







【0】README
1) 本文部分文字描述转自 core java volume 2 , 测试源代码均为原创, 旨在理解 java数据库编程——事务 的基础知识 ;
2)for database connection config, please visit : https://github.com/pacosonTang/core-java-volume/blob/master/coreJavaAdvanced/chapter4/database.properties
【1】事务相关
1)事务定义:将一组语句构建成一个事务;
- 1.1)当所有语句被顺利执行后, 事务可以提交;否则,如果其中某个语句遇到错误,那么事务将被回滚,就好像没有任何语句执行过一样;
- 1.2)将多个语句组合成事务的原因: 为了确保数据库完整性;(干货——将多个语句组合成事务的原因)
2)自动提交模式: 默认情况下, 数据库连接处于 自动提交模式, 每个 sql 语句一旦被执行便被提交给 数据库, 一旦命令被提交, 就无法对它进行 回滚操作;(干货——sql语句的执行(execute)与提交(commit)是两个概念)
- 2.1)在使用事务时, 需要关闭这个默认值;
conn.setAutoCommit(false); - 2.2)现在可以使用通常的方法创建一个语句对象:
Statement stat = conn.createStatement(); - 2.3)然后任意多次调用executeUpdate 方法:
stat.executeUpdate(comman1); - 2.4)如果执行了所有命令之后没有出错,则调用 commit 方法:
conn.commit(); - 2.5)如果出错,则调用
conn.rollback(); //回滚操作
【2】保存点
1)保存点作用: 创建一个保存点意味着稍后只需要返回这个点,而非事务的开头; (干货——保存点作用)
2)看个荔枝:
Statement stat = conn.createStatement();//创建语句
stat.executeUpdate(command1);
Savepoint point = conn.setSavepoint();//创建保存点
stat.executeUpdate(command1);
if(…)
conn.rollback(point); //回滚操作
…
conn.commit();
- 2.1)当不再需要保存点 的时候, 必须释放它; (干货——释放保存点)
conn.releaseSavepoint(point);
【3】批量更新
1)批量更新的作用: 一个程序需要执行多条insert 语句, 可以使用批量更新方法来提高程序性能; (干货——批量更新的作用: 一个程序需要执行多条insert 语句)
Attention)
- A1)使用 DatabaseMetaData 接口中的 supportsBatchUpdates 方法可以获知数据库是否支持这种特性;
- A2)处于同一批的语句可以是, insert, update, delete等 DML操作, 也可以是数据库定义语句, 如create, drop 等DDL;
- A3) 但是, 在批量处理中添加 select 语句会抛出异常(从概念上讲, 批量处理中的 select 语句没有意义, 因为它会返回结果集, 而并不更新数据库) (干货——在批量处理中添加 select 语句会抛出异常)
2)使用批量更新的步骤:
- step1)创建一个 Statement对象:
Statement stat = conn.createStatement(); - step2) 应该调用 addBatch 方法, 而不是 executeUpdate 方法:
String command = “create table …. “;
stat.addBatch(command); step3)循环提交 insert 语句:
while(…)
{
command = “insert into …”;
stat.addBatch(command);
}step4)最后 , 提交整个批量更新语句;
int[] counts = stat.executeBatch();
Attention)
- A1)调用executeBatch 方法将为所有已提交的语句返回一个 记录数的数目;
- A2)为了在批量模式下正确地处理错误, 必须将批量执行的操作视为单个事务。 如果批量更新在执行过程中失败, 那么必须将它回滚到批量操作开始之前的状态;
A3)首先关闭自动提交模式, 然后收集批量操作, 执行并提交该操作, 最后恢复最初 的自动提交模式:
step1)关闭自动提交模式:
boolean autoCommit = conn.getAutoCommit();
conn.setAutoCommit(false);
Statement stat = conn.getStatement();
…step2)然后收集批量操作:
// keep calling stat.addBatch();- step3)执行并提交该操作;
stat.executeBatch();
stat.commit(); - step4)最后恢复最初 的自动提交模式;
conn.setAutoCommit(autoCommit);
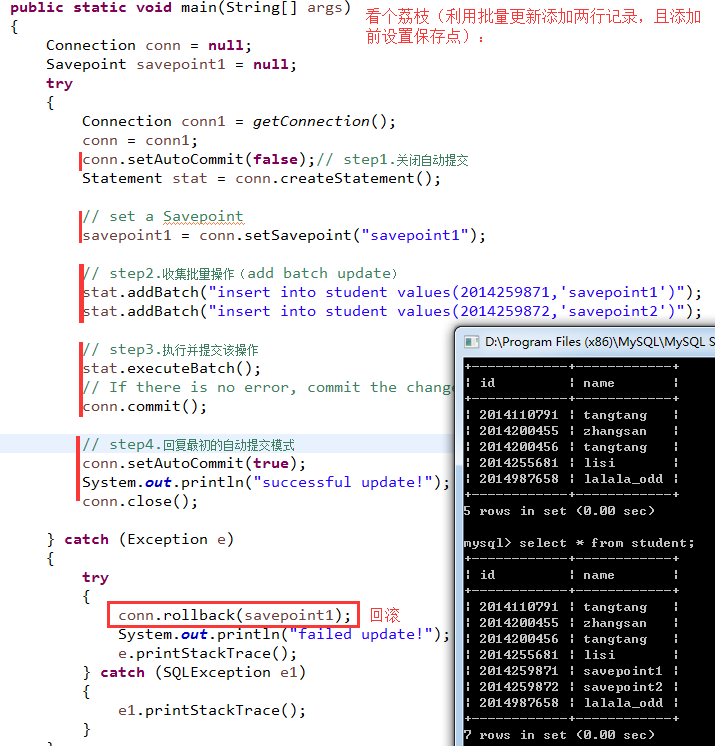
3)看个荔枝(利用批量更新添加两行记录,且添加前设置保存点):
- 3.1)for souce code, please visit : https://github.com/pacosonTang/core-java-volume/blob/master/coreJavaAdvanced/chapter4/SavePointsTest.java
- 3.2)key source code at a glance:
public static void main(String[] args)
{
Connection conn = null;
Savepoint savepoint1 = null;
try
{
Connection conn1 = getConnection();
conn = conn1;
conn.setAutoCommit(false);// step1.关闭自动提交
Statement stat = conn.createStatement();
// set a Savepoint
savepoint1 = conn.setSavepoint("savepoint1");
// step2.收集批量操作(add batch update)
stat.addBatch("insert into student values(1,'savepoint1')");
stat.addBatch("insert into student values(1,'savepoint2')");
// step3.执行并提交该操作
stat.executeBatch();
// If there is no error, commit the changes.
