






部分图片截图自狂神说的ES教程
本博客主要记录学习狂神说ES教程的笔记
ElasticSearch简介
Elasticsearch 是什么?
Elasticsearch 是一个分布式的免费开源搜索和分析引擎,适用于包括文本、数字、地理空间、结构化和非结构化数据等在内的所有类型的数据。
Elasticsearch 的用途是什么?
Elasticsearch 在速度和可扩展性方面都表现出色,而且还能够索引多种类型的内容,这意味着其可用于多种用例:
- 应用程序搜索
- 网站搜索
- 企业搜索
- 日志处理和分析
- 基础设施指标和容器监测
- 应用程序性能监测
- 地理空间数据分析和可视化
- 安全分析
- 业务分析
ElasticSearch安装
最低要求JDK1.8

https://www.elastic.co/cn/downloads/elasticsearch
解压就可以使用

熟悉目录


运行elasticsearch.bat,测试访问127.0.0.1:9200
安装可视化界面 es head的创建
https://www.jb51.net/article/170425.htm
安装成功后,访问localhost :9100,连接http://localhost:9200/,却出现跨域问题:

解决:打开ElasticSearch的配置文件elasticsearch.yml,添加2行:
- http.cors.enabled: true
- http.cors.allow-origin: “*” #让所有人可以访问

重启ES

操作一下。
新建一个索引,初学的话,就把索引当做一个数据库,文档就当做库中的数据

这个head我们就把它当做展示数据的工具,我们后面的查询使用Kibana来做
了解ELK

安装Kibana
https://www.elastic.co/cn/downloads/kibana

Kibana要和ES版本一致才行
ELK基本都是拆箱即用的
解压后的目录:

直接启动



ES核心概念
- 索引 --》数据库
- 字段类型(mapping)
- 文档–》每一行数据
- 分片(lucene索引—》倒排索引)


文档:

类型:

索引:

上图是一个有3个节点的集群,可以看到主分片和对应的复制分片都不会在同一个节点上。实际上,一个分片是lucune索引,一个包含倒排索引的文件目录,倒排索引的结构使得ES在不扫描全部文档的情况下,就能告诉你哪些文档包含特定的关键字。所以,什么是倒排索引
倒排索引
ES使用的是一种称为倒排索引的结构,采用lucene倒排索引作为底层。这种结构适用于快速的全文搜索。一个索引由文档中所有不重复的列表构成,对于每一个词,都有一个包含它的文档列表。例如,现在有2个文档,每个文档包含不同的内容:

为了创建倒排索引,我们首先要将每个文档拆分成独立的词(或称为词条或者tokens),然后创建一个包含所有不重复的词条的排序列表,然后列出每个词条出现在哪个文档:

现在我们视图搜索 to forever,只需要查看包含每个词条的文档: score权重

两个文档都匹配,但是文档1比文档2的匹配度更高。若果没有其他条件,现在,这2个包含关键字的文档都将返回。
再看一个例子:

IK分词器插件

官网下载,解压到ES的plugins文件夹下

重启ES


使用Kibana测试

其中:
- ik_samrt:最少切分
- ik_max_word:为最细粒度划分,穷尽词库的可能
发现问题:李焕英被拆开了,这种自己需要的词,需要自己加到分词器的字典中
ik分词器增加自己的配置
找到配置文件所在目录,新建一个my.dic

添加自己的词
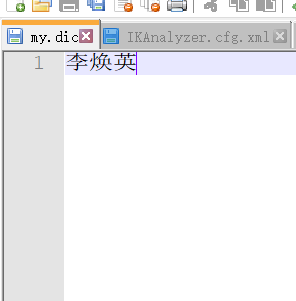
配置文件中加入自己的字典

重启ES

测试!

以后,我们需要自己配置分词,就在自己定义的dic文件中配合即可!
RestFul风格说明

关于索引的基本操作
利用kibana创建一个索引
PUT /索引名/类型名(未来可能会没有类型了)/文档id
{请求体}

完成了自动增加索引!数据也成功添加


指定字段类型

获得索引信息:通过GET请求

查看默认信息:如果文档字段没有指定,那么ES就会默认配置字段类型


修改文档的值:曾经的方法:利用PUT,直接覆盖

现在的修改方式:
POST/索引名/类型/文档id/_update

可以根据上面的Restful风格来进行测试…
关于文档的基本操作(重点)
- 基本操作
添加一条数据
PUT /pbp/user/1
{
“name”:“彭于晏”,
“age”: 18,
“tags”:[“努力”,“奋斗”],
“desc”: “帅气”
}

