









1.算法通关村第一关——链表青铜挑战笔记
前置知识:
Java的内存中有堆和栈的概念,其中堆是对象真正创建出来的地方,每个对象自出生开始就被分配了一把唯一的"金汤匙"(内存地址),而栈中保存的其实不是对象本身,是对象的这把"金汤匙",在程序执行的时候,栈内存是拿着这把金汤匙去找到真正的对标的对象进行操作的。(如果各位没听懂,建议恶补一下JavaSE。。。)
1.链表的概念
话不多说,先上图:
通过上图可以发现整个结构就像一条链子一样,上图中相似的部分是由一个矩形与一个圆圈共同构成的,这个部分我们把它叫做“节点”或者“结点”,我们发现出了一个单独的节点由两部分组成:存储数据的部分 + 存储下一个节点地址的部分:

此时就需要表头了;
==============================================
2.使用Java如何构建一个链表?
2.1定义一个节点
基于前面所说的,我们知道链表最基本的单元是由**节点 **组成的,那我们先构建一个节点的类:
/**
* 用"面相对象"的思想来定义链表的节点,这里的节点是单向列表的节点
* @author BrucePang
*/
public class Node {
private int val; // 节点的值
private Node next; // 下一个节点的引用
public int getVal() {
return val;
}
public void setVal(int val) {
this.val = val;
}
public Node getNext() {
return next;
}
public void setNext(Node next) {
this.next = next;
}
}
我们发现属性私有化了,提供访问以及操作这些都是使用的setter与getter;燃鹅我相信有N多小伙伴可能已经看过下面一种构造节点的类:
/**
* 在算法中最常用的链表定义方式
*
* @author BrucePang
*/
public class ListNode {
public int val;
public ListNode next;
// 为什么使用有参构造器给属性赋值,并且属性是public的?
// 如果是在开发一个项目的话,那么这样的写法是不合理的,因为属性是public的,会导致属性被随意修改,不符合面向对象的封装特性
// 但是在算法中,我们只关注算法的实现,不关注属性的封装,所以这样的写法是合理的,并且也减少了代码的行数,增加了代码的可读性
public ListNode(int x) {
val = x;
next = null;
}
}
对比好处么,我上面代码已经注释了,不再赘述~~~
2.2创建链表
这里为了演示一下创建的算法的一个迭代过程,我对类名做了标记,代码中有详尽的注释:
/**
* 一个简单的链表实例,用于演示JVM怎么构造链表的
* BrucePang
*/
public class BasicLink0 {
public static void main(String[] args) {
int[] arr = {1,2,3,4,5,6};
// 创建链表
Node node = creatLinkedList(arr);
System.out.println(node);
}
/**
* 通过数组创建链表
* @param arr 被传入的数组元素
* @return
*/
private static Node creatLinkedList(int[] arr) {
// 创建表头
Node head = null; // 由于链表是由头节点查找下一个节点的,所以这里单独定义一个头节点,以保证每次都能使用到头节点
// 如果按照正序去构造节点,当前节点可能不知道下一个节点是null还是节点,所以这里使用倒序的方式去构造节点:
// 先构造最后一个节点,然后再构造倒数第二个节点,以此类推
// 此处是为了演示原理,所以先用硬编码,因为开发人员知道构造了一个多长的数组
Node node5 = new Node(arr[5]);
Node node4 = new Node(arr[4]);
Node node3 = new Node(arr[3]);
Node node2 = new Node(arr[2]);
Node node1 = new Node(arr[1]);
Node node0 = new Node(arr[0]);
// 构造节点之间的关系
head = node0;
node0.next = node1;
node1.next = node2;
node2.next = node3;
node3.next = node4;
node4.next = node5;
node5.next = null; // 最后一个节点的下一个节点是null
