






转载自:二元决策图(Binary Decision Diagrams - BDD) (一)
在形式化验证、数字系统的设计和验证中,许多任务都涉及大型命题逻辑公式的运算。二元决策图(BDD)已经成为许多应用的首选表示方法。1986年,Bryant发表论文指出归约有序的二元决策图是布尔函数的规范表示。
几个基本概念:
布尔函数(Boolean function)描述如何基于对布尔输入的某种逻辑计算确定布尔值输出,它们在复杂性理论的问题和数字计算机的芯片设计中扮演基础角色。比如下面的逻辑电路:

可以使用布尔函数:来表示。
有 n 个变量的布尔函数 F 为:
函数有个不同的可能输入,输出为一个True或False的布尔值,我们使用1或0来表示。
我们定义新的具有 n-1 个变量的布尔函数:
和
'称为 F 的余因子(cofactor)。
为正因子,
为否定因子。
香农展开(Shannon's expansion),或称香农分解(Shannon decomposition)是对布尔函数的一种变换方式。它可以将任意布尔函数表达为其中任何一个变量乘以一个子函数,加上这个变量的反变量乘以另一个子函数,即:
INF范式(If-then-else Normal Form – INF)
If-then-else运算符表示为,则INF运算符定义为:
即,如果x值为1,则结果为y0,否则结果为y1。
所有逻辑运算符都可以仅使用 if-then-else 运算符和常量0和1表达。此外,if-then-else运算可以这样实现,即所有的测试都只在(未取反的)变量上进行,变量不会出现在其他地方。比如,¬x就是x→0,1。这样,if-then-else算子产生了一种新的范式 – INF范式(If-then-else Normal Form – INF)。
INF范式是完全由 if-then-else 运算符和常量构建的布尔表达式,因此仅需要对变量执行测试。