修改数据
简单的搜搜索

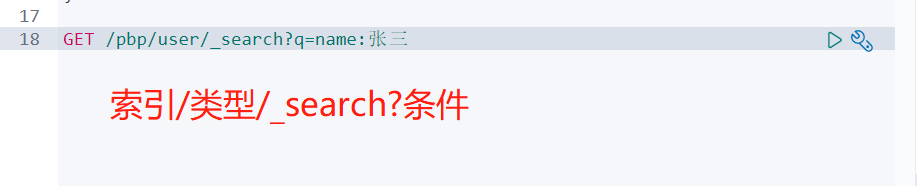
复杂的搜索查询 select(排序,分页,高亮,模糊查询,精准查询)
未来如果有多条查询出来的数据,那么这个score就是它的匹配度,匹配度越高分值越高

查询:
请求体{
参数体
}

模糊查询
多添加几条数据

hit:索引和文档的信息,查新的结果总数,查询出来的具体文档
max_score:最大权重值
source:这个文档的权重值、判断谁更符合结果
结果过滤
我不想遍历那么多结果出来怎么办?利用source结果过滤,列出你想要展示的字段

对结果进行排序
此处可以看到,因为排序了,max_sorce和sorce都为null

分页查询
from:从第几条数据开始
size:每页显示多少数据

多条件查询
must相当于mysql的and,所有条件都要符合

should相当于mysql的or

must_not相当于not,查询年龄不是30岁的人

过滤器

多条件查询,每个条件用空格隔开即可,只要满足其中一个就可以被查出,可以通过分值判断

分词
term查询是直接通过倒排索引指定的词条进程精确查询的!
关于分词:
- tern:直接查询精确的
- match:会使用分词器解析(先分析文档,然后在通过分析的文档进行查询)


接下来来试试查询desc。。。

居然没有查出东西,
这是因为keyword类型的要把它当做是一个整体,不会被分词器解析。
而text类型会被分词器解析

高亮查询
搜索的结果可以进行高亮显示,自动给你添加标签

我们还可以自定义高亮条件:

基于springboot
官网中找到文档



找依赖: 
找对象:

分析这个类中的方法即可。
源码的位置:

编写自己的配置文件
@Configuration
public class ESConfig {
@Bean
public RestHighLevelClient restHighLevelClient(){
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("localhost", 9200, "http")));
return client;
}
}
测试类:
判断是否有索引
/***
* 获取索引
* @throws IOException
*/
@Test
void testGetIndex() throws IOException {
GetIndexRequest request = new GetIndexRequest(indexName);
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
System.out.println(exists);
client.close();
}
创建索引
//PUT /pbp_index
@Test
void testCreatIndex() throws IOException {
//创建索引
CreateIndexRequest request = new CreateIndexRequest("pbp_index");
//客户端执行请求,请求后获得响应
CreateIndexResponse createIndexResponse = client.indices().create(request, RequestOptions.DEFAULT);
System.out.println(createIndexResponse);
client.close();
}
删除索引
/***
* 测试删除索引
* @throws IOException
*/
@Test
void testDeleteIndex() throws IOException {
DeleteIndexRequest request = new DeleteIndexRequest(indexName);
AcknowledgedResponse delete = client.indices().delete(request, RequestOptions.DEFAULT);
System.out.println(delete.isAcknowledged());
client.close();
}
测试添加文档
@Test
void testAddDocument() throws IOException {
//创建对象
User user = new User("pbp", 11);
//创建请求
IndexRequest request = new IndexRequest(indexName);
//设置规则 PUT /pbp_index/_doc/1
request.id("1");
request.timeout();
//将数据放入json
String s = JSON.toJSONString(user);
request.source(s, XContentType.JSON);
//客户端发送请求,获取响应结果
IndexResponse response = client.index(request, RequestOptions.DEFAULT);
System.out.println(response.getIndex());
System.out.println(response.status());
}
测试获取文档
//测试获取文档,先判断是否存在
@Test
void testExists() throws IOException {
//创建请求
GetRequest request = new GetRequest(indexName,"1");
//不获取返回的_source的上下文了
request.fetchSourceContext(FetchSourceContext.DO_NOT_FETCH_SOURCE);
request.storedFields("_none_");
boolean exists = client.exists(request,RequestOptions.DEFAULT);
System.out.println(exists);//存在则返回true
}
//测试获取文档
@Test
void testGetDocument() throws IOException {
//创建请求
GetRequest request = new GetRequest(indexName,"1");
GetResponse documentFields = client.get(request, RequestOptions.DEFAULT);
System.out.println(documentFields.getSourceAsString());//打印文档内容
System.out.println(documentFields);//返回全部的内容,和命令式的一样
}
更新文档信息
@Test
void testUpdateDocument() throws IOException {
//创建请求
UpdateRequest updateRequest = new UpdateRequest(indexName,"1");
updateRequest.timeout("1s");
User user = new User("aaa", 12);
//修改的参数,告诉它是Json格式
updateRequest.doc(JSON.toJSONString(user),XContentType.JSON);
//发送请求,
UpdateResponse update = client.update(updateRequest, RequestOptions.DEFAULT);
System.out.println(update);
}
删除文档
//删除文档
@Test
void testDelDocument() throws IOException {
DeleteRequest deleteRequest = new DeleteRequest(indexName);
deleteRequest.id("1");
DeleteResponse delete = client.delete(deleteRequest, RequestOptions.DEFAULT);
System.out.println(delete.status());
}
批量插入数据
里面还有批量删除,更新