return head; // 返回头节点,debug时可以通过头节点去查看整个链表的结构
}
static class Node{ // 链表的节点:由于重点是学习算法,所以这里不考虑使用面向对象的getter与setter,直接用有参构造器完成每个节点的初始化,简化代码,使用对象.属性的方式直接赋值
int val; // 节点的值
Node next; // 下一个节点的引用
public Node(int val){
this.val = val;
next = null;
}
}
}
上面我们可以看到我是直接硬编码写的链表的构建过程,显然这玩意儿没什么含金量,我们先来debug看看整个链表是否被构建成功:
下图是debug后整个链表的结构: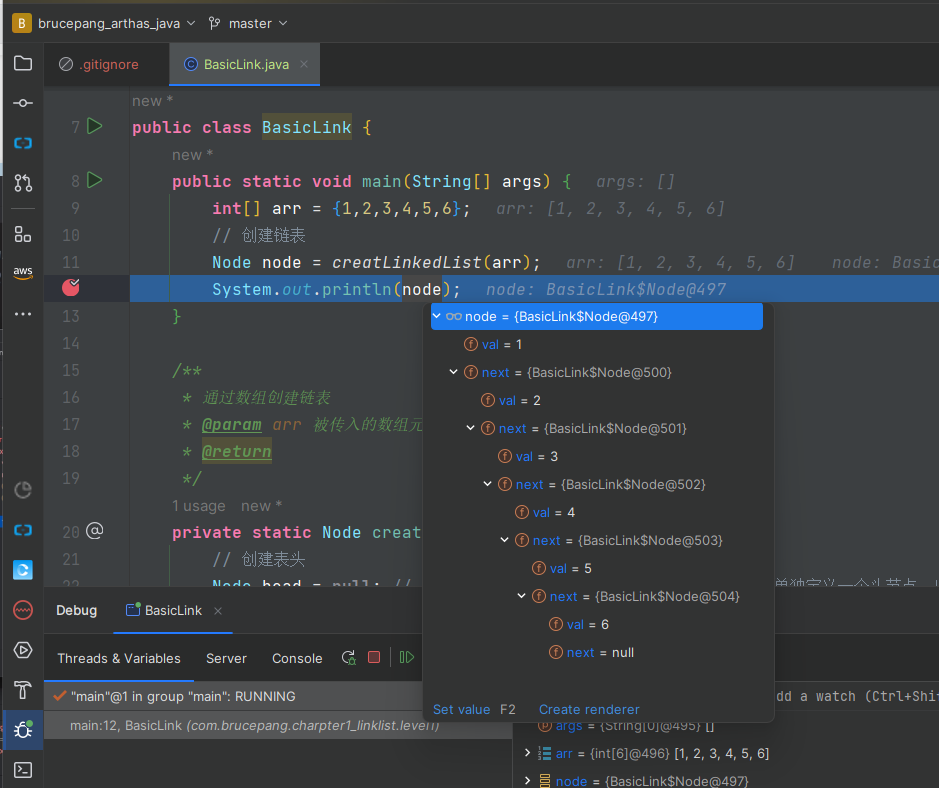
硬编码的方式我们可以发现好理解,既然我们已经实现了单向的链表,那么双向的链表,是不是可以如法炮制呢?
双向链表的核心点是什么?
是不是一个节点既可以从当前往后找,又可以从当前节点往前找?
如图:
Node1存放了Node2的内存地址;
Node2存放了Node1的内存地址,Node3的内存地址;
Node3存放了Node2的内存地址;
以Node2为观察对象,我们把Node1叫做Node2的前驱节点,Node3叫做Node2的后置节点;
注意:习惯上我们还是以头节点作为链表的起始点
我们来看看如何在BasicLink0的基础上实现双向列表结构:
/**
* 一个简单的链表实例,基于BasicLink0的基础上,构建双向链表
* BrucePang
*/
public class BasicLink1 {
public static void main(String[] args) {
int[] arr = {1,2,3,4,5,6};
// 创建链表
Node node = creatLinkedList(arr);
System.out.println(node);
}
/**
* 通过数组创建链表
* @param arr 被传入的数组元素
* @return
*/
private static Node creatLinkedList(int[] arr) {
// 创建表头
Node head = null; // 由于链表是由头节点查找下一个节点的,所以这里单独定义一个头节点,以保证每次都能使用到头节点
// 如果按照正序去构造节点,当前节点可能不知道下一个节点是null还是节点,所以这里使用倒序的方式去构造节点:
// 先构造最后一个节点,然后再构造倒数第二个节点,以此类推
// 此处是为了演示原理,所以先用硬编码,因为开发人员知道构造了一个多长的数组
Node node5 = new Node(arr[5]);
Node node4 = new Node(arr[4]);
Node node3 = new Node(arr[3]);
Node node2 = new Node(arr[2]);
Node node1 = new Node(arr[1]);
Node node0 = new Node(arr[0]);
// 构造节点之间的关系
head = node0;
node0.pre = null; // 头节点的上一个节点是null
node0.next = node1;
node1.next = node2;
node2.next = node3;
node3.next = node4;
node4.next = node5;
node5.next = null; // 最后一个节点的下一个节点是null
// 构造所有节点的前驱节点
node0.pre = null;
node1.pre = node0;
node2.pre = node1;
node3.pre = node2;
node4.pre = node3;
node5.pre = node4;
return head; // 返回头节点,debug时可以通过头节点去查看整个链表的结构
}
static class Node{ // 链表的节点:由于重点是学习算法,所以这里不考虑使用面向对象的getter与setter,直接用有参构造器完成每个节点的初始化,简化代码,使用对象.属性的方式直接赋值
int val; // 节点的值
Node next; // 下一个节点的引用
Node pre; // 上一个节点的引用
public Node(int val){
this.val = val;
next = null;
pre = null;
}
}
}
现在最最最最基本的单向链表与双向链表Java实现代码我已经罗列出来了,并且配上了相应的注释;这种写法看着特别清晰,但是如果我传递的数组如果有1W个元素呢,难道每个元素我都要为它手动多写3行代码么?那岂不是要写3W+遍???
