










石子合并
设有 𝑁 堆石子排成一排,其编号为 1,2,3,…,𝑁。
每堆石子有一定的质量,可以用一个整数来描述,现在要将这 𝑁 堆石子合并成为一堆。
每次只能合并相邻的两堆,合并的代价为这两堆石子的质量之和,合并后与这两堆石子相邻的石子将和新堆相邻,合并时由于选择的顺序不同,合并的总代价也不相同。
例如有 4 堆石子分别为 1 3 5 2, 我们可以先合并 1、2 堆,代价为 44,得到 4 5 2, 又合并 1、2 堆,代价为 9,得到 9 2 ,再合并得到 11,总代价为 4+9+11=24;
如果第二步是先合并2、3 堆,则代价为 7,得到 4 7,最后一次合并代价为 11,总代价为4+7+11=22。
问题是:找出一种合理的方法,使总的代价最小,输出最小代价。
输入格式
第一行一个数 𝑁 表示石子的堆数 𝑁。
第二行 𝑁 个数,表示每堆石子的质量(均不超过1000)。
输出格式
输出一个整数,表示最小代价。
数据范围
1≤𝑁≤300
输入样例:
4
1 3 5 2
输出样例:
22
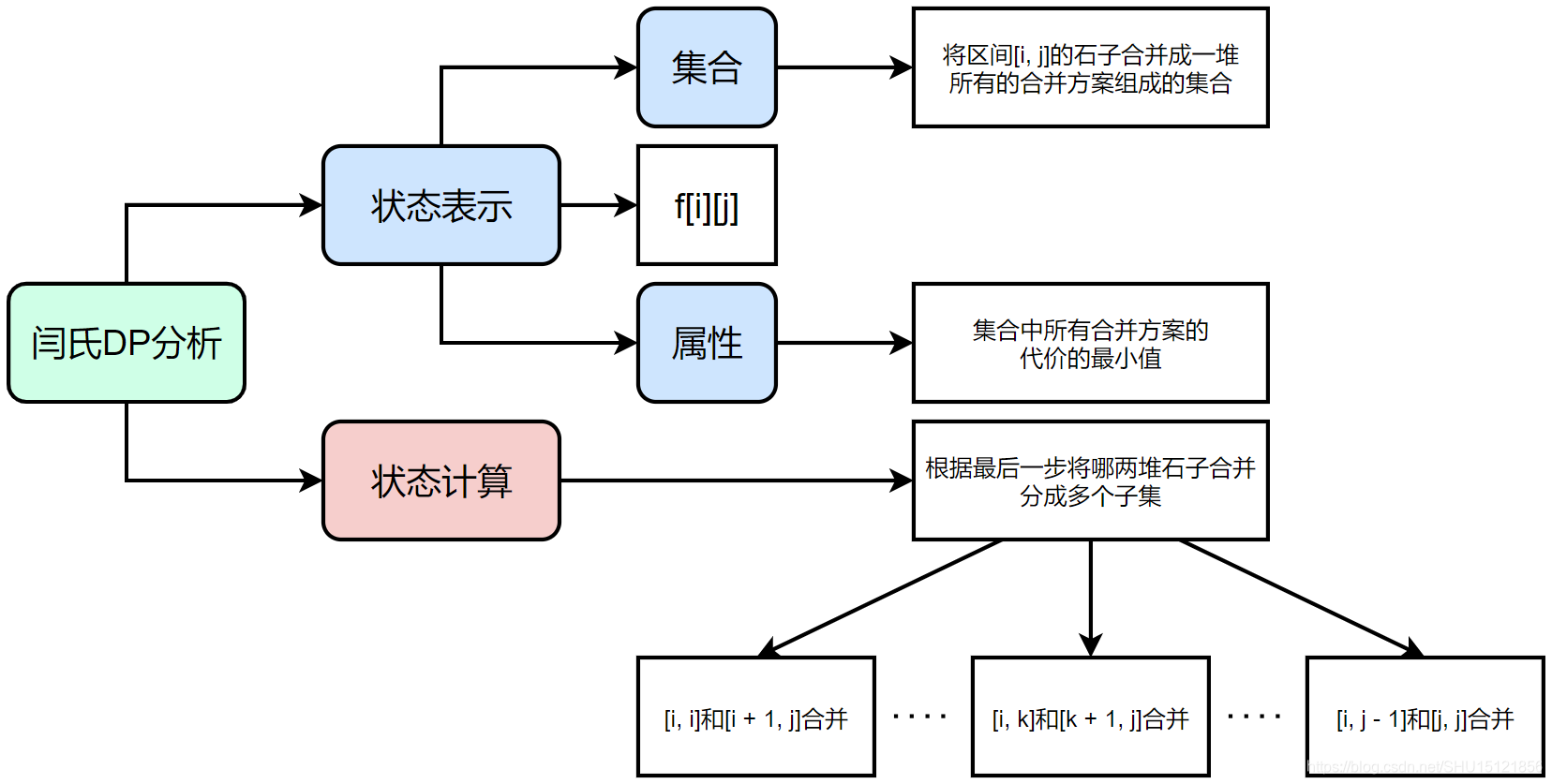
题意:合并 N 堆石子,每次只能合并相邻的两堆石子,求最小代价
解题思路:
关键点:最后一次合并一定是左边连续的一部分和右边连续的一部分进行合并
状态表示:f[i][j]表示将 i 到 j这一段石子合并成一堆的方案的集合,属性 Min
状态计算:
(1) i<j 时,f[i][j]=mini≤k≤j−1{f[i][k]+f[k+1][j]+s[j]−s[i−1]}
(2)i=j 时, f[i][i]=0(合并一堆石子代价为 0)
问题答案: f[1][n]
区间 DP 常用模版
所有的区间dp问题枚举时,第一维通常是枚举区间长度,并且一般 len = 1 时用来初始化,枚举从 len = 2 开始;第二维枚举起点 i (右端点 j 自动获得,j = i + len - 1)
模板代码如下:
for (int len = 1; len <= n; len++) { // 区间长度
for (int i = 1; i + len - 1 <= n; i++) { // 枚举起点
int j = i + len - 1; // 区间终点
if (len == 1) {
dp[i][j] = 初始值
continue;
}
for (int k = i; k < j; k++) { // 枚举分割点,构造状态转移方程
dp[i][j] = min(dp[i][j], dp[i][k] + dp[k + 1][j] + w[i][j]);
}
}
}
C++代码
#include <iostream>
#include <cstring>
using namespace std;
const int N = 307;
int a[N], s[N];
int f[N][N];
int main() {
int n;
cin >> n;
for (int i = 1; i <= n; i ++) {
cin >> a[i];
s[i] += s[i - 1] + a[i];
}
memset(f, 0x3f, sizeof f);
// 区间 DP 枚举套路:长度+左端点
for (int len = 1; len <= n; len ++) { // len表示[i, j]的元素个数
for (int i = 1; i + len - 1 <= n; i ++) {
int j = i + len - 1; // 自动得到右端点
if (len == 1) {
f[i][j] = 0; // 边界初始化
continue;
}
for (int k = i; k <= j - 1; k ++) { // 必须满足k + 1 <= j
f[i][j] = min(f[i][j], f[i][k] + f[k + 1][j] + s[j] - s[i - 1]);
}
}
}
cout << f[1][n] << endl;
return 0;
}
补充1:从下往上倒着枚举状态

