy'])
model_info = model.fit_generator(
train_generator,
steps_per_epoch=num_train // batch_size,
epochs=num_epoch,
validation_data=validation_generator,
validation_steps=num_val // batch_size)
plot_model_history(model_info)
model.save_weights('model.h5')(1) model.compile(loss='categorical_crossentropy', optimizer = tf.keras.optimizers.legacy.Adam(learning_rate=0.001, decay=1e-6),metrics=['accuracy'])
这行代码使用 Keras 中的 ImageDataGenerator 类来创建一个图像数据生成器对象 train_datagen,用于对训练图像进行数据增强和预处理。
参数说明:1.rescale=1./255:将图像的像素值缩放到 [0, 1] 的范围内。这样做是为了将原始图像的像素值(通常为整数值在 [0, 255] 范围内)归一化到 0 到 1 之间,以便更好地进行模型训练。
通过数据生成器对象,可以在训练过程中实时生成经过预处理和数据增强的图像批次,以供模型训练使用。数据增强技术有助于增加训练数据的多样性,提高模型的泛化能力,从而改善模型的性能。
(2) model_info = model.fit_generator(
train_generator,
steps_per_epoch=num_train // batch_size,
epochs=num_epoch,
validation_data=validation_generator,
validation_steps=num_val // batch_size)
这行代码使用了 train_datagen 这个图像数据生成器来生成训练集的数据。具体参数说明如下:
1.flow_from_directory():从目录中生成批量的数据和标签。
2.train_dir:指定训练数据所在的目录。
3.target_size=(48,48):将输入图像调整为指定的大小,这里调整为 48x48 像素。
4.batch_size:指定每个批次的大小。
5.color_mode="grayscale":将图像转换为灰度模式,即单通道图像,因为训练数据通常不需要使用彩色信息。
6.class_mode='categorical':指定分类方式为 categorical,即多类别分类。通过这行代码,train_generator 成为一个可以用于迭代访问训练数据的生成器对象,每次迭代会生成一个批次的图像数据和对应的标签,用于模型的训练。
(3) plot_model_history(model_info)
plot_model_history(model_info) 这个函数的作用是绘制模型的训练过程中的历史数据,通常包括训练集和验证集上的损失值和准确率随着训练轮数的变化趋势。这有助于直观地了解模型的训练情况,以及判断模型是否存在过拟合或欠拟合等问题。
通常情况下,model_info 参数是一个字典,包含了模型训练过程中的历史数据,比如损失值和准确率。这个函数会使用这些数据来生成训练过程的可视化图表,以便分析模型的性能和训练进度。
你可能需要在代码中定义这个函数,或者使用相关的库(如 Matplotlib)来实现这个功能。
(4) model.save_weights('model.h5')
这行代码用于将模型的权重保存到名为 "model.h5" 的文件中。具体说明如下:
1.model.save_weights('model.h5'):将当前模型的权重保存到名为 "model.h5" 的 HDF5 格式文件中。这个文件可以包含模型的所有权重参数,方便以后加载模型并恢复训练,或者在其他地方使用相同架构的模型。
这个步骤通常在模型训练完成后用于保存模型的权重,以便在需要时重新加载模型并使用它,或者在其他环境中部署模型。
2.4.6 训练结果展示
def plot_model_history(model_history):
"""
Plot Accuracy and Loss curves given the model_history
"""
fig, axs = plt.subplots(1,2,figsize=(15,5))
# summarize history for accuracy
axs[0].plot(range(1,len(model_history.history['acc'])+1),model_history.history['acc'])
axs[0].plot(range(1,len(model_history.history['val_acc'])+1),model_history.history['val_acc'])