所以,我们再将BasicLink1的代码优化一下,改成循环替我们实现,
/**
* 一个简单的链表实例,用于演示JVM怎么构造链表的(基于BasicLink1,将单链表更新为双向链表)
* BrucePang
*/
public class BasicLink2 {
public static void main(String[] args) {
int[] arr = {1,2,3,4,5,6};
// 创建链表
Node node = creatLinkedList(arr);
System.out.println(node);
}
/**
* 通过数组创建链表
* @param arr 被传入的数组元素
* @return
*/
private static Node creatLinkedList(int[] arr) {
// 创建表头
Node head = null; // 由于链表是由头节点查找下一个节点的,所以这里单独定义一个头节点,以保证每次都能使用到头节点
Node cur = null; // 当前节点
for (int i = 0; i < arr.length; i++) { // 每次cur.next能够指向新的节点,发生的时机实际上是下一次for循环,若没有下一次for循环,则cur.next指向null
if (i == 0) { // 第一次循环时,创建头节点
cur = new Node(arr[i]);
head = cur; // 头节点赋值,有且只赋值一次
} else {
Node pre = cur; // 上一轮节点的引用保存到临时变量中
cur.next = new Node(arr[i]); // 此处引用还是上一轮的节点: 新一轮的for循环开始时,首先将上一轮的Node节点的next指向新的Node节点
cur = cur.next; // 然后将cur节点引用更新为当前for循环的Node节点
cur.pre = pre; // 将上一轮节点的引用赋值给当前节点的pre属性
}
}
return head; // 返回头节点,debug时可以通过头节点去查看整个链表的结构
}
static class Node{ // 链表的节点:由于重点是学习算法,所以这里不考虑使用面向对象的getter与setter,直接用有参构造器完成每个节点的初始化,简化代码,使用对象.属性的方式直接赋值
int val; // 节点的值
Node next; // 下一个节点的引用
Node pre; // 上一个节点的引用
public Node(int val){
this.val = val;
next = null; // 为了方便理解最后一个节点的next指向null,所以这里初始化为null
pre = null; // 为了方便理解最后一个节点的pre指向null,所以这里初始化为null
}
}
}
3-单向链表的增删改查
3.1 获取链表长度
在增删改查之前,我们再来温习一下链表的组成,以单链表为切入口:
单链表的组成: 表头 + 若干节点 + null
如果我们要增加一个节点,可以在表头部,或者链表中间,或者链表尾部,单链表的话,我们都是从表头开始查找,
- 如果想在第一个节点的位置插入节点,表头的next指向的就是下一个节点;
- 如果想在链表中间去插入一个节点,由于单向链表只能由上一个节点找向下一个节点查找,并且我们还不能让原有位置的节点丢失掉,为了方便操作,我们最好通过头节点,找到要插入位置的上一个节点(因为上一个节点的next一定指向的是我们要插入的那个位置的节点);
- 如果想在末尾插入的话,同理,也是找到末尾节点的上一个节点,然后去操作;
通过上面的分析,我们可以发现:
- 单链表都是通过表头去查找;
- 要插入节点的位置与链表查询长度也有关系; 抽象成一个公式的话,就是: **要修改的节点= 表头 + n * 节点 **
注意: 为了灵活操作,保证单向链表插入新元素时, 上个节点与下个节点的数据信息不丢失,我们一般找到的是要操作节点的上一个节点,于是公式微调一下:
要修改的节点 = 要修改的上一个节点 + 1
= 表头 + m * 节点 + 1
那这就涉及到链表的一个查找了,链表的查找的需要通过表头去查,如果是在末尾插入节点,那就需要找到前面所有的节点,就要遍历链表,操作的灵活也与链表的长度有关;
代码如下:
/**
* 获取链表长度
* @param head 链表头节点
* @return
*/
private static int getLinkedLength(Node head) {
int length = 0;
Node node = head;
while (node != null) { //
// 如果head的next属性为null,则表示当前节点是最后一个节点
length++;
node = node.next;
}
return length;
}
3.2链表的插入
基于3.1小节的分析,我们知道了插入链表无非有三种情况: 头部插入,中间插入,尾部插入。
(1) 在链表的表头插入
首先我们知道,插入的节点有两点不能丢:
1.插入此位置后,原来此位置的节点及其以后的节点不能丢;
2.插入此位置后,原来此位置之前的节点不能丢。
那么问题来了,假设有一个新的节点newNode要插入到表头的位置,怎么链接到原来的链表上呢?