用t[0/x]表示将 t 中的变量 x 赋值为 0 得到的布尔表达式,得到以下等式:
![]()
这个就是表达式 t 对变量 x 的香农展开。这个简单的方程有很多有用的应用。第一个是可以从任何表达式 t 生成一个 INF。 如果 t 不包含任何变量,则它等于 0 或 1,即一个INF。否则,我们就生成表达式t中的一个变量 x 的香农展开式。其中 t[1/x] 和 t[0/x] 比表达式 t 少一个变量,这样可以递归做香农展开。
二元决策树(Binary Decision Tree)
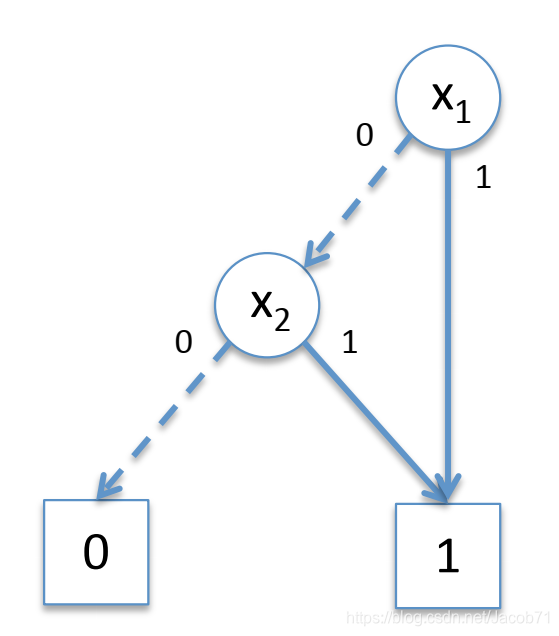
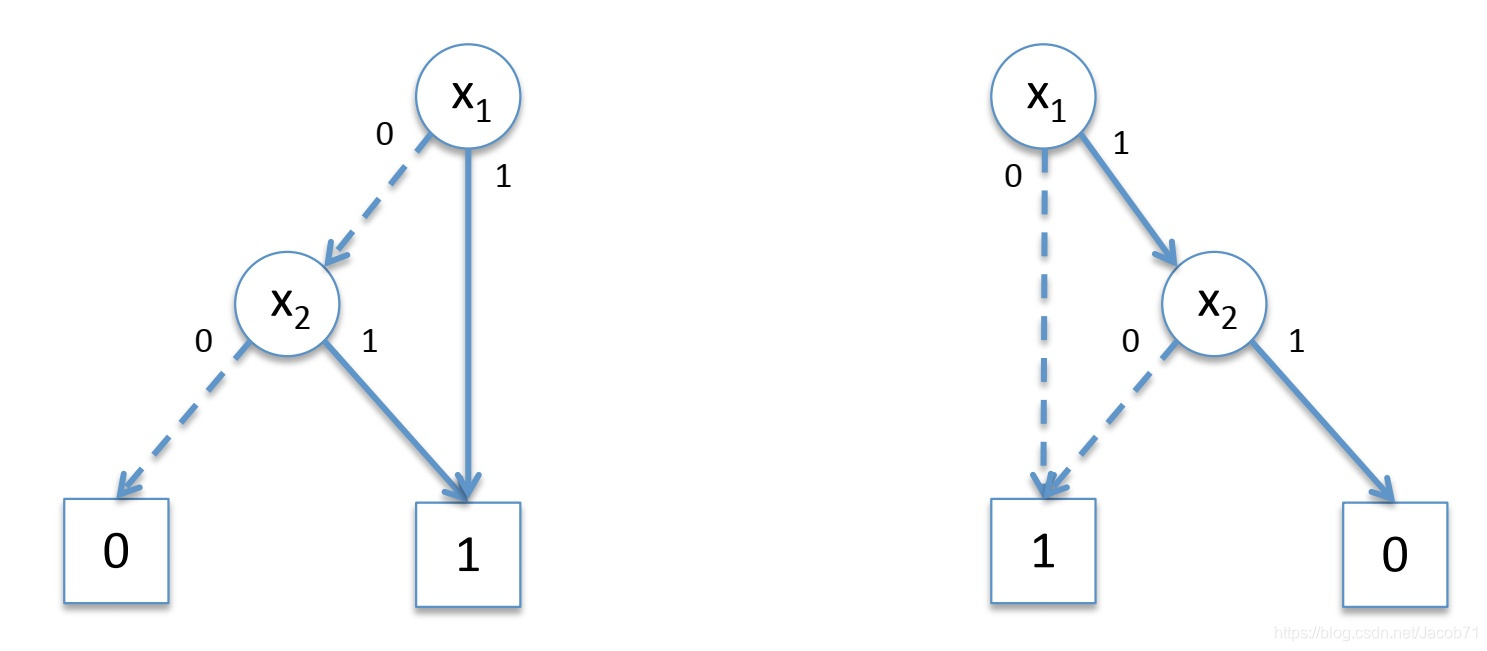
二元决策树与二叉树类似,上面的逻辑电路/函数对应的有序二元决策树如下图:
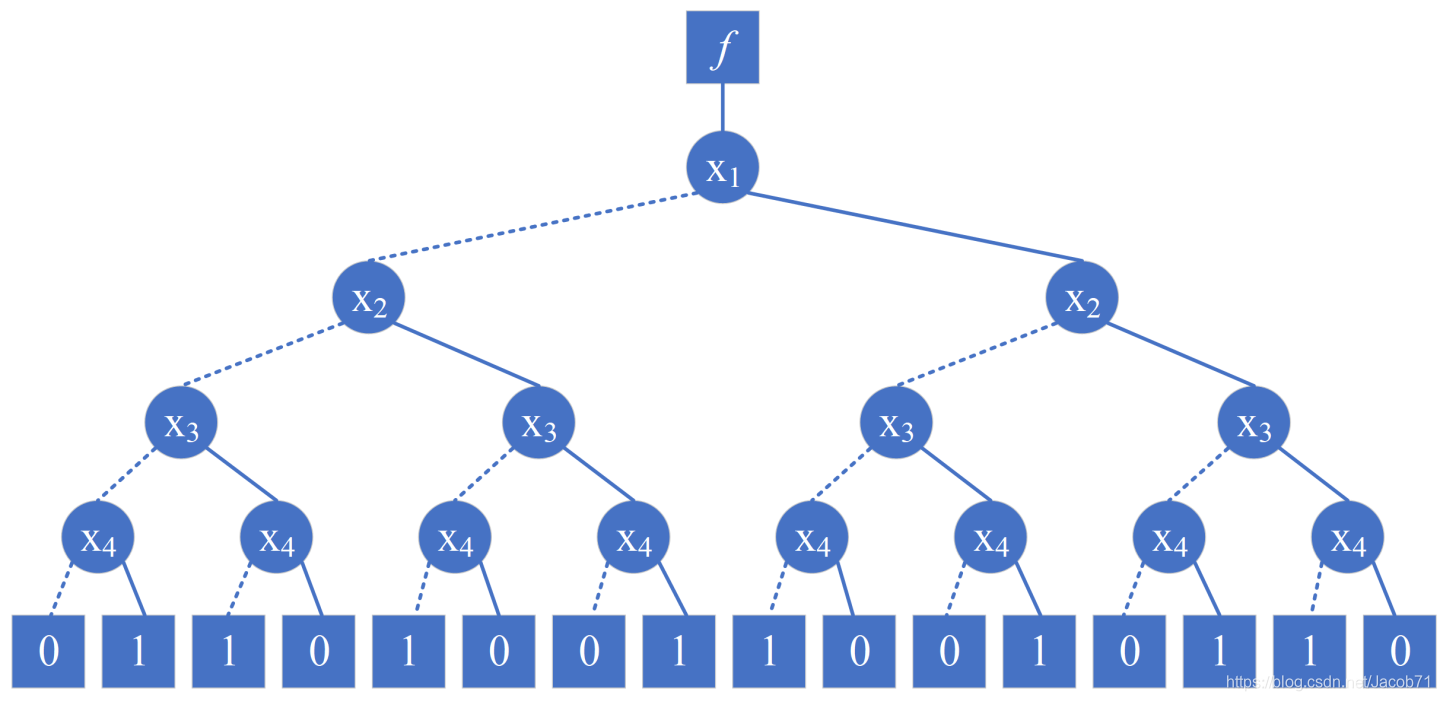
标记为 的顶部节点为函数节点,标记有变量名字的圆形节点为内部节点,底部的正方形节点为终端节点(标记为1-True或0-False)。给定一组变量值,计算函数
的值,只需要从函数节点沿着路径找到终端节点,终端节点的标记即为函数的值。
一个内部节点,如果所标记变量的值为1,则沿着实线弧前进(也称为then弧/边,或High弧/边);否则沿着虚线弧前进(也称为else弧/边,或low弧/边)。
在一个有序二元决策树中,变量在所有的路径上出现的顺序是一样的,如上图中:![]() 。
。
二元决策树最大的问题是它们的规模。一个有 n 个变量的二元决策树有个节点,加上
个最低层次终端节点的链接,指向返回值0和1。
二元决策图(Binary Decision Diagrams - BDD)
归约(Reduction)
通常,BDD通过对BDT归约而得到。归约由以下两条规则的应用组成,从决策树开始,一直到两条规则都不能应用为止。
- 如果两个节点是终端节点且具有相同的标签,或者是内部节点且具有相同的子节点,则将它们合并。
