







灰色关联分析法:
对于两个系统之间的因素,其随时间或不同对象而变化的关联性大小的量度,称为关联度。在系统发展过程中,若两个因素变化的趋势具有一致性,即同步变化程度较高,即可谓二者关联程度较高;反之,则较低。因此,灰色关联分析方法,是根据因素之间发展趋势的相似或相异程度,亦即“灰色关联度”,作为衡量因素间关联程度的一种方法。
灰色关联分析,公式网上都有很多,计算也不难,这里就不写公式。
之所以称为关联,是因为他只反映哪一个指标和要对比的指标最有关系,而不反映相关性。
他和相关性系数,没有一毛钱关系,也不对等。最后得出来的系数,也只是做一个排序。
不反映相关性,不反映相关性,不反映相关性。
灰色关联分析,是根据因素之间发展趋势的相似或相异程度,即“灰色关联度”,作为衡量因素间关联程度的方法
特点:
- 不需要自变量,参考变量服从正态分布,对样本数据没有要求,适合小样本数据。
- 能够将自变量和参考变量的关联性大小排序,从而得到重要性排序的评价,本身的关联度没有实际意义,比如得出关联度为0.95,这个数字只用排序,并不能像相关性0.95一样得出他们高度正相关。
- 缺点在于只能排序,不能得出确切的相关性,不属于相关性分析范畴,只归入综合评价方法里。
步骤:
- 确定参考指标和比较指标,一般参考指标放最开始的位置。
- 确定归一化(其实这里说归一化不太正确,但很多地方都说归一化,其实应该是消除量纲)方法,常见的有:
| 初值法 | 增益型:每一个指标除以这个指标的第一个(初值)。成本型:第一个值除以每一个指标的每个值 |
|---|---|
| 均值法 | 增益型:每一个指标除以这个指标的均值。成本型:均值除以每一个指标的每个值 |
| 区间变换法 | 增益型:(指标减去最小值)除以(最大值减最小值) 。成本型:(最大值减去指标)除以(最大值减最小值) |
| … | … |
方法有很多,常见的就是初值和均值,增益型就是这个比较指标相对于参考指标越大越好,成本型就是越小越好,所以要把他们都转变成方向一致。
- 这时候的矩阵已经没有了量纲的影响,再用每个要比较的指标减去参考指标,一般参考放第一行,就都减去第一行的数据。这个地方要取绝对值,不能有负数,得到的矩阵一般记做Δ(k)
- 求两级最大差和最小差,即上面Δ(k)矩阵中的最大值,和最小值。记Δ(max),Δ(min)
- 得到关联系数矩阵:式子中的Δ(k)就是上面得到的绝对值后的矩阵
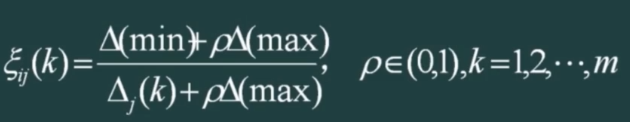
- 最后对每一个指标的向量求均值。就是最终的结果
下面是Python代码
# 最下面写了三个函数分别为gain,cost,level_,用于无量纲化,被GRA调用
def GRA(df,normaliza="initial",level=None,r=0.5):
'''
df : 二维数据,这里用dataframe,每一行是一个评价指标,要对比的参考指标放在第一行
normaliza :["initial","mean"] 归一化方法,默认为初值,提供初值化或者均值化,其他方法自行编写
level :为None默认增益型,
可取增益型"gain"(越大越好),成本型"cost"(越小越好),
或者dataframe中的某一列,如level="level","level"是列名,这列中用数字1和0表示增益和成本型
r : [0-1] 分辨系数
越大,分辨率越大; 越小,分辨率越小,一般取0.5
'''
# 判断类型
if not isinstance(df,pd.DataFrame):
df = pd.DataFrame(df)
# 判断参数输入
if (normaliza not in ["initial","mean"]) or (r<0 or r>1):
raise KeyError("参数输入类型错误")
# 增益型的无量纲化方法
if level == "gain" or level == None:
df_ = gain(df,normaliza 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