参看下图的过程:
我们可以发现步骤经历了:
1.创建新节点; ==> Node newNode = new Node(任意数);
2.将新节点的next指向head指向的节点 (由于head变量中已经保存了原来节点的引用,所以直接将head赋值给newNode.next,本质上就是将第一个节点的内存地址赋值给newNode.next); ==> newNode.next = head;
3.head引用指向了新的节点; ==> head = newNode;
那么我们根据以上步骤,总结一下,在链表表头插入的核心代码:
Node head = 0x001; // 这里假设head指向的节点的内存地址为0x001;
var position = 1; // position = 1 表示要插入的节点的位置是head指向的节点
Node newNode = new Node(1);// 创建一个新的节点,节点中传入的参数是节点的值,不是任何节点的内存地址
if(position == 1 ){ // 要插入的位置是链表的头节点位置
newNode.next = head;
head = newNode;
return head;
}
(2)在链表中间插入
刚才我们分析过了从表头插入,现在我们要从非头部与非尾部节点插入,又要怎么操作呢?(这里就不将next部分给画出来了,默认大家已经熟知Node的结构)
请看下图:
通过上图我们可以清晰的发现newNode插入到Node节点值为32位置处的全过程!
概括为:
newNode.next = node32;
node12.next = newNode;
那图中是基本的一个思路,我们再来代码实现一下:
// 2. 链表中间插入
Node head = 0x001; // 这里假设head指向的节点的内存地址为0x001;
var position = 3; // position = 3 表示要插入的节点的位置是head指向以后的第3个节点
Node newNode = new Node(1);// 创建一个新的节点,节点中传入的参数是节点的值,不是任何节点的内存地址
if (position > 1 && position <= getLinkedLength(head)) {
// 这里出现了一个难点: 如果要找到要处理位置的节点,是不是必须找到要处理位置的上一个节点,要找到要处理位置的上一个节点,就得找到上上个节点,最后你发现得从头节点开始找...
Node node = head;
int count = 1;
while (count != position) { // 遍历链表,找到第position位置的节点,count是递增的,你会发现当 count == postion时, postion位置的节点并没有被取来赋值给node变量,while循环停到了要更改位置的上一个节点!
node = node.next; // 要被处理的节点
count++;
}
// 于是,我们通过"要更改节点的上一个节点的next找到<要更改的节点>的引用",完成图中的赋值
newNode.next = node.next; // 将newNode节点的next属性赋值为node节点的next属性,表示newNode节点的下一个节点是node节点的下一个节点
node.next = newNode; // 将newNode节点赋值给node节点的next属性,表示node节点的下一个节点是newNode节点
return head;
}
注意:
1.仔细看上面的代码哦,写代码的时候,与图上叙述的过程,有稍微一丁点的出入!
**2.特别注意插入的原则: 链表新节点的插入,不能将原有的节点给丢弃,所以写代码的时候,顺序特别重要: **
先将后节点引用交给新节点的next,
新节点的本身的引用,交给上一个节点的next,
二者顺序不可颠倒,若发生颠倒,则会丢失原来位置节点及其后面节点的所有引用!
所以, 引用赋值的顺序特别重要!!!