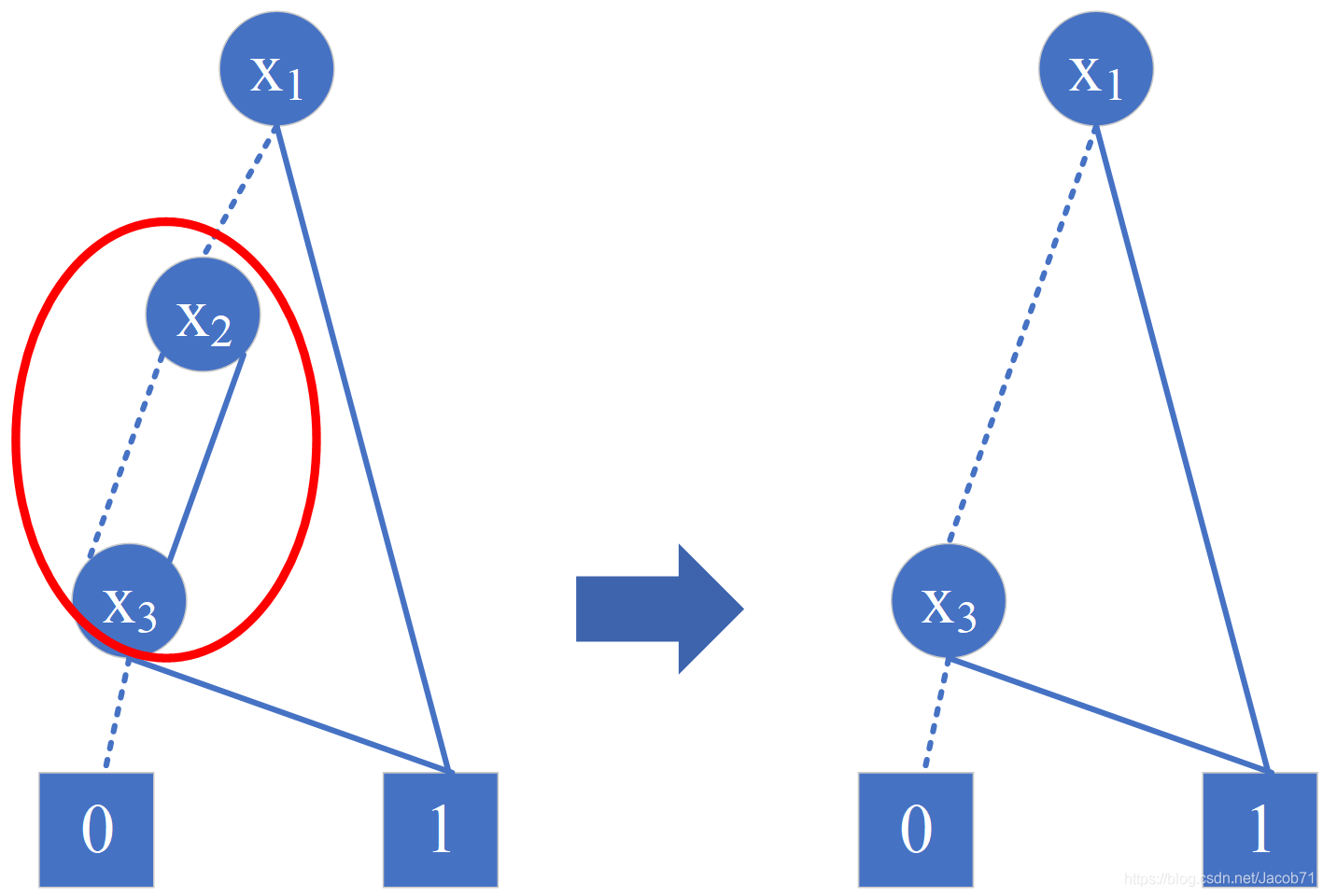
- 如果内部节点的 high 边和 low 边指向相同的子节点,则将该节点从图中删除,并将其父节点重定向到子节点。
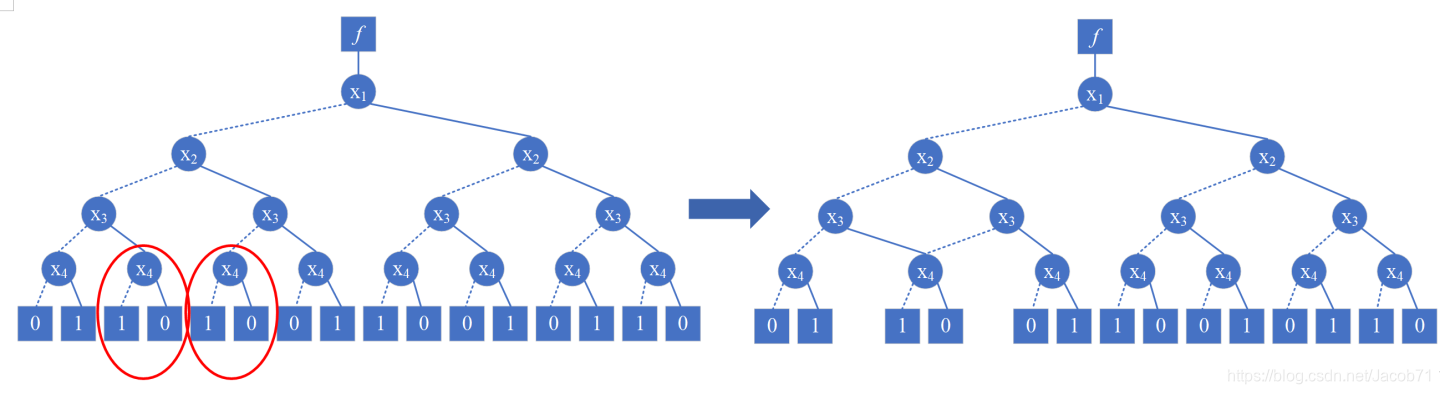
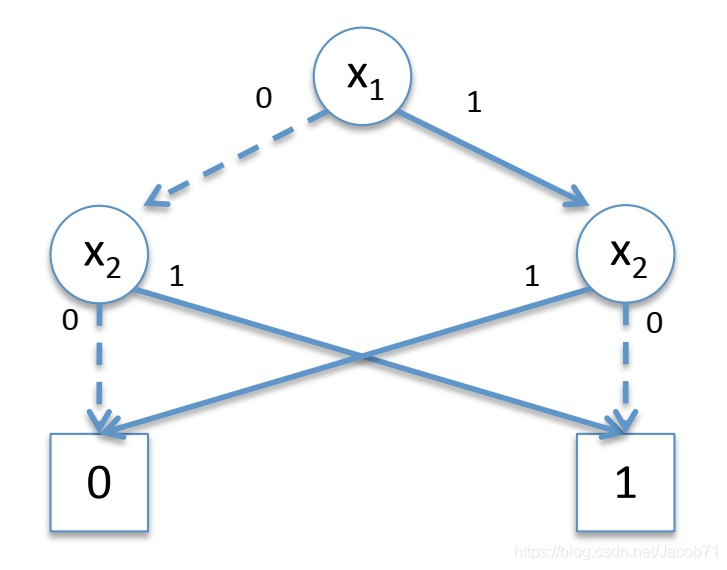
上图左图中,红色椭圆中的两个节点相同,应用规则1得到右图。重复应用规则1:
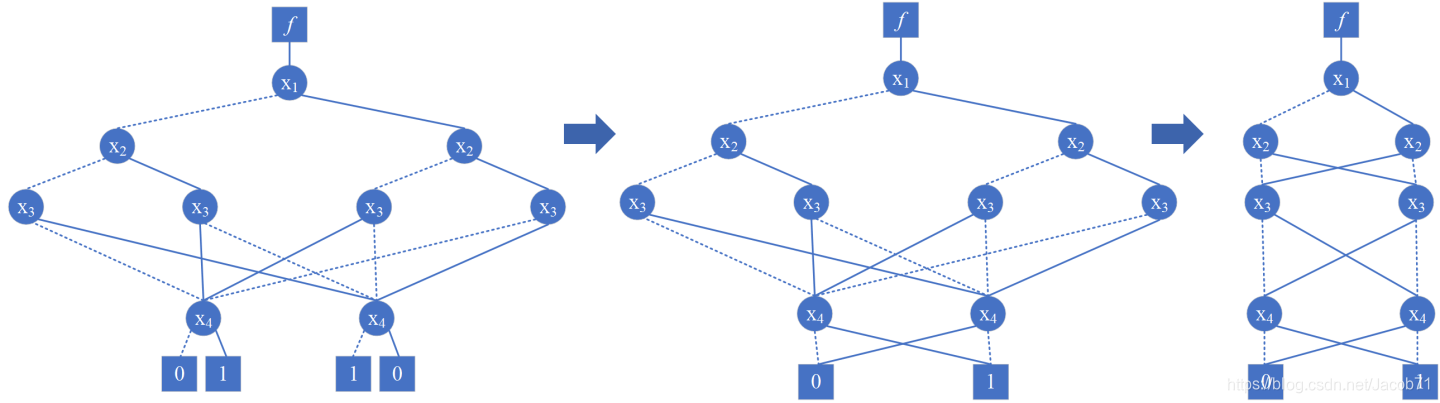
应用规则2,简化下图中的左侧椭圆中的节点,得到右侧图
通常,我们说BDD是指ROBDD,即归约有序的二元决策图
现在我们给出定义:
BDD是一个有根的,有向无环图:
- 一个或两个出度为0的终端节点,标记为0或1,并且
- 出度为2的变量节点 u 的集合。节点的2个出边由 low(u) 和 high(u) 定义(在图中显示为虚线和实线),节点关联变量 var(u)。
如果在图中的所有路径上,变量都遵循给定的线性顺序![]() ,则BDD为有序的(OBDD)。
,则BDD为有序的(OBDD)。
一个(O)BDD是归约的(R(O)BDD),如果:
- (唯一性)没有两个不同的节点 u 和 v 具有相同的变量名和 low- 和 high- 子节点,即: var(u)=var(v), low(u)=low(v), high(u)=high(v),这意味着 u=v,并且
- (非冗余测试)没有变量节点 u 具有相同的 low- 和 high- 子节点,即: low(u)≠high(u)
构建ROBDD(简写为BDD)
构造BDD的简单方法是构造一个二元决策树,然后逐步消除冗余并标识相同的子树。但是,因为需要构造原始决策树,所以需要指数级时间。
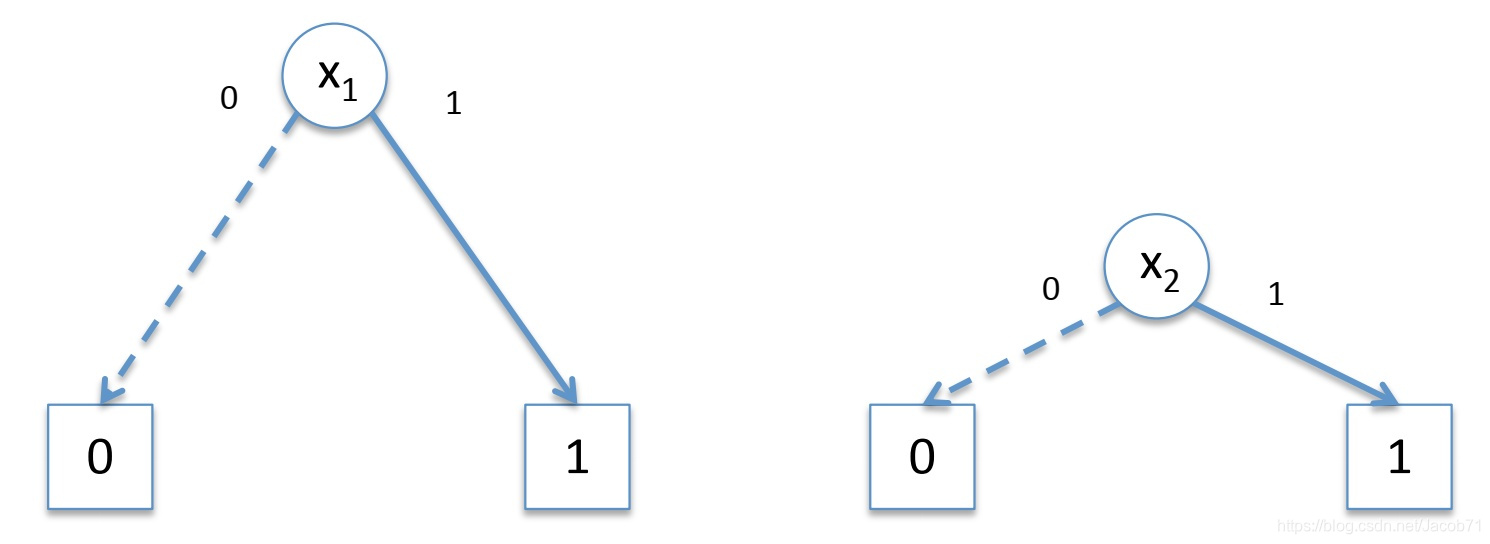
