






1.代码
from selenium import webdriver
from selenium.webdriver.edge.service import Service as EdgeService
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from bs4 import BeautifulSoup
import csv
import time
# Edge 驱动路径
EDGE_DRIVER_PATH = "C:\\Program Files (x86)\\Microsoft\\Edge\\edgedriver_win64\\msedgedriver.exe"
# 初始化 Edge 驱动
options = webdriver.EdgeOptions()
options.add_argument("--window-size=1920,1080") # 设置窗口大小
# options.add_argument("--headless") # 无界面模式(如需调试界面,可注释此行)
service = EdgeService(EDGE_DRIVER_PATH)
driver = webdriver.Edge(service=service, options=options)
# 输出文件
output_file = "university_rankings_edge.csv"
# 写入表头
with open(output_file, mode='w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerow(["排名", "名称", "国家/地区", "全职学生数量", "每位教职员对学生数量", "国际学生", "女生对男生比例"])
# 解析表格数据
def parse_table(html):
soup = BeautifulSoup(html, "html.parser")
rows = soup.select("tr.js-row")
data = []
for row in rows:
try:
rank = row.select_one(".rank").text.strip()
name = row.select_one(".ranking-institution-title").text.strip()
country = row.select_one(".location span a").text.strip()
students = row.select_one(".stats_number_students").text.strip()
ratio = row.select_one(".stats_student_staff_ratio").text.strip()
intl_students = row.select_one(".stats_pc_intl_students").text.strip()
female_male_ratio = row.select_one(".stats_female_male_ratio").text.strip()
data.append([rank, name, country, students, ratio, intl_students, female_male_ratio])
except AttributeError:
continue # 跳过缺少数据的行
return data
# 主程序:通过修改路由 URL 翻页抓取
try:
base_url = "https://www.timeshighereducation.com/cn/world-university-rankings/2024/world-ranking"
page = 1
while True:
# 构造分页 URL
url = f"{base_url}?page={page}#page={page}"
print(f"正在抓取第 {page} 页: {url}")
# 打开目标页面
driver.get(url)
# 等待表格加载完成
wait = WebDriverWait(driver, 10)
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "tr.js-row")))
# 获取页面 HTML 并解析
html = driver.page_source
table_data = parse_table(html)
# 如果没有数据,说明到最后一页,退出循环
if not table_data:
print("没有更多数据,结束爬取!")
break
# 保存数据
with open(output_file, mode='a', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerows(table_data)
print(f"第 {page} 页已保存 {len(table_data)} 条数据")
# 下一页
page += 1
# 延迟避免触发反爬机制
time.sleep(3)
finally:
driver.quit()
print("数据爬取完成!")
2.分析
这段代码实现了通过 Selenium 和 BeautifulSoup 从 Times Higher Education 网站抓取世界大学排名数据并保存到 CSV 文件的功能。其主要思路是通过分页访问网站内容,解析表格数据并写入文件。
2.1工具使用
- Selenium 用于模拟浏览器操作,包括加载网页和等待动态内容加载。Edge 浏览器被选为驱动。
- BeautifulSoup 用于解析页面 HTML,并提取特定表格内容。
soup.select("tr.js-row")是使用 BeautifulSoup 提供的select方法,通过 CSS选择器 来查找 HTML 文档中所有符合条件的元素。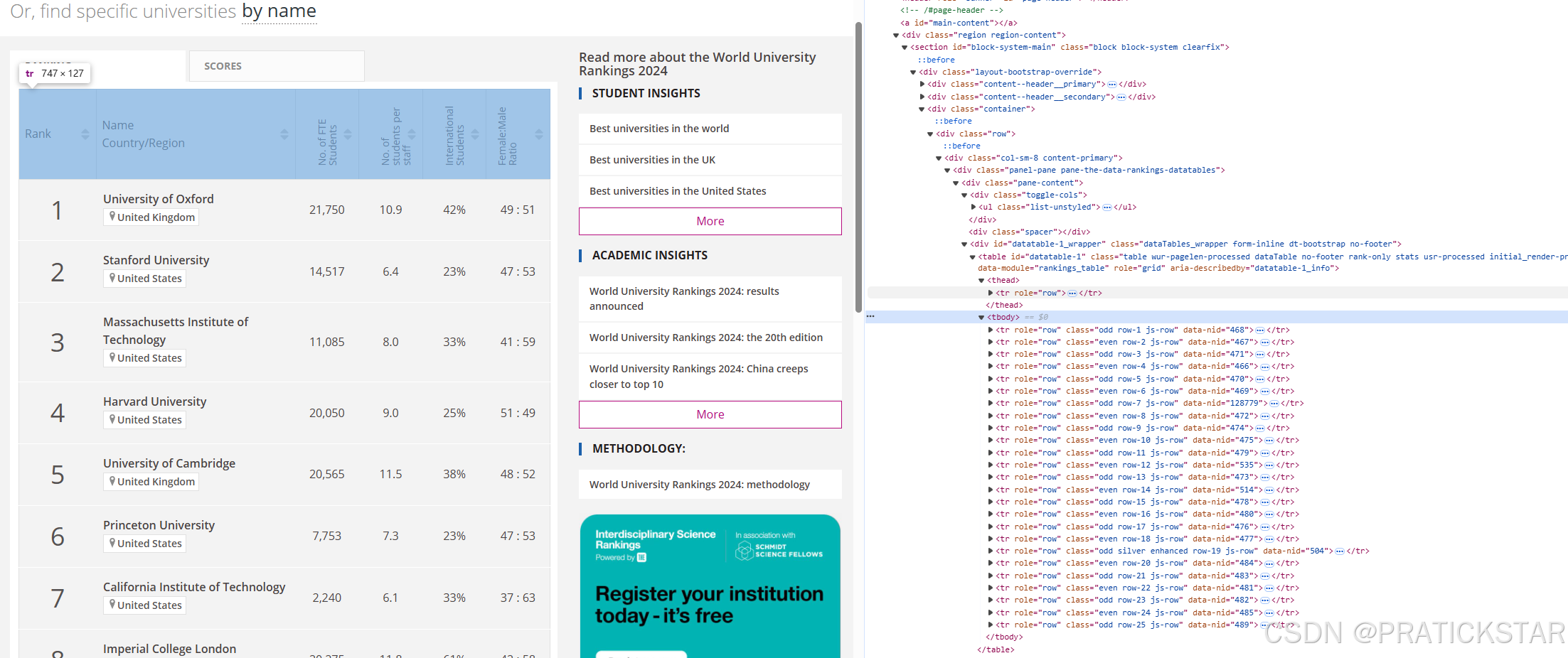
- 通过提取的一行数据之后访问每一行中的类名
-
rank = row.select_one(".rank").text.strip() name = row.select_one(".ranking-institution-title").text.strip() country = row.select_one(".location span a").text.strip() students = row.select_one(".stats_number_students").text.strip() ratio = row.select_one(".stats_student_staff_ratio").text.strip() intl_students = row.select_one(".stats_pc_intl_students").text.strip() female_male_ratio = row.select_one(".stats_female_male_ratio").text.strip() - 获取每一行的子类
- 然后是获取表格数据
-
# 获取页面 HTML 并解析 html = driver.page_source table_data = parse_table(html) -
 也就是图中的这个部分
也就是图中的这个部分
问题总结
首先是我看到这个网页的时候 网页是有方向箭头的按钮触发的,包括我自己也可以通过利用鼠标来进行触发,但是如果我通过,获取这个元素的类获取按钮的时候,运行代码始终触发不了按钮
网页是有方向箭头的按钮触发的,包括我自己也可以通过利用鼠标来进行触发,但是如果我通过,获取这个元素的类获取按钮的时候,运行代码始终触发不了按钮
 元素以及对应网页的地方。
元素以及对应网页的地方。
但是这个地方不像之前的关于排名的网站(这里是软科的排名的下一页按钮)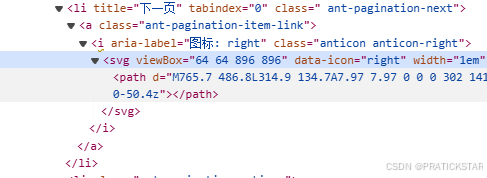