于是这里我总结了一句 真言: "发生改变,(新节点)先保后,新(节点)(引用)存前(一个节点)
简单点就是: 先保后,新存前
(3)在单链表的结尾插入结点
表尾插入就比较容易了,我们只要将尾结点指向新结点就行了。
综上 ,我们写出链表插入的方法如下所示:
/**
* 链表插入
* @param head 链表头节点
* @param newNode 待插入节点
* @param position 待插入位置,从1开始
* @return 插入后得到的链表头节点
*/
public static Node insertNode(Node head, Node newNode, int position) {
if (head == null) { // 如果头节点为空,则直接将newNode节点赋值给head,表示newNode节点是新的头节点
head = newNode;
return head;
}
// 已经存放的元素个数
int size = getLinkedLength(head);
// 判断待插入位置是否越界
if (position < 1 || position > size + 1) {
System.out.println("插入位置越界");
return head;
}
// 1. 链表头部插入
if (position == 1) {
newNode.next = head; // head指向的是第一个节点位置的引用,所以这里将head赋值给newNode的next属性,表示newNode节点的下一个节点是原来head指向的节点
head = newNode; // 将newNode赋值给head,表示newNode节点是新的头节点
return head;
}
// 2. 链表中间插入
if (position > 1 && position <= size) {
Node node = head;
int count = 1;
while (count != position) { // 遍历链表,找到第position位置的节点,count是递增的,你会发现当 count == postion时, postion位置的节点并没有被取来赋值给node变量,while循环停到了要更改位置的上一个节点!
node = node.next;
count++;
}
newNode.next = node.next; // 将newNode节点的next属性赋值为node节点的next属性,表示newNode节点的下一个节点是node节点的下一个节点
node.next = newNode; // 将newNode节点赋值给node节点的next属性,表示node节点的下一个节点是newNode节点
return head;
}
// 3. 链表尾部插入
if (position == size + 1) {
Node node = head;
while (node.next != null) { // 遍历链表,找到最后一个节点的上一个节点
node = node.next;
}
node.next = newNode; // 将newNode节点赋值给最后一个节点的next属性,表示newNode节点是最后一个节点的下一个节点
return head;
}
return head;
}
(4)优化插入的代码
上面的代码我们可以发现确实是实现了单向链表的任意节点的位置新增,但是,我们其实是可以发现可以优化这些代码的!
比如:
链表中间插入与链表尾部插入,在while的时候,我们发现,都只能停在"要处理节点的上一个节点",那么我们能否将"在链表尾部插入"的逻辑写到"链表中间插入"逻辑中呢?
经过一番思索,我做出了如下优化,并配上了想应的注释:
/**
* 链表插入
* @param head 链表头节点
* @param newNode 待插入节点
* @param position 待插入位置,从1开始
* @return 插入后得到的链表头节点
*/
public static Node insertNode(Node head, Node newNode, int position) {
if (head == null) { // 如果头节点为空,则直接将newNode节点赋值给head,表示newNode节点是新的头节点
head = newNode;
return head;
}
// 已经存放的元素个数
int size = getLinkedLength(head);
// 判断待插入位置是否越界
if (position < 1 || position > size + 1) {
System.out.println("插入位置越界");
return head;
}
// 1. 链表头部插入
if (position == 1) {
newNode.next = head; // head指向的是第一个节点位置的引用,所以这里将head赋值给newNode的next属性,表示newNode节点的下一个节点是原来head指向的节点
head = newNode; // 将newNode赋值给head,表示newNode节点是新的头节点
return head;
}
Node pNode = head;
int count = 1;
//这里position被上面的size被限制住了,不用考虑pNode=null
while (count < position - 1) { // 找到要插入现在位置的前一个节点,方便操作
pNode = pNode.next;
count++;
}
newNode.next = pNode.next; // pNode.next上一个节点的next属性的值,实际上就是要插入该位置之前的老节点的引用,将老引用赋值给新节点的next,代表原来的位置已经被新节点替代了
pNode.next = newNode; // 将老节点的next属性赋值为新节点的引用,表示老节点的下一个节点是新节点
return head;
}
3.3 链表删除
删除同样分为在删除头部元素,删除中间元素和删除尾部元素。
(1)删除表头结点
话不多数,先上图:
从上图,我可以发现head变为new head的过程,
即:将原来head指向的引用,变为下一个节点就行;
在经历了新增的操作后,我们发现,很多操作都是操作的"要改变位置的节点的上一个节点",这里删除也不例外,我们知道:
head指向的就是第一个节点,head持有第一个节点的引用,
那么head.next就是第二个节点,
现在我们要删除第一个节点,是不是只需要将head指向第二个节点即可.第二个节点是head.next;
即: head = head.next;
那么被丢掉老表头去哪儿了呢?由于未被引用,最终老表头被JVM先森给当做垃圾回收掉了!