axs[0].set_title('Model Accuracy')
axs[0].set_ylabel('Accuracy')
axs[0].set_xlabel('Epoch')
axs[0].set_xticks(np.arange(1,len(model_history.history['acc'])+1),len(model_history.history['acc'])/10)
axs[0].legend(['train', 'val'], loc='best')
# summarize history for loss
axs[1].plot(range(1,len(model_history.history['loss'])+1),model_history.history['loss'])
axs[1].plot(range(1,len(model_history.history['val_loss'])+1),model_history.history['val_loss'])
axs[1].set_title('Model Loss')
axs[1].set_ylabel('Loss')
axs[1].set_xlabel('Epoch')
axs[1].set_xticks(np.arange(1,len(model_history.history['loss'])+1),len(model_history.history['loss'])/10)
axs[1].legend(['train', 'val'], loc='best')
fig.savefig('plot.png')
plt.show()这是一个用于绘制模型训练过程中准确率和损失值变化曲线的函数。函数的输入是一个包含模型训练历史数据的字典 model_history,其中包括训练集和验证集上的准确率和损失值。
函数的主要步骤如下:1.创建一个包含两个子图的图形对象,分别用于绘制准确率曲线和损失值曲线。
2.在第一个子图中绘制训练集和验证集的准确率曲线。
3.在第二个子图中绘制训练集和验证集的损失值曲线。
4.设置图表标题、坐标轴标签和图例。
5.将图表保存为文件 "plot.png"。
6.显示图表。这个函数可以帮助你可视化模型的训练过程,以便更好地理解模型的性能和训练进度。请确保在使用之前导入所需的库,如 Matplotlib 和 NumPy。
2.4.7 人脸识别脚本
elif mode == "display":
model.build((None, 48, 48, 1))
model.load_weights(r'E:\pycharm_item\pyqt\EmotionDetection_RealTime-master\model.h5')
# prevents openCL usage and unnecessary logging messages
cv2.ocl.setUseOpenCL(False)
# dictionary which assigns each label an emotion (alphabetical order)
emotion_dict = {0: "Angry", 1: "Disgusted", 2: "Fearful", 3: "Happy", 4: "Neutral", 5: "Sad", 6: "Surprised"}
# start the webcam feed
cap = cv2.VideoCapture(0)
while True:
# Find haar cascade to draw bounding box around face
ret, frame = cap.read()
facecasc = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = facecasc.detectMultiScale(gray,scaleFactor=1.3, minNeighbors=5)
for (x, y, w, h) in faces:
cv2.rectangle(frame, (x, y-50), (x+w, y+h+10), (255, 0, 0), 2)
roi_gray = gray[y:y + h, x:x + w]
cropped_img = np.expand_dims(np.expand_dims(cv2.resize(roi_gray, (48, 48)), -1), 0)
prediction = model.predict(cropped_img)
maxindex = int(np.argmax(prediction))
cv2.putText(frame, emotion_dict[maxindex], (x+20, y-60), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 255, 255), 2, cv2.LINE_AA)