除了按长度枚举,也可以倒着枚举,因为只要保证每种状态都被提前计算即可
从下往上倒着枚举,可以保证你算dp[i][j]时,dp[i][k]和dp[k + 1][j]一定是被提前计算好的,而从上往下枚举则无法保证这一点。所以我们采用倒着枚举
#include <iostream>
using namespace std;
const int N = 307;
int s[N];
int f[N][N];
int main() {
int n;
cin >> n;
for (int i = 1; i <= n; i++) {
cin >> s[i];
s[i] += s[i - 1];
}
for (int i = n; i >= 1; i--) {
for (int j = i; j <= n; j++) {
if (j == i) {
f[i][j] = 0;
continue;
}
f[i][j] = 1e9;
for (int k = i; k < j; k++) {
f[i][j] = min(f[i][j], f[i][k] + f[k + 1][j] + s[j] - s[i - 1]);
}
}
}
cout << f[1][n] << endl;
return 0;
}
补充2:记忆化搜索

如果学过后面的记忆化搜索,那也可以用下面的代码。虽然时间会比递推稍微慢一丢丢,但是呢他的思路比较好写
#include <iostream>
#include <cstring>
using namespace std;
const int N = 307;
int a[N], s[N];
int f[N][N];
// 记忆化搜索:dp的记忆化递归实现
int dp(int i, int j) {
if (i == j) return 0; // 判断边界
int &v = f[i][j];
if (v != -1) return v;
v = 1e8;
for (int k = i; k <= j - 1; k ++)
v = min(v, dp(i, k) + dp(k + 1, j) + s[j] - s[i - 1]);
return v;
}
int main() {
int n;
cin >> n;
for (int i = 1; i <= n; i ++) {
cin >> a[i];
s[i] += s[i - 1] + a[i];
}
memset(f, -1, sizeof f);
cout << dp(1, n) << endl;
return 0;
}















 2376
2376

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