(2)删除最后一个结点
先看图:
删除最后一个节点,无非是将倒数第二个节点的next指向null,让原来最后一个节点从链表上脱离出来;
结合上图,我们发现倒数第二个节点叫做cur,cur.next指向的是存值40的节点,现在我们只需要将cur.next = null即可做到删除链表尾部的节点,被删除的节点自然最后也被JVM作为垃圾回收掉啦~~~
至于怎么找到的到处第二个节点,可以看我3.2代码的实现;
(3)删除中间节点
删除中间结点时,也会要用cur.next来比较,找到位置后,将cur.next引用的值更新为cur.next.next就可以解决,如下图所示:

代码实现:
/**
* 删除节点
* @param head 链表头节点
* @param position 删除节点位置,取值从1开始
* @return 删除后的链表头节点
*/
public static Node deleteNode(Node head, int position) {
if (head == null) { // 如果头节点为空,则直接返回head
return head;
}
// 已经存放的元素个数
int size = getLinkedLength(head);
// 判断待删除位置是否越界
if (position < 1 || position > size) {
System.out.println("删除位置越界");
return head;
}
// 1. 删除头节点
if (position == 1) {
head = head.next;
return head;
}
// 2. 删除尾节点
if (position == size){
Node cur = head;
int count = 1;
while (count != position - 1){ // 永远只能找到要修改位置的上一个节点便停止了循环
cur = cur.next;
count++;
}
cur.next = null; // 倒数第二个节点的next属性赋值为null,表示倒数第二个节点是最后一个节点
return head;
}
// 3. 删除中间节点
if (position > 1 && position < size){
// 找到要删除的节点的上一个节点
Node cur = head;
int count = 1;
while (count != position - 1){ // 找到要删除位置的上一个位置的节点, 注意:这里为什么是position - 1 , 如果是postion, 此时while循环会继续执行,直接将postion上一个节点的next赋值给cur,那么此时cur已经是尾节点了,cur.next就是null,那么cur.next.pre就会报空指针异常
cur = cur.next;
count++;
}
cur.next = cur.next.next; // 将要删除节点的上一个节点的next属性赋值为要删除节点的下一个节点的引用,表示要删除节点的上一个节点的下一个节点是要删除节点的下一个节点
return head;
}
return head;
}
优化实现的代码:
/**
* 删除节点
* @param head 链表头节点
* @param position 删除节点位置,取值从1开始
* @return 删除后的链表头节点
*/
public static Node deleteNode(Node head, int position) {
if (head == null) { // 如果头节点为空,则直接返回head
return head;
}
// 已经存放的元素个数
int size = getLinkedLength(head);
// 判断待删除位置是否越界
if (position < 1 || position > size) {
System.out.println("删除位置越界");
return head;
}
// 1. 删除头节点
if (position == 1) {
head = head.next;
return head;
}
else { // 2. 删除尾节点或者中间节点
Node cur = head;
int count = 1;
while (count != position - 1){ // 找到要删除位置的上一个位置的节点, 注意:这里为什么是position - 1 , 如果是postion, 此时while循环会继续执行,直接将postion上一个节点的next赋值给cur,那么此时cur已经是尾节点了,cur.next就是null,那么cur.next.pre就会报空指针异常
cur = cur.next;
count++;
}
Node temp = cur.next; // 保存要删除的节点
cur.next = temp == null ? null : temp.next; // 将要删除节点的下一个节点的引用赋值给要删除节点的上一个节点的next属性,表示要删除节点的上一个节点的下一个节点是要删除节点的下一个节点(如果是链表尾部也不用担心,因为这里使用三目运算)
return head;
}
}
4-双向链表的增删改查
4.1 获取链表长度
不管是双向链表,还是单向链表,链表获取长度的方式都可以使用同一套,丝毫不受影响,单向链表与双向链表的区别:
无非是Node节点多维护了一个前驱节点的属性pre,我们来看一下双向链表的Node类:
public class Node {
public int val; // 存节点的值
public Node next; // 存后置节点的引用
public Node pre; // 存前驱节点的引用
public Node(int val) {
this.val = val;
this.next = null;
this.pre = null;
}
}
双向链表在Node中新增了 pre属性,但是这并不影响到整个链表的长度,此处复用3.1的实现代码;
4.2链表的插入
双向链表插入节点无非也只有三种情况: 头部插入,中间插入,尾部插入。
(1) 在链表的表头插入
首先我们知道,插入的节点有两点不能丢:
1.插入此位置后,原来此位置的节点及其以后的节点不能丢;
2.插入此位置后,原来此位置之前的节点不能丢。
那么问题来了,假设有一个新的节点newNode要插入到表头的位置,怎么链接到原来的链表上呢?