另一种方法是在构建BDD的过程中同时进行BDD的归约过程。将每个布尔函数作为表达式,使用BDD进行运算、归约,得到最终的BDD。以![]() 为例,看布尔运算如何使用BDD实现。首先,我们构建
为例,看布尔运算如何使用BDD实现。首先,我们构建的BDD。变量
和
的BDD为(变量顺序:
![]() ):
):
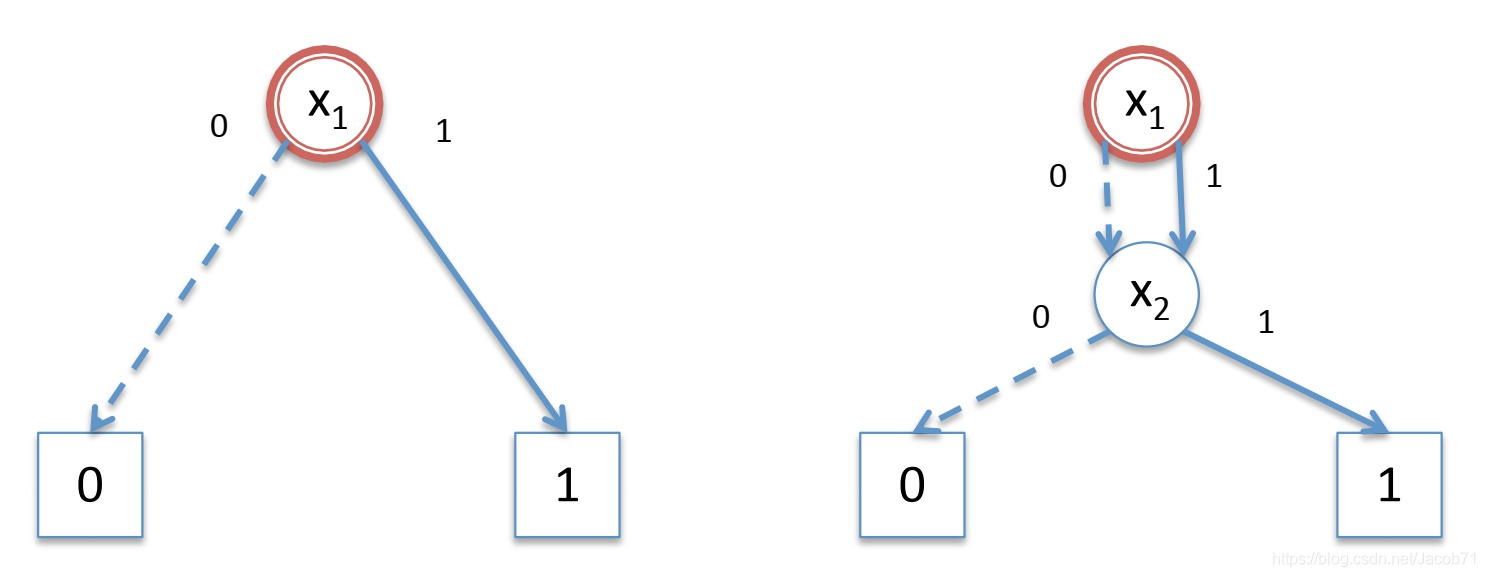
对两个具有相同变量顺序的BDD,在应用任何布尔操作时,需要从根节点开始,沿着平行路径到终端节点。一旦到达终端节点,将指定的布尔运算应用于布尔常数0和1,以形成指定路径的结果。对于没有出现的变量,需要进行(隐式地)扩展。在这个例子中,左边是![]() ,右边是假设的
,右边是假设的![]() ,隐式扩展如下:
,隐式扩展如下:
沿着![]() 节点的左边和右边往下到达子节点,同样这里需要进行(隐式地)扩展,得到一个假设的
节点的左边和右边往下到达子节点,同样这里需要进行(隐式地)扩展,得到一个假设的![]() ,如下图,底部是这一步构造的BDD。
,如下图,底部是这一步构造的BDD。
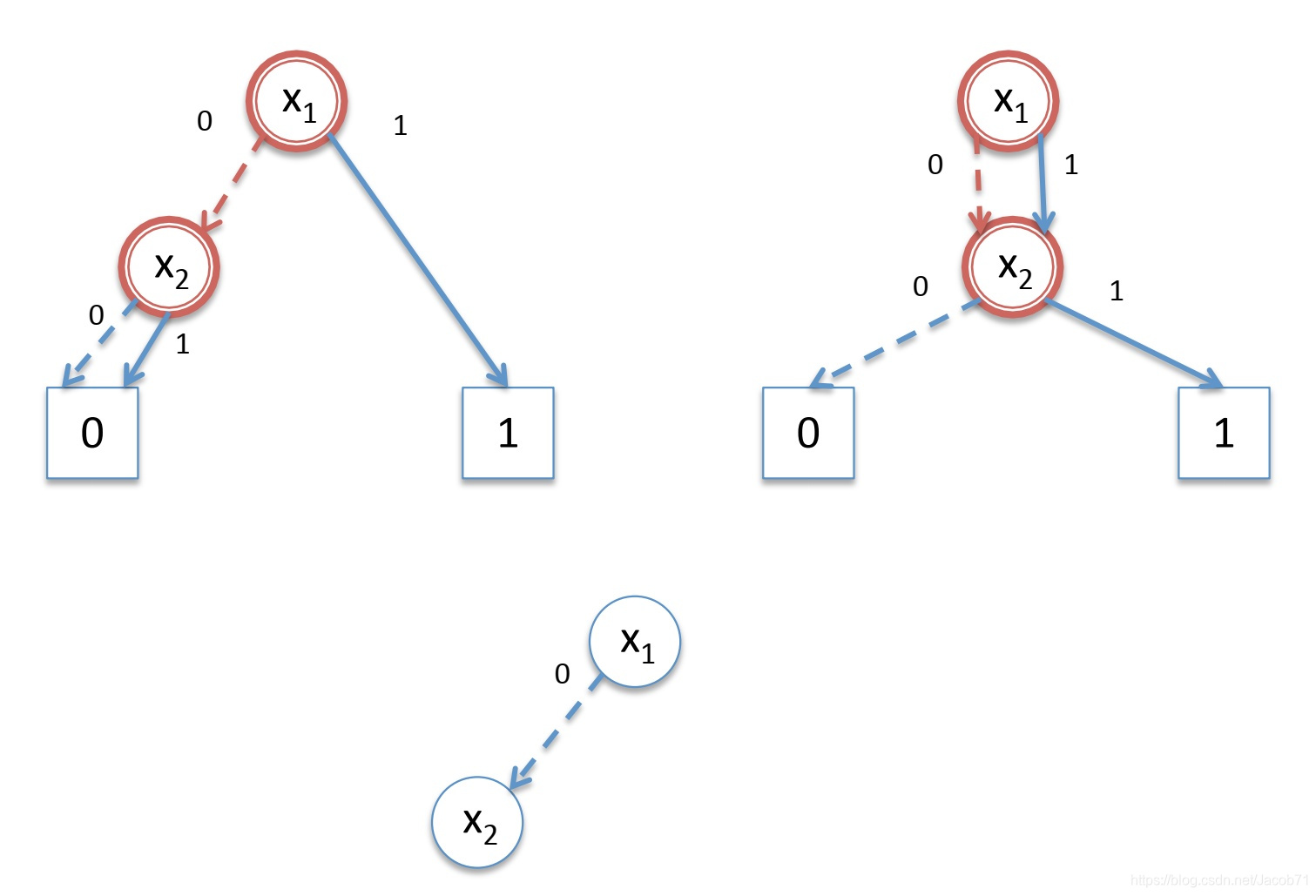
在两个给定的BDD中都沿着0-边往子节点走。两者都指向0,我们计算![]() ,并将0作为结果,得到下面底部的BDD。
,并将0作为结果,得到下面底部的BDD。
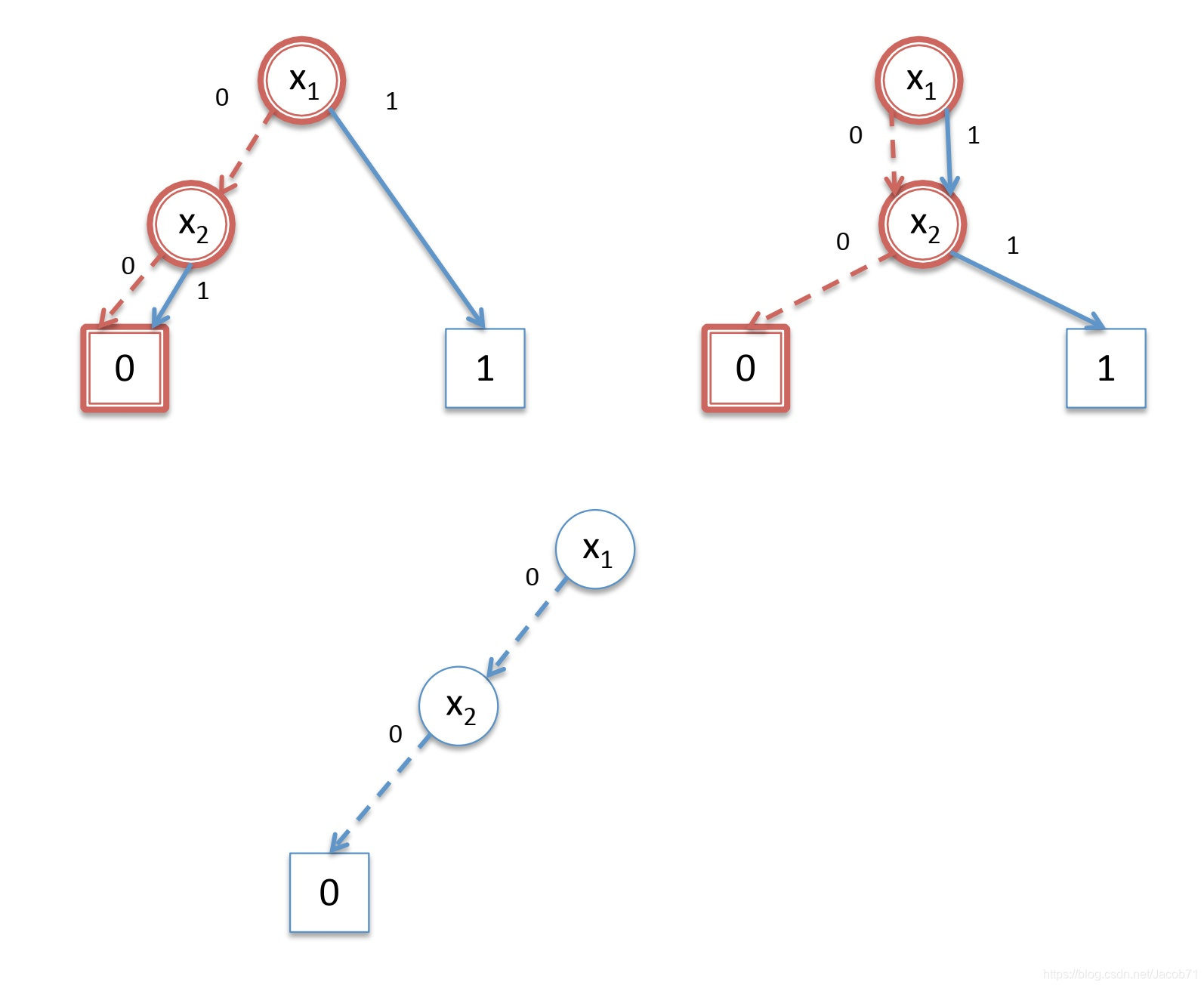
完成终端节点处理后,返回到上一层到![]() 节点,并沿着1-边往子节点走,左边的图上是标记为0的终端节点,右边的图上是标记为1的终端节点,计算
节点,并沿着1-边往子节点走,左边的图上是标记为0的终端节点,右边的图上是标记为1的终端节点,计算![]() ,得到下面底部的BDD:
,得到下面底部的BDD:
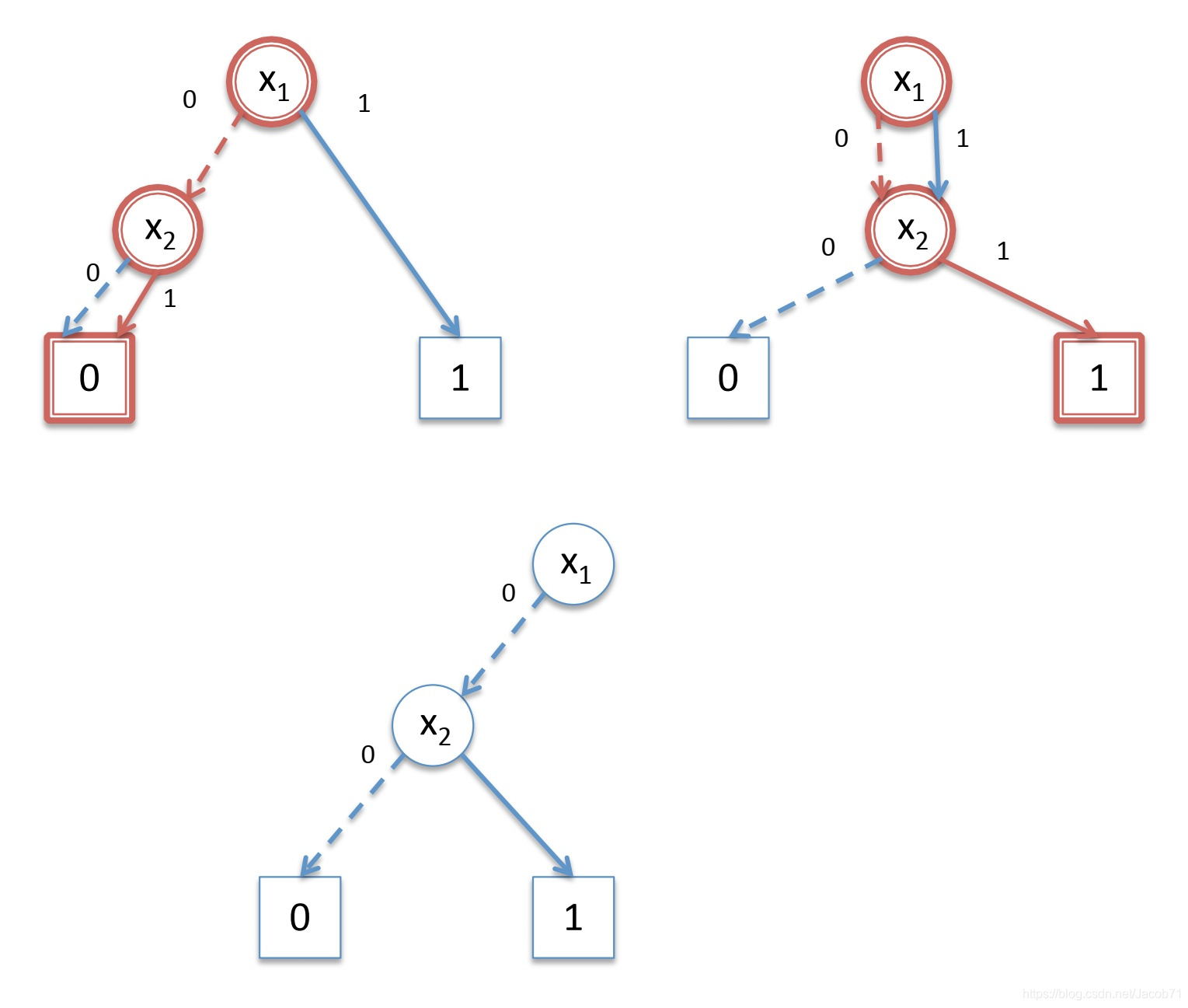
继续从![]() 节点返回