conn.commit();
// step4.回复最初的自动提交模式
conn.setAutoCommit(true);
System.out.println("successful update!");
conn.releaseSavepoint(savepoint1); //当不再需要保存点 的时候, 必须释放它
conn.close();//关闭数据库连接
} catch (Exception e)
{
try
{
conn.rollback(savepoint1);//回滚
System.out.println("failed update!");
e.printStackTrace();
} catch (SQLException e1)
{
e1.printStackTrace();
}
}
}- 3.3)relative printing results as follows:
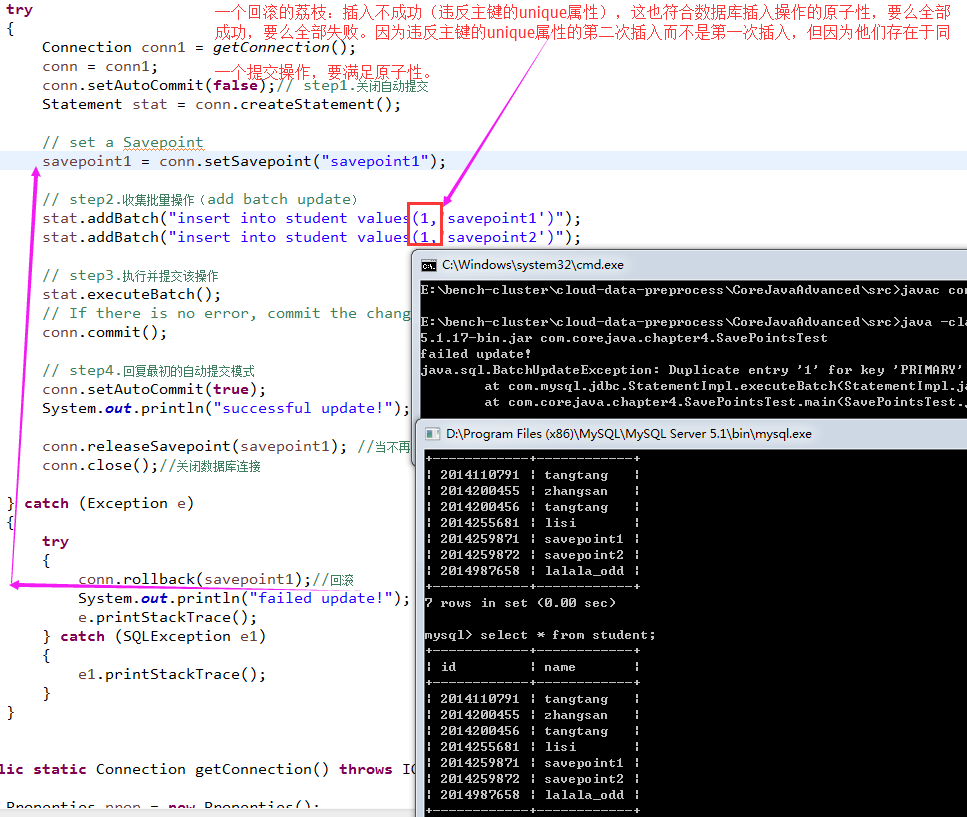
4)看个荔枝(一个回滚的荔枝):
- 4.1)for souce code, please visit : 同上;
- 4.2)key source code at a glance: 同上;
- 4.3)relative printing results as follows:
【4】高级SQL类型
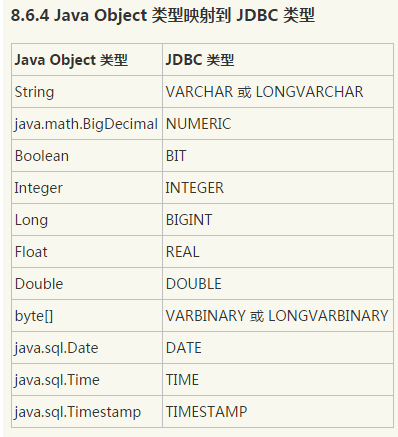
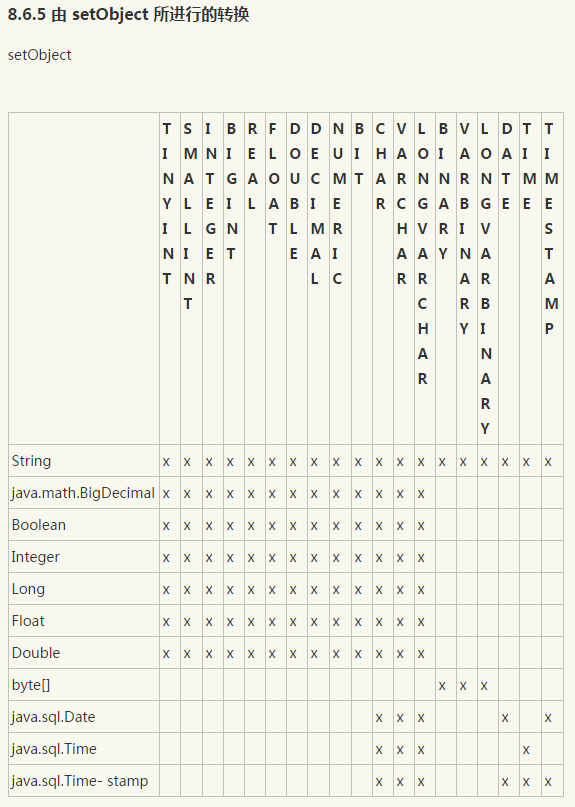
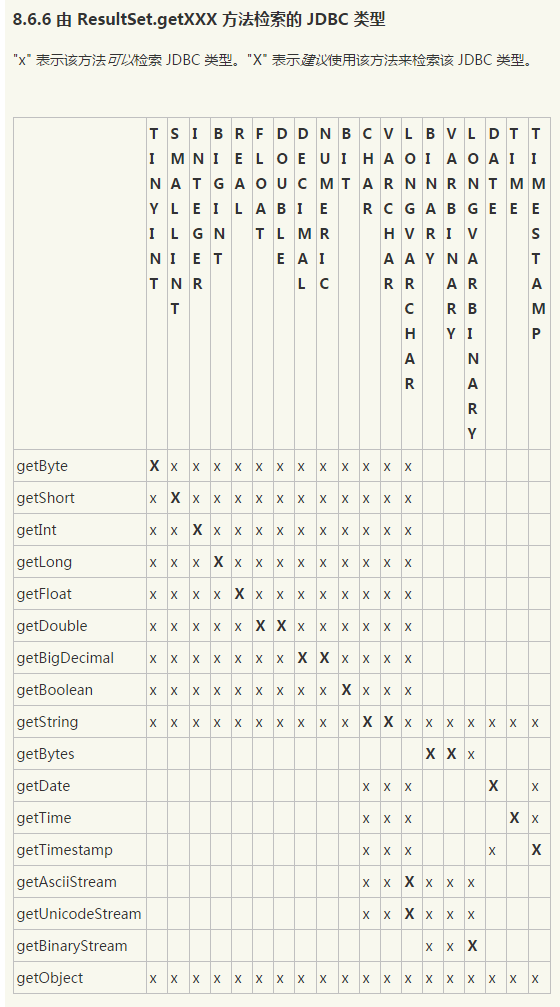