参看下图的过程:

我们可以发现步骤经历了:
1.创建新节点; ==> Node newNode = new Node(任意数);
2.将新节点的next指向head指向的节点 (由于head变量中已经保存了原来节点的引用,所以直接将head赋值给newNode.next,本质上就是将第一个节点的内存地址赋值给newNode.next); > newNode.next = head;
3.将老头节点的pre指向newNode; (代码应该怎么写呢?这里为了方便理解,现将老头结点的引用保存,然后再操作老头结点的pre)> Node oldHead = head; oldHead.pre = newNode;
4.head引用指向了新的节点; ==> head = newNode;
那么我们根据以上步骤,总结一下,在链表表头插入的核心代码:
Node head = 0x001; // 这里假设head指向的节点的内存地址为0x001;
var position = 1; // position = 1 表示要插入的节点的位置是head指向的节点
Node newNode = new Node(1);// 创建一个新的节点,节点中传入的参数是节点的值,不是任何节点的内存地址
if(position == 1 ){ // 要插入的位置是链表的头节点位置
Node oldHead = head; // 保存原来的节点
newNode.next = oldHead; // pre是上一个节点的引用,将pre赋值给newNode的next属性,表示newNode的下一个节点是pre[原来的头节点]
oldHead.pre = newNode; // 将原来的节点的pre属性赋值为新节点的引用,表示原来的节点的上一个节点是新节点
head = newNode; // 将newNode赋值给head,表示newNode节点是新的头节点
return head;
}
(2)在链表中间插入
废话不多说,请先看下图:
通过上图我们可以清晰的发现newNode插入到Node节点值为32位置处的全过程!
概括为:
newNode.next = node32; // 新节点的next指向node32
node12.next = newNode; // 老节点的上一个节点指向新节点
node32.pre = newNode; // 老节点的pre指向新节点
newNode.pre = node12; // 新节点pre指向老节点的上个节点
那根据基本思路我们再来代码实现一下:
// 2. 链表中间插入
Node head = 0x001; // 这里假设head指向的节点的内存地址为0x001;
var position = 3; // position = 3 表示要插入的节点的位置是head指向以后的第3个节点
Node newNode = new Node(11);// 创建一个新的节点,节点中传入的参数是节点的值,不是任何节点的内存地址
if (position > 1 && position <= getLinkedLength(head)) {
// 这里出现了一个难点: 如果要找到要处理位置的节点,是不是必须找到要处理位置的上一个节点,要找到要处理位置的上一个节点,就得找到上上个节点,最后你发现得从头节点开始找...
Node pNode = head;
int count = 1;
while (count != position) { // 遍历链表,找到第position位置的节点,count是递增的,你会发现当 count == postion时, postion位置的节点并没有被取来赋值给node变量,while循环停到了要更改位置的上一个节点!