节点返回![]() 节点,沿着
节点,沿着![]() 节点的1边往下。左图需要进行(隐式地)扩展,得到一个假设的
节点的1边往下。左图需要进行(隐式地)扩展,得到一个假设的![]() 节点。然后,沿着
节点。然后,沿着![]() 节点的0边往下,得到
节点的0边往下,得到![]() ,得到下面底部的BDD:
,得到下面底部的BDD:
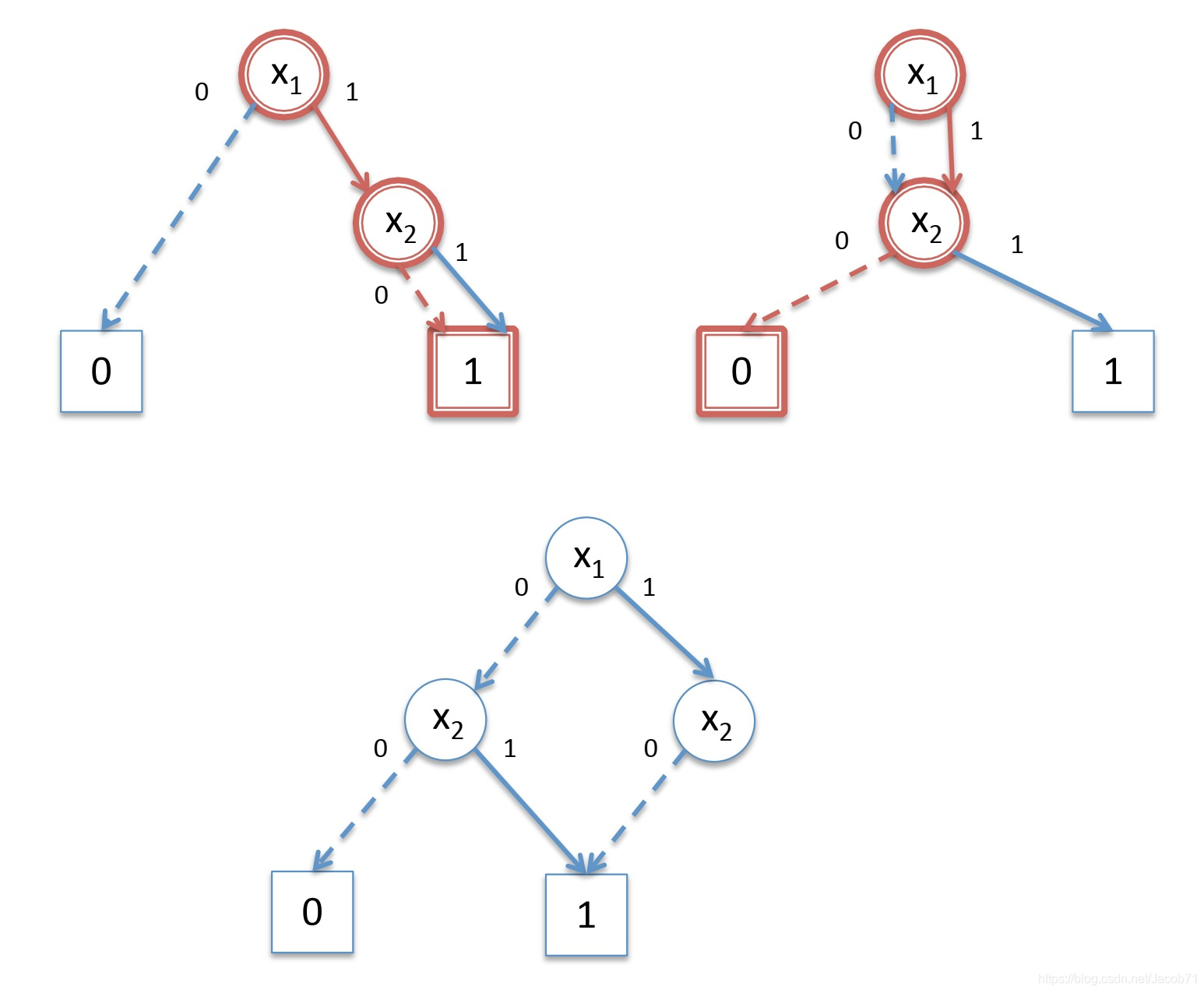
最后沿着![]() 节点的1边往下,再次到达标记为1的终端节点,如下图。
节点的1边往下,再次到达标记为1的终端节点,如下图。
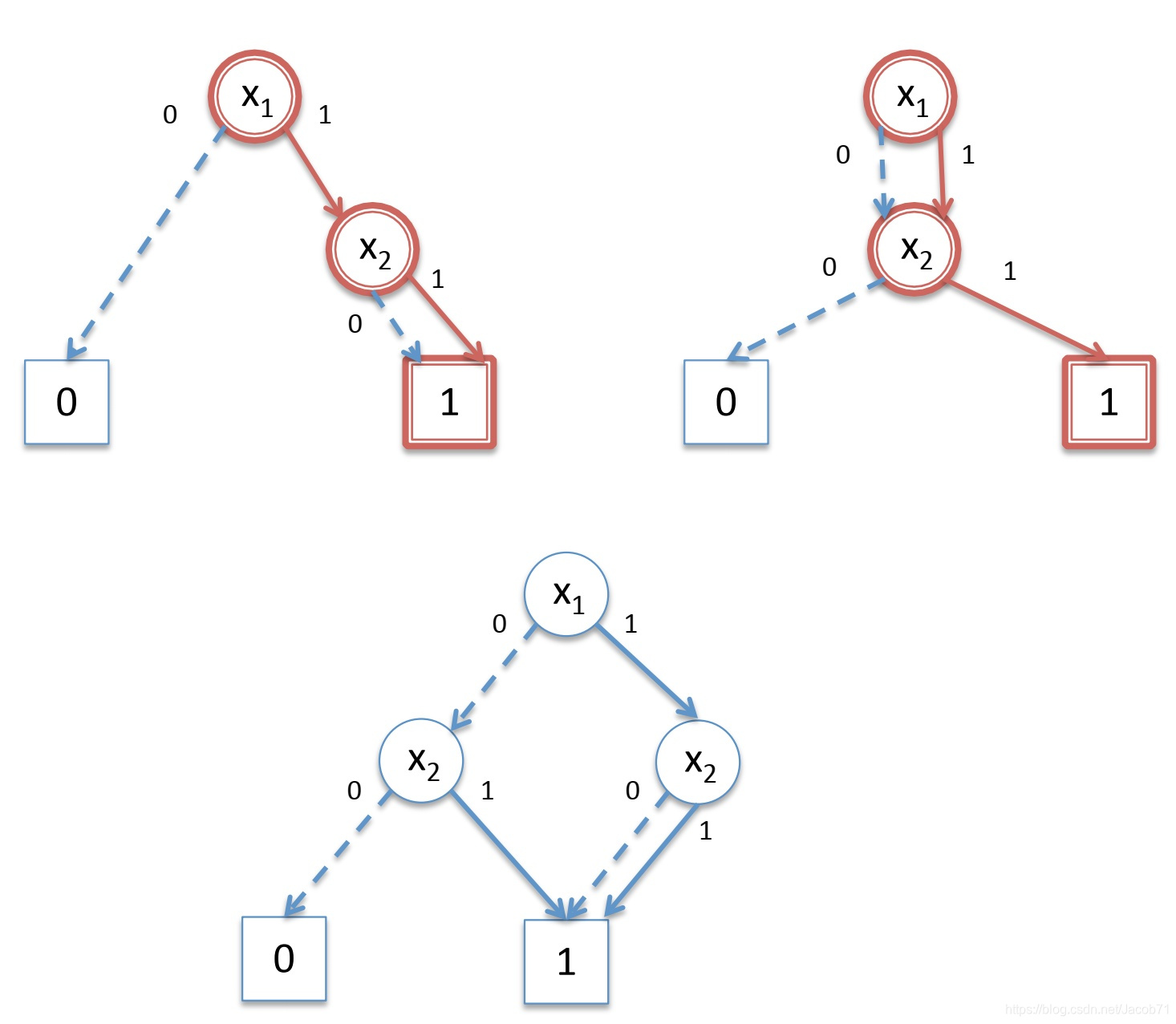
从图中可以看到,右侧![]() 节点的low和high子节点是相同的,按照前面提到的规则2,需要消除这个节点,只返回一个对常量1终端节点的引用。至此,我们得到了
节点的low和high子节点是相同的,按照前面提到的规则2,需要消除这个节点,只返回一个对常量1终端节点的引用。至此,我们得到了![]() 的已经熟悉的BDD,如下图所示。
的已经熟悉的BDD,如下图所示。
由此,我们可以总结两个二元决策图应用布尔运算的算法如下:
- 并行地遍历两个图,在两个给定的图中始终同时沿着0-边或1-边移动
- 当一个变量在一个图中存在,而不在另一个图中时,我们就像它存在并且有相同的high和low子节点一样继续进行(前面提到隐式地扩展,即实际上并不会创建节点,而是直接递归调用下去,后面的代码分析中可以看到,这里采用扩展结点是为了方便说明)
- 当到达两个图的终端结点0或1时,对这些常量应用布尔运算并返回相应的常量
- 如果对low和high子节点的运算返回相同的节点,不构造一个新节点,而只是返回在树中已经获得的单个节点。避免冗余
- 如果将要构造一个已经在结果图中某处的节点(也就是说,具有相同的变量标签和相同的后续节点),不要创建一个新的副本,而只是返回已经存在的节点