1) sql 数据类型及其对应的java类型(图片地址:http://www.cnblogs.com/shishm/archive/2012/01/30/2332142.html)
 |  |
 |  |
 |  |
2)SQL ARRAY(SQL 数组)指的是值的序列;
- 2.1)如, Student 表中通常都会有一个 Scores 列, 这个列就应该是 ARRAY OF INTEGER(整数数组);
- 2.2)getArray方法: 返回一个接口类型为 java.sql.Array 的对象,该接口中有许多方法可以用于获取数组的值;
3)从数据库中获得一个 LOB 或数组并不等于获取了它的实际内容, 只有在访问具体值的时候, 它们才会从 数据库中被读取出来;
4)ROWID值: 某些数据库支持描述行位置的 ROWID值, 这样就可以非常快捷地获取某一行值;
- 4.1)JDBC 4 引入了 java.sql.RowId 接口: 并提供了用于在查询中提供 行 ID, 以及从结果中获取该值的方法;
5)国家属性字符串(NCHAR及其变体): 按照本地字符编码机制存储字符串,并使用本地排序惯例对这些字符串进行排序;
- 5.1) JDBC 4 提供了这种方法, 用于在查询和结果中进行 java 的 string 对象和国家属性字符串之间的双向转换;
6)有些数据库提供了用于XML 数据的本地存储。
- 6.1)JDBC 4 引入了 SQLXML接口: 它可以在内部的 XML 表示和 DOM 的 Source/Result 接口或二进制流之间起到中间作用。















 6506
6506

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