# show the output frame
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF(1) model.build((None, 48, 48, 1))
model.build((None, 48, 48, 1)) 这行代码用于构建模型的网络结构,指定模型的输入形状。具体来说:
1.(None, 48, 48, 1) 指定了模型的输入形状。在这里,(None, 48, 48, 1) 表示输入数据的形状为 (batch_size, height, width, channels),其中:
2.batch_size 是输入的批量大小,这里使用 None 表示可以接受任意大小的批量输入。
3.height 是输入图像的高度,这里为 48 像素。
4.width 是输入图像的宽度,这里为 48 像素。
5.channels 是输入图像的通道数,这里为 1,表示灰度图像。通过这行代码,模型被构建并指定了输入的形状,使其准备好接受对应形状的输入数据进行处理。通常,在训练模型之前,需要先调用 build 方法来构建模型,以便指定输入形状并初始化模型的权重。
(2) model.load_weights(r'E:\pycharm_item\pyqt\EmotionDetection_RealTime-master\model.h5')
model.load_weights() 函数用于加载模型的权重参数,通常是在训练好的模型上进行预测或继续训练时使用。在这个例子中,模型的权重参数保存在文件路径 E:\pycharm_item\pyqt\EmotionDetection_RealTime-master\model.h5 中。
通过调用 model.load_weights() 函数,并传入权重文件的路径作为参数,可以将保存在该文件中的模型权重加载到当前模型中,从而恢复模型的训练状态或用于进行预测。
一旦权重加载完成,该模型就可以在预测新数据或继续训练时使用之前训练的参数。
(3) cv2.ocl.setUseOpenCL(False)
cv2.ocl.setUseOpenCL(False) 这行代码是用于禁用 OpenCL 加速的功能,它通常用于 OpenCV 库中。OpenCL 是一种用于并行计算的开放标准,允许利用 GPU 或其他计算设备来加速图像处理和计算任务。
有时在使用 OpenCV 进行图像处理时,可能会出现一些兼容性或性能问题,特别是在某些设备或平台上。因此,通过调用 cv2.ocl.setUseOpenCL(False) 函数,可以显式地禁用 OpenCL 加速,从而确保算法的正确性和稳定性。
在一些情况下,禁用 OpenCL 可能会导致一些性能上的损失,但通常只在特定情况下会对图像处理产生显著影响。
(4) emotion_dict = {0: "Angry", 1: "Disgusted", 2: "Fearful", 3: "Happy", 4: "Neutral", 5: "Sad", 6: "Surprised"}
emotion_dict 是一个字典,用于将模型输出的数字类别标签映射到对应的情绪类别。每个键值对都表示了一个情绪类别的对应关系,其中键是模型输出的类别标签,值是对应的情绪类别名称。
具体来说,这里的映射关系如下:1.0 对应 "Angry"(愤怒)
2.1 对应 "Disgusted"(厌恶)
3.2 对应 "Fearful"(害怕)
4.3 对应 "Happy"(快乐)
5.4 对应 "Neutral"(中性)
6.5 对应 "Sad"(悲伤)
7.6 对应 "Surprised"(惊讶)通过这个映射字典,可以将模型输出的数字类别标签转换为对应的情绪类别名称,从而更直观地理解模型的预测结果。
(5) cap = cv2.VideoCapture(0)
这行代码创建了一个名为 cap 的视频捕获对象,用于从摄像头中捕获实时视频流。参数 0 指定了要使用的摄像头设备的索引,其中 0 通常表示默认的摄像头设备。
一旦创建了视频捕获对象,就可以使用它来捕获实时视频帧,进行图像处理、分析或显示等操作。这对于实时的计算机视觉应用非常有用,例如人脸检测、姿态估计、情绪识别等。
(6) while True:
# Find haar cascade to draw bounding box around face
ret, frame = cap.read()
facecasc = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = facecasc.detectMultiScale(gray,scaleFactor=1.3, minNeighbors=5)
这段代码是一个无限循环,用于持续地从摄像头捕获实时视频帧,并在检测到的人脸周围绘制边界框。
在循环的每次迭代中,执行以下步骤:1.使用 cap.read() 方法读取一帧视频,其中 cap 是之前创建的视频捕获对象。
2.使用 cv2.CascadeClassifier('haarcascade_frontalface_default.xml') 加载人脸检测器的 Haar 级联分类器。
3.将读取的视频帧转换为灰度图像,以便后续的人脸检测。