对于![]() ,按照上述的步骤构建
,按照上述的步骤构建![]() ,如下图的右侧:
,如下图的右侧:
用上述步骤完成2个BDD的运算,得到下面最终的BDD:
BDD构建算法
本节介绍构建BDD的算法以及实现,代码实现以BuDDy开源代码为例。
数据结构
算法实现需要2个核心的数据结构,即节点表和节点hash表。
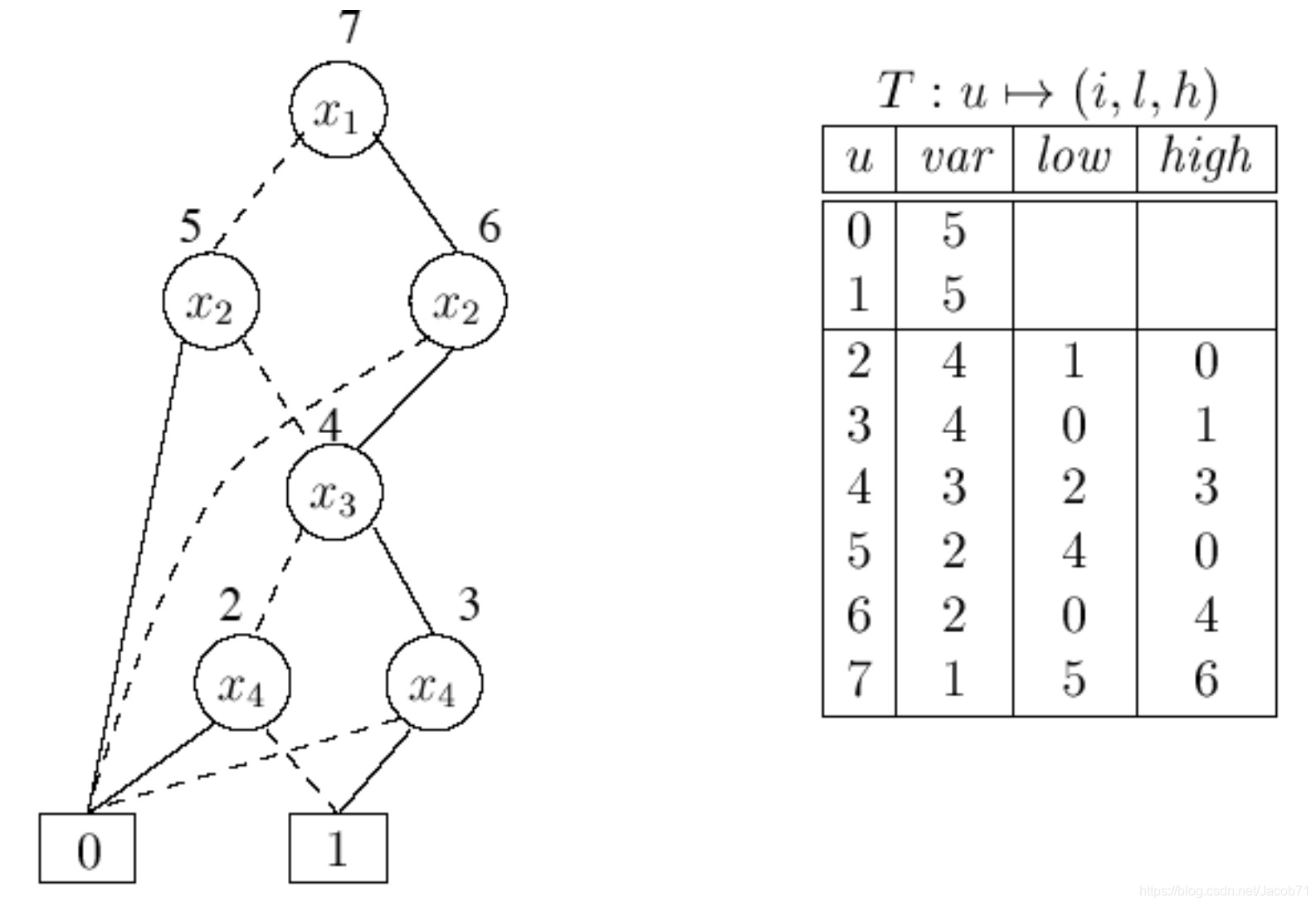
节点表
这里以数组形式描述节点表,如下图所示,数组下标使用 u 表示,即节点ID,其中数组中第0和1元素预留给终端节点。BDD的变量以索引形式表示,如按照一定顺序排列的变量,使用1,2,⋯,n 索引来表示。节点表中的一个节点元素由变量、左子节点和右子节点组成,即var(u) = i, low(u)=l, high(u)=h。节点表T:u⟼(i,l,h),使用节点索引查询节点的信息,即var(u) = i, low(u)=l, high(u)=h。
下面是BuDDy中节点的数据结构:
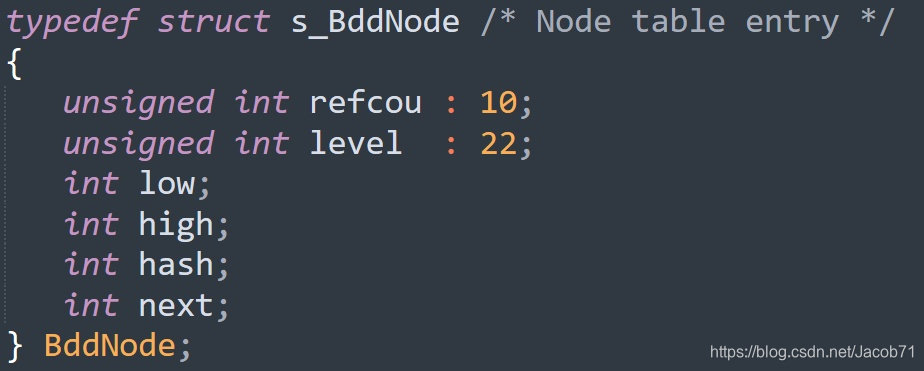
level为节点变量ID,与low和high一起是上面介绍的节点核心信息。
Hash表
Hash表 H:(i,l,h)⟼u 将三元组 (i,l,h) 映射到节点ID,即节点的索引 u 。主要用于快速检索某一个三元组对应的节点是否存在,如果存在返回存在节点的索引。
BuDDy将Hash表合并到了节点表中,将三元组 (i,l,h) 做hash运算后,得到一个节点表索引,该索引所指向节点中的int hash变量保存的是实际 hash 指向节点的索引。如果有hash冲突,则使用int next串成单向链表。下面代码是检索时的逻辑:
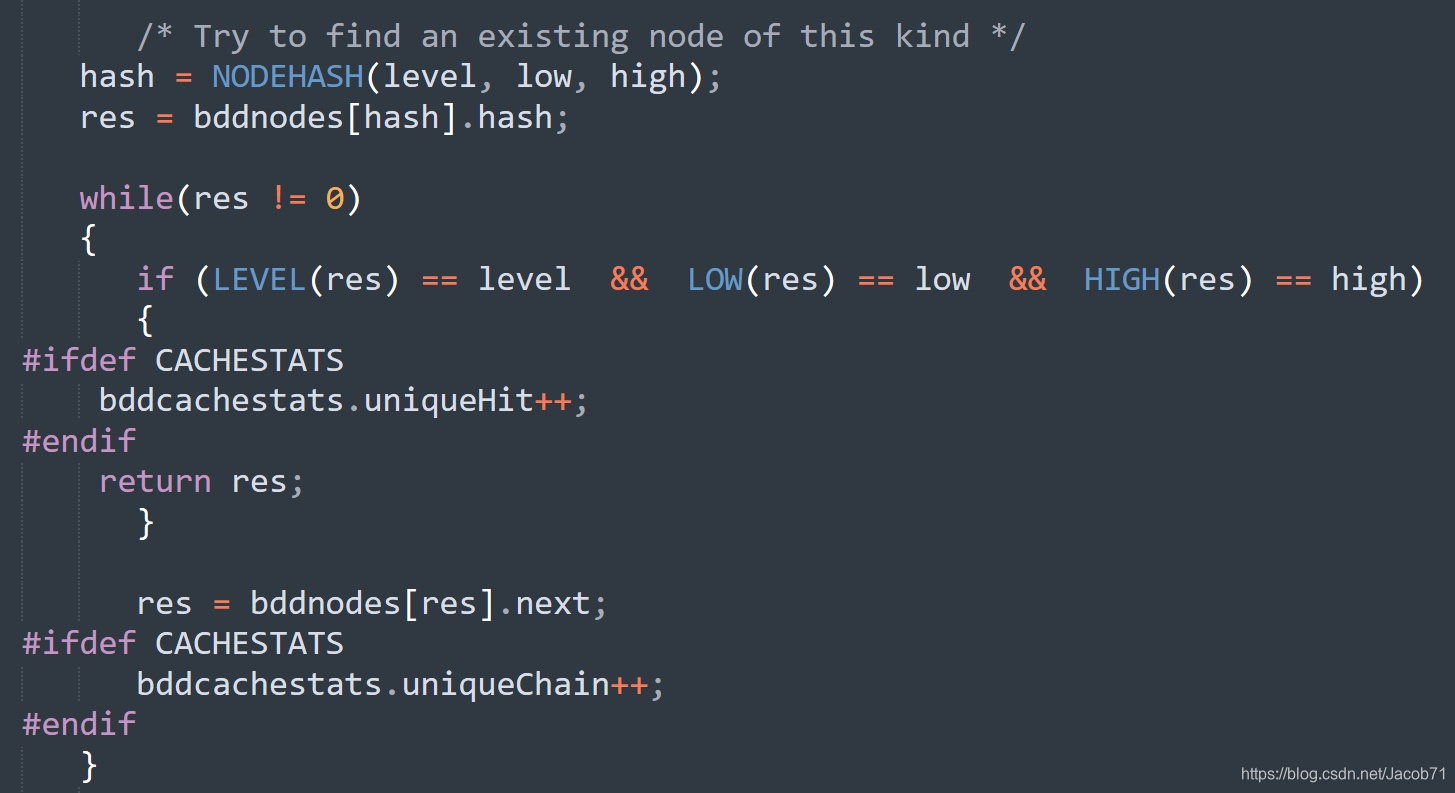
构建函数
生成节点
生成节点函数用于确定待生成节点 (i,l,h) 是否已经存在,即是否存在已知的节点u:var(u) = i, low(u)=l, high(u)=h,确保生成的BDD是归约的。生成节点函数算法:
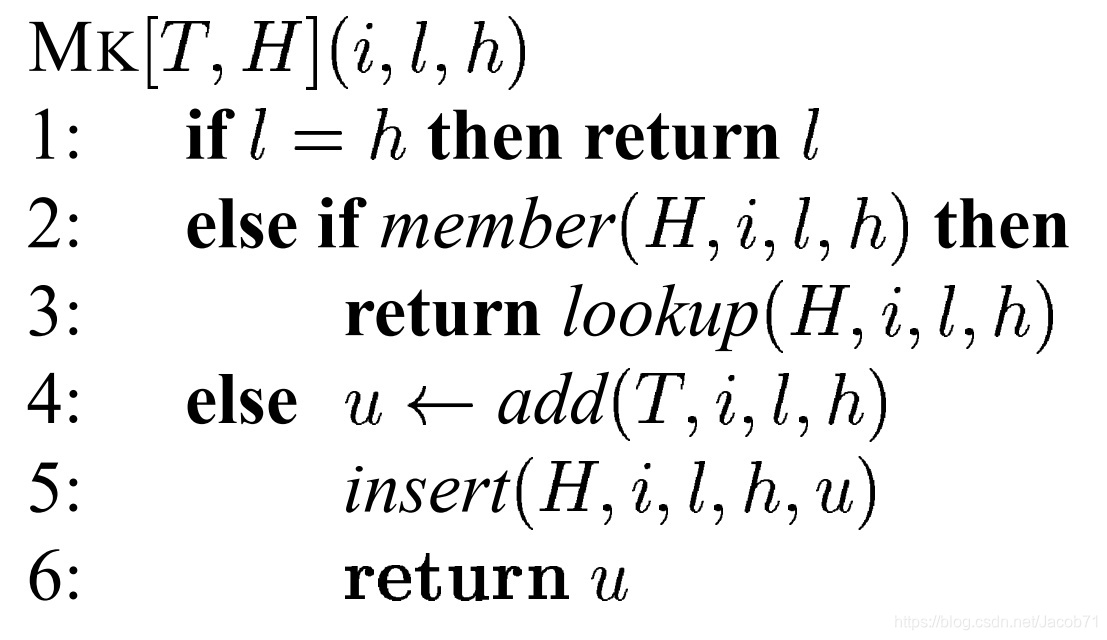
第一行是前面的规则2,即如果一个节点的左子节点和右子节点是同一个节点,则不创建新的节点,直接返回子节点。
第二行查询hash表,当前要创建的节点是否已经存在,如果已经存在,则返回当前的节点,不创建新的节点。如果当前要创建的节点不存在,则需要创建新的节点,添加到节点表中,更新hash表,并返回创建的节点。
该函数实现了归约的规则1和2,如果建立BDD时所有节点均通过这个函数创建,则能够确保创建的BDD是归约的。
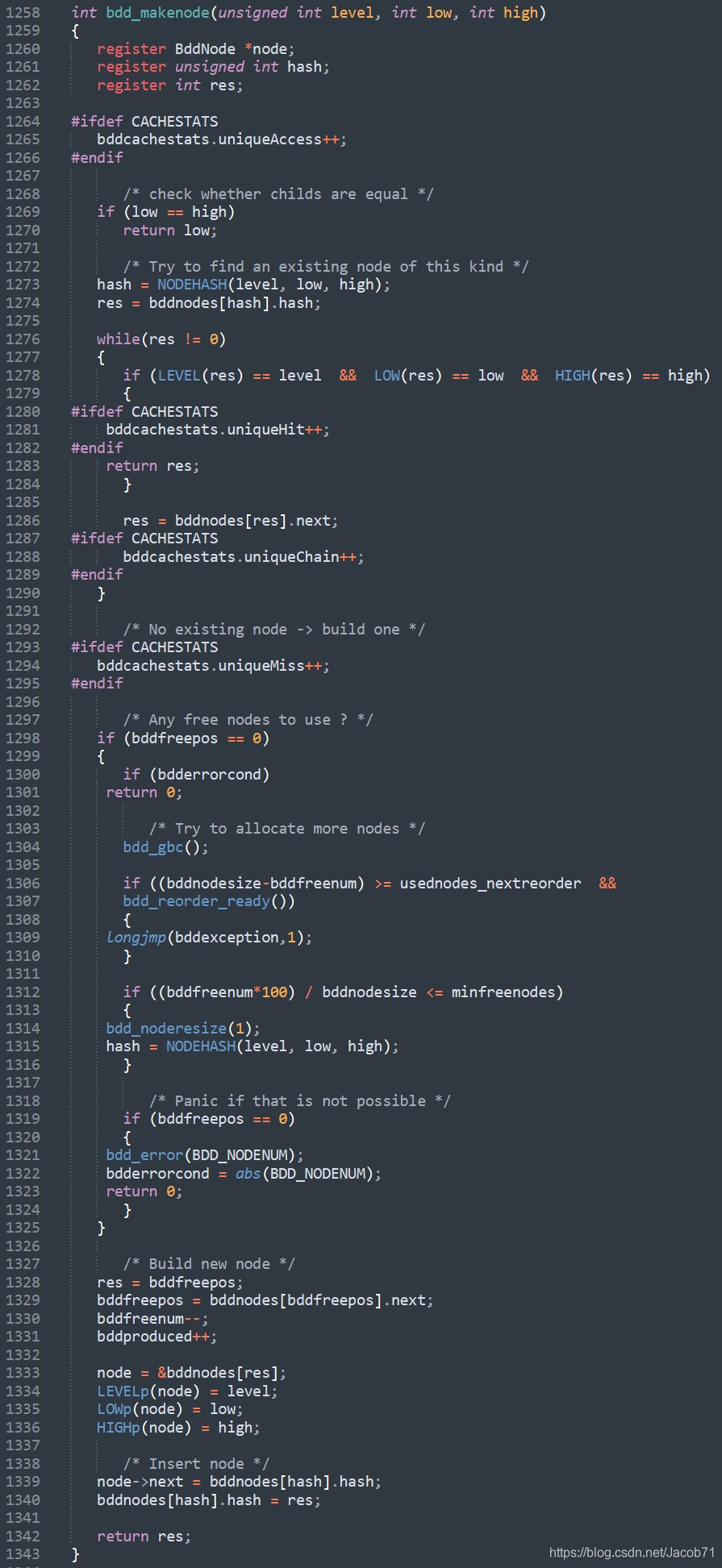
下面是BuDDy代码中的创建节点函数。1269行是规则2的判断。1273~1290行是查hash表,如果找到,则直接返回现有的节点res;如果没有找到,1297后的代码创建新的节点,并更新hash表,1298~1325涉及到节点内存的管理。
布尔运算函数
所有布尔运算均由 APPLY(op,u1,u2) 函数完成,即计算![]() 。APPLY的实现基于香农展开:
。APPLY的实现基于香农展开:![]() 。对于所有布尔运算有:
。对于所有布尔运算有:。
算法从两个BDD的根节点开始,通过递归地构造low分支和high分支来计算结果BDD,然后由它们形成新的根节点。为了避免递归调用的指数膨胀,使用了动态规划。算法如下图。
动态规划使用结果表G实现。表中的每个表项 (i,j) 或者为空,或者保存有以前 APP(i,j) 的计算结果(第4行)。算法区分四种不同的情况(5~11行),第一种处理两个参数都是终端节点的情况,其余三种处理至少一个参数是变量节点的情况。

如果 和