我爬取这个软件的排名的时候通过下面的代码去读取的,这个代码就可以获得
if page < total_pages:
next_button = driver.find_element(By.CSS_SELECTOR, "li.ant-pagination-next")
# 确认按钮未被禁用
if "ant-pagination-disabled" not in next_button.get_attribute("class"):
next_button.click()
time.sleep(2) # 等待新页面加载
else:
print("Next button is disabled.")
break相同的按钮触发方式泰晤士的就无法触发,但好在泰晤士的页面跳转可以通过路由控制

while True:
# 构造分页 URL
url = f"{base_url}?page={page}#page={page}"
print(f"正在抓取第 {page} 页: {url}")
# 打开目标页面
driver.get(url)
# 等待表格加载完成
wait = WebDriverWait(driver, 10)
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "tr.js-row")))
# 获取页面 HTML 并解析
html = driver.page_source
table_data = parse_table(html)
# 如果没有数据,说明到最后一页,退出循环
if not table_data:
print("没有更多数据,结束爬取!")
break
# 保存数据
with open(output_file, mode='a', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerows(table_data)
print(f"第 {page} 页已保存 {len(table_data)} 条数据")
# 下一页
page += 1通过这种路由加载的方式就可以读取后页面的数据
注意
我的代码有一些注意的事项,就是本代码读取的数据是从第二页开始的,是刚开始的设计没有优化,另一个问题是代码不会自动停止,当读完所有页面时,页面接着加载回到第一页,所以最后会反复第一页,后面手动停止,并手动截取第一页数据即可


















 9848
9848

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