pNode = pNode.next;
count++;
}
newNode.next = pNode.next; // pNode.next上一个节点的next属性的值,实际上就是要插入该位置之前的老节点的引用,将老引用赋值给新节点的next,代表原来的位置已经被新节点替代了
if (pNode.next != null){ // 如果老节点的next属性不为null,则表示老节点不是尾节点
pNode.next.pre = newNode; // 上一个节点的next就是要被新增位置处的老节点,将老节点的pre属性赋值为新节点的引用,表示老节点的上一个节点是新节点
}
pNode.next = newNode; // 将老节点的next属性赋值为新节点的引用,表示老节点的下一个节点是新节点
newNode.pre = pNode; // 将新节点的pre属性赋值为老节点的上一个节点的引用
return head;
}
(3)在单链表的结尾插入结点
表尾插入就比较容易了,我们只要将尾结点指向新结点就行了。
综上 ,我们写出链表插入的方法如下所示:
/**
* 链表插入
* @param head 链表头节点
* @param newNode 待插入节点
* @param position 待插入位置,从1开始
* @return 插入后得到的链表头节点
*/
public static Node insertNode(Node head, Node newNode, int position) {
if (head == null) { // 如果头节点为空,则直接将newNode节点赋值给head,表示newNode节点是新的头节点
head = newNode;
return head;
}
// 已经存放的元素个数
int size = getLinkedLength(head);
// 判断待插入位置是否越界
if (position < 1 || position > size + 1) {
System.out.println("插入位置越界");
return head;
}
// 1. 链表头部插入
if (position == 1) {
Node oldHead = head; // 保存原来的节点
newNode.next = oldHead; // pre是上一个节点的引用,将pre赋值给newNode的next属性,表示newNode的下一个节点是pre[原来的头节点]
oldHead.pre = newNode; // 将原来的节点的pre属性赋值为新节点的引用,表示原来的节点的上一个节点是新节点
head = newNode; // 将newNode赋值给head,表示newNode节点是新的头节点
return head;
}
Node pNode = head;
int count = 1;
//这里position被上面的size被限制住了,不用考虑pNode=null
while (count < position - 1) { // 找到要插入现在位置的前一个节点,方便操作
pNode = pNode.next;
count++;
}
newNode.next = pNode.next; // pNode.next上一个节点的next属性的值,实际上就是要插入该位置之前的老节点的引用,将老引用赋值给新节点的next,代表原来的位置已经被新节点替代了
if (pNode.next != null){ // 如果老节点的next属性不为null,则表示老节点不是尾节点
pNode.next.pre = newNode; // 上一个节点的next就是要被新增位置处的老节点,将老节点的pre属性赋值为新节点的引用,表示老节点的上一个节点是新节点
}
pNode.next = newNode; // 将老节点的next属性赋值为新节点的引用,表示老节点的下一个节点是新节点
newNode.pre = pNode; // 将新节点的pre属性赋值为老节点的上一个节点的引用
return head;
}
4.3 双向链表删除
删除同样分为在删除头部元素,删除中间元素和删除尾部元素。
(1)删除表头结点
话不多数,先上图:
从上图,我们可能有个疑问点,就node节点值为4的next仍然指向node节点值为15的next,但是head已经不再指向node节点值为4的节点,这种情况下JVM是会回收掉node节点值14的节点的,因为node节点值14的节点它自身的内存地址不被其他对象引用,JVM会将该节点标记为不可达,进而发生回收!
(2)删除最后一个结点
先看图:
删除最后一个节点,不管是单项链表还是双向链表无非是将倒数第二个节点的next指向null,让原来最后一个节点从链表上脱离出来;
结合上图只需要将cur.next = null即可做到删除链表尾部的节点,
被删除的节点自然最后也被JVM作为垃圾回收掉啦~~~
(3)删除中间节点
删除中间结点时,也会要用cur.next来比较,找到位置后,第一步将cur.next引用的值更新为cur.next.next,并且要将cur.next.next.pre值指向cur,如下图所示:

代码实现:
/**
* 删除节点
* @param head 链表头节点
* @param position 删除节点位置,取值从1开始
* @return 删除后的链表头节点
*/
public static Node deleteNode(Node head, int position) {
if (head == null) { // 如果头节点为空,则直接返回head
return head;
}
// 已经存放的元素个数
int size = getLinkedLength(head);
// 判断待删除位置是否越界
if (position < 1 || position > size) {
System.out.println("删除位置越界");
return head;
}
// 1. 删除头节点
if (position == 1) {
head = head.next;
return head;
}
else { // 2. 删除尾节点或者中间节点
Node cur = head;
int count = 1;
while (count != position - 1){ // 找到要删除位置的上一个位置的节点, 注意:这里为什么是position - 1 , 如果是postion, 此时while循环会继续执行,直接将postion上一个节点的next赋值给cur,那么此时cur已经是尾节点了,cur.next就是null,那么cur.next.pre就会报空指针异常
cur = cur.next;
count++;
}
Node temp = cur.next; // 保存要删除的节点
cur.next = temp.next; // 要被删除节点的下一个节点
// 上面两步也可以简写为 cur.next = cur.next.next;
if (temp.next != null){ // 如果要删除的节点的next属性不为null,则表示要删除的节点不是尾节点
temp.next.pre = cur; // 将要删除节点的下一个节点的pre属性赋值为要删除节点的上一个节点的引用,表示要删除节点的下一个节点的上一个节点是要删除节点的上一个节点
}
return head;
}
}
5-github完整代码下载地址:
https://github.com/bruce-pang/brucepang_arthas_java.git
看都看到这儿了,给个三连鼓励一下吧QAQ















 425
425











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