中至少有一个是非终端节点,算法根据变量index继续处理。如果节点具有相同的索引,则对两个low分支进行配对,并对其进行递归计算。对于high分支也是如此。这与前面的公式完全对应。如果它们有不同的index,继续将具有最低index的节点与另一个节点的low分支和high分支配对。这里,就是前面介绍的隐式的扩展结点(只是为了便于理解),实际上并不会创建节点。这个对应于这个公式:
下面是BuDDy中apply调用的apply_rec函数(前面的APP函数)的代码,op参数为全局变量applyop,没有通过函数调用传入。
544~590处理逻辑运算的特殊情况。
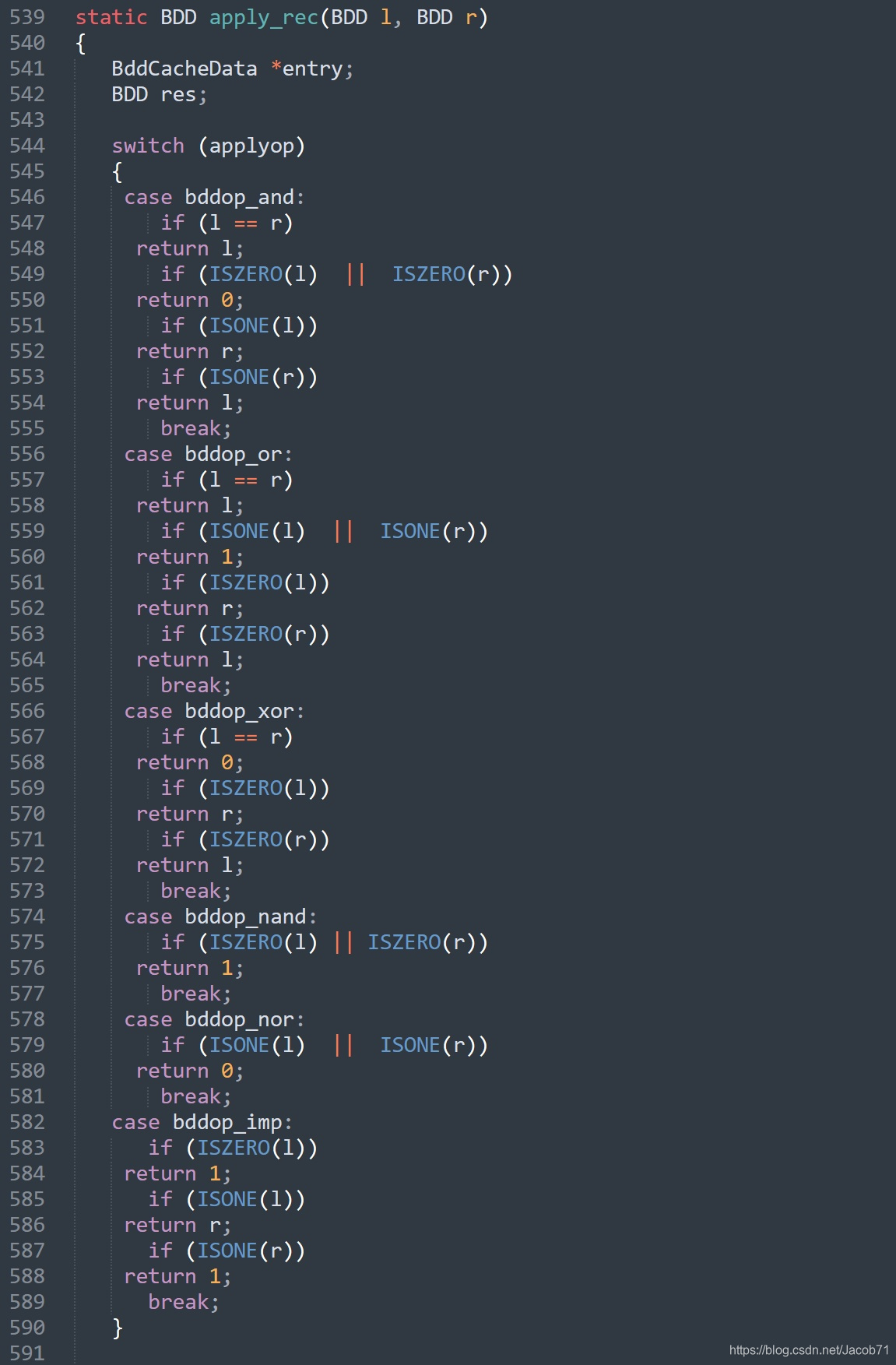
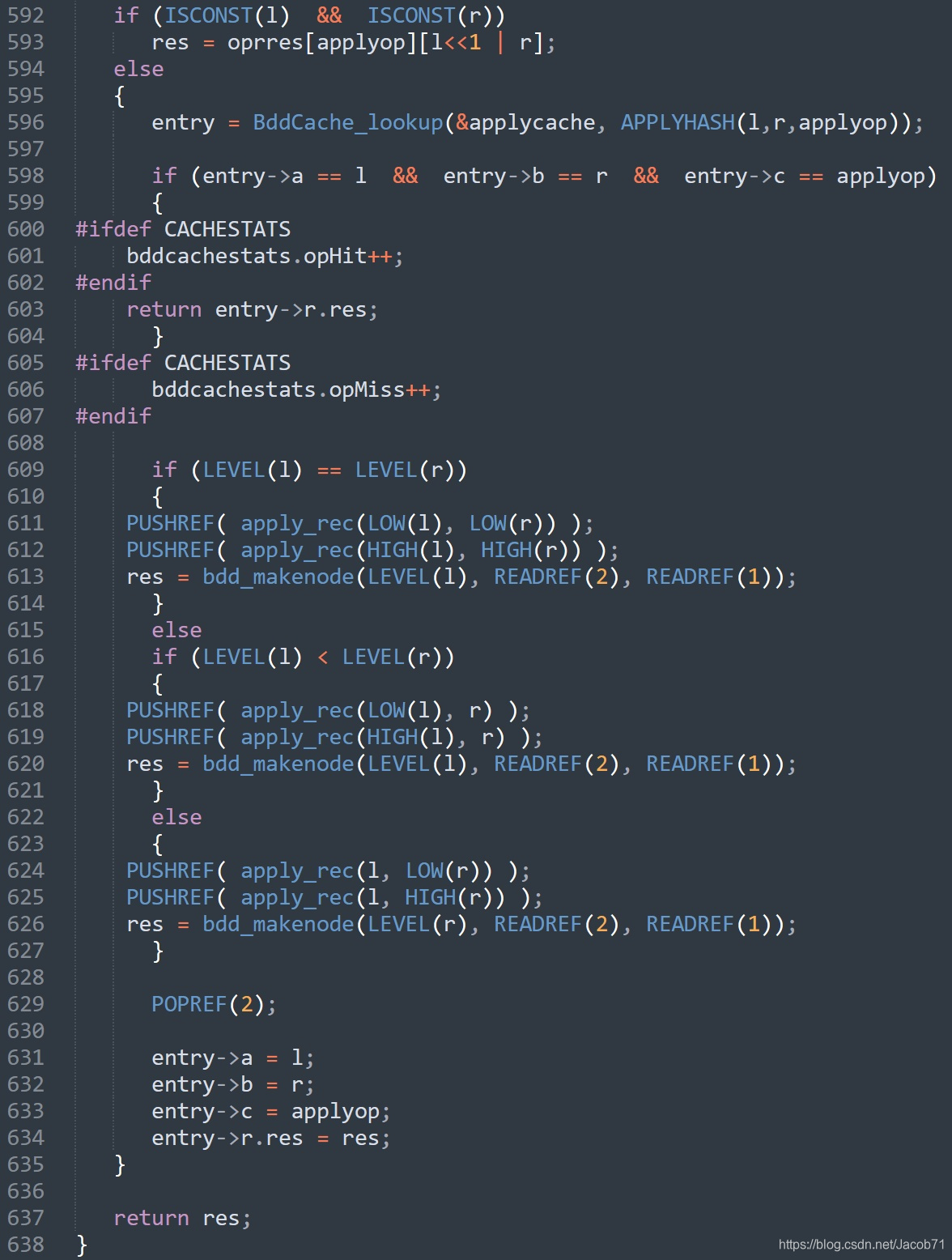
592~593处理两个操作数同时为常量的情况。596~604检索前面提到的结果表,这里称之为chache。609~627为其他3种情况的处理,这里使用了堆栈来保存结果。631~634将本次计算的结果保存到结果表(cache)中。
参考文献:
[1] R. E. Bryant. Graph-based algorithms for boolean function manipulation. IEEE Transactions on Computers, C-35(8):677–691, August 1986.
[2] Frank Pfenning. Lecture Notes on Binary Decision Diagrams. October 28, 2010
[3] Henrik Reif Andersen. An Introduction to Binary Decision Diagrams. Fall 1999
[4] Fabio SOMENZI. Binary Decision Diagrams.

















 1745
1745

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