4.使用 facecasc.detectMultiScale(gray, scaleFactor=1.3, minNeighbors=5) 方法检测灰度图像中的人脸,并返回检测到的人脸位置信息(矩形框)。在这个循环中,不断地获取视频帧,然后在每一帧上执行人脸检测,并得到人脸的位置信息。检测到的人脸位置信息将存储在 faces 变量中,以便后续的处理和绘制边界框。
(7)for (x, y, w, h) in faces:
cv2.rectangle(frame, (x, y-50), (x+w, y+h+10), (255, 0, 0), 2)
roi_gray = gray[y:y + h, x:x + w]
cropped_img = np.expand_dims(np.expand_dims(cv2.resize(roi_gray, (48, 48)), -1), 0)
prediction = model.predict(cropped_img)
maxindex = int(np.argmax(prediction))
cv2.putText(frame, emotion_dict[maxindex], (x+20, y-60), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 255, 255), 2, cv2.LINE_AA)
这段代码是在检测到的人脸周围绘制边界框,并使用模型对人脸进行情绪识别,并将识别结果在图像上显示出来。
具体来说,代码执行以下操作:1.使用 cv2.rectangle 在帧 frame 上绘制一个矩形框,用于框定检测到的人脸区域。矩形框的坐标由 (x, y) 和 (x+w, y+h) 定义,颜色为 (255, 0, 0)(蓝色),线宽为 2。
2.从灰度图像 gray 中提取出人脸区域的灰度图像 roi_gray,该区域由矩形框 (x, y, w, h) 定义。
3.使用 cv2.resize 调整 roi_gray 的大小为 (48, 48),并添加两个维度扩展为 (1, 48, 48, 1) 的数组,以符合模型输入的要求。
4.使用模型 model 对调整大小后的人脸图像进行情绪预测,得到预测结果 prediction。
5.通过 np.argmax(prediction) 找到预测结果中概率最高的类别索引 maxindex。
6.使用 cv2.putText 在帧 frame 上绘制预测的情绪类别文字,坐标为 (x+20, y-60),字体为 cv2.FONT_HERSHEY_SIMPLEX,字体大小为 1,颜色为 (255, 255, 255)(白色),线宽为 2,字体线型为 cv2.LINE_AA。这段代码实现了在实时视频中检测人脸并进行情绪识别,然后在检测到的人脸周围绘制边界框并显示识别结果。
(8) cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
这部分代码使用 OpenCV 的 cv2.imshow() 方法在窗口中显示处理后的帧 frame,窗口标题为 "Frame"。然后使用 cv2.waitKey() 方法等待用户按下键盘上的键,并返回按键的 ASCII 值(只保留最后八位)。通常情况下,等待键盘输入的时间为 1 毫秒。
在这个循环中,窗口会一直显示帧 frame,直到用户按下键盘上的键为止。然后,将按键的 ASCII 值与 0xFF 进行按位与运算,以确保得到的结果在 0 到 255 的范围内。这个过程可以确保在不同的操作系统上都能正确处理键盘输入。
(9)if key == ord("q"):
break
这个条件语句检查用户是否按下了键盘上的 "q" 键。如果按下了 "q" 键(即按键的 ASCII 值等于 "q" 的 ASCII 值),则会执行 break 语句,退出循环,从而结束程序的执行。
这段代码允许用户在观看视频流的过程中按下 "q" 键来退出程序,以提供用户控制程序执行的能力。
(10)cap.release()
cv2.destroyAllWindows()
这两行代码用于释放摄像头资源并关闭所有的 OpenCV 窗口。具体来说:
1.cap.release() 释放了之前创建的视频捕获对象 cap,这样就会停止视频流的捕获。
2.cv2.destroyAllWindows() 关闭了所有通过 OpenCV 打开的窗口,包括之前用于显示视频流的窗口。这两行代码通常在程序的最后用于清理工作,以确保在程序退出时释放资源并关闭窗口,避免资源泄漏和窗口未关闭的情况。
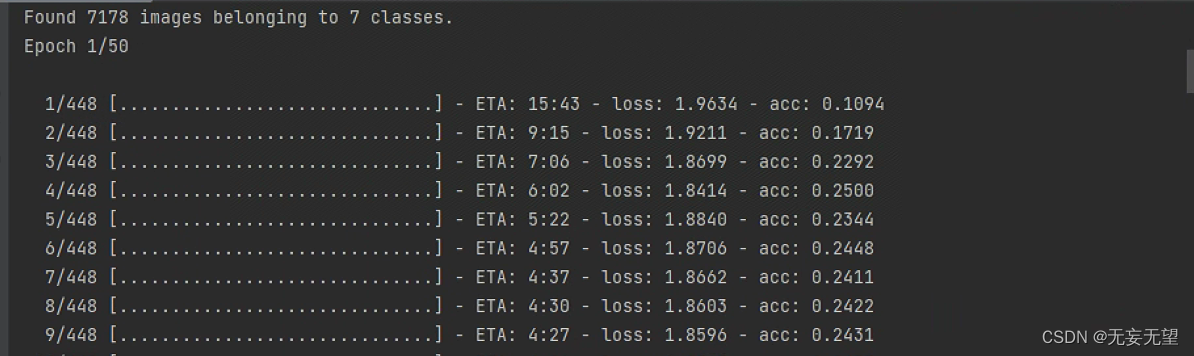
3.运行结果
train模式
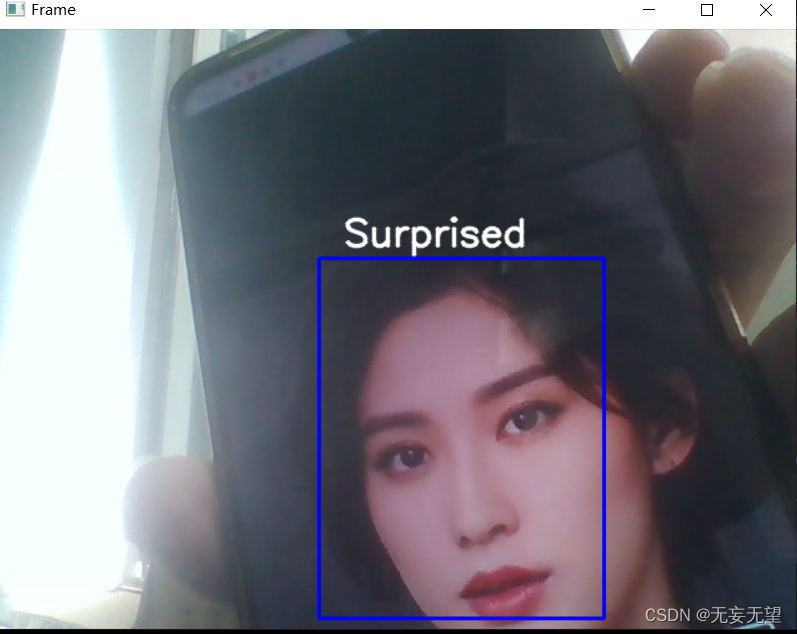
 display模式
display模式














 6783
6783











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