//特殊的,批量插入数据
@Test
void testBulkDocument() throws IOException {
//创建请求
BulkRequest request = new BulkRequest();
request.timeout("20s");
List<User> userList = new ArrayList<>();
userList.add(new User("aaa",11));
userList.add(new User("bbb",22));
userList.add(new User("ccc",33));
userList.add(new User("ddd",44));
userList.add(new User("eee",55));
//将数据添加到IndexRequest中--->再将IndexRequest添加到BulkRequest请求中,
//批量更新和删除就在这里修改请求就行了
for (int i = 0; i < userList.size(); i++) {
request.add(new IndexRequest(indexName)
.source(JSON.toJSONString(userList.get(i)),XContentType.JSON));
}
BulkResponse responses = client.bulk(request, RequestOptions.DEFAULT);
System.out.println(responses.hasFailures());
}
查询
@Test
void testSearch() throws IOException {
SearchRequest request = new SearchRequest(indexName);
//创建搜索条件:高亮,排序,分页
SearchSourceBuilder builder = new SearchSourceBuilder();
//构建查询条件,可以使用QueryBuilders工具类
MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();
//将查询放入到搜索条件
builder.query(matchAllQueryBuilder);
builder.timeout(new TimeValue(60, TimeUnit.SECONDS));
request.source(builder);
SearchResponse search = client.search(request, RequestOptions.DEFAULT);
System.out.println(JSON.toJSONString(search.getHits()));
}
实战
- 爬虫
数据问题:数据库获取,消息队列获取,爬虫,都可以称为数据源
爬取数据:获取请求返回的页面信息,筛选出我们想要的数据!
jsoup包
从京东网站上搜索,然后从控制台可以看到,有一个id为J_goodsList的div

然后尝试获取这个id下的html
public class HtmlParseUtil {
public static void main(String[] args) throws Exception {
//获取请求 https://search.jd.com/Search?keyword=java
String url = "https://search.jd.com/Search?keyword=java";
//解析网页(Jsoup返回的对象就是浏览器Document对象,所有在js使用的方法,这里都能用)
Document document = Jsoup.parse(new URL(url), 30000);
Element element = document.getElementById("J_goodsList");
System.out.println(element.html());
}
}
经过测试没有问题:接下来可以看到前端下有许多li标签,里面就是我们需要的内容
接下来测试拿不拿得到数据
public class HtmlParseUtil {
public List<Object> parseJD(String keyWord) throws Exception {
//获取请求 https://search.jd.com/Search?keyword=java
String url = "https://search.jd.com/Search?keyword=" + keyWord;
//解析网页(Jsoup返回的对象就是浏览器Document对象,所有在js使用的方法,这里都能用)
Document document = Jsoup.parse(new URL(url), 30000);
Element element = document.getElementById("J_goodsList");
//获取所有的li元素
Elements elements = element.getElementsByTag("li");
//获取元素中的内容,这里的el就是每个li标签
for (Element el : elements) {
//获取img的第一个元素,src属性
//关于图片特别多的网站,所有图片都是延迟加载的,所以这里要获取data-lazy-img的值
String src = el.getElementsByTag("img").eq(0).attr("data-lazy-img");
String price = el.getElementsByClass("p-price").eq(0).text();
String name = el.getElementsByClass("p-name").eq(0).text();
}
}
}
发现可以拿到想要的名字,价格,图片,接下来创建一个实体类,把查出来的数据保存到实体,然后传到list中
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Content {
private String title;
private String price;
private String img;
}
最终的工具类代码:
@Component
public class HtmlParseUtil {
public List<Content> parseJD(String keyWord) throws Exception {
//获取请求 https://search.jd.com/Search?keyword=java
String url = "https://search.jd.com/Search?keyword=" + keyWord;
//解析网页(Jsoup返回的对象就是浏览器Document对象,所有在js使用的方法,这里都能用)
Document document = Jsoup.parse(new URL(url), 30000);
Element element = document.getElementById("J_goodsList");
//获取所有的li元素
Elements elements = element.getElementsByTag("li");
ArrayList<Content> goodList = new ArrayList<>();
//获取元素中的内容,这里的el就是每个li标签
for (Element el : elements) {
//获取img的第一个元素,src属性
//关于图片特别多的网站,所有图片都是延迟加载的
String src = el.getElementsByTag("img").eq(0).attr("data-lazy-img");
String price = el.getElementsByClass("p-price").eq(0).text();
String name = el.getElementsByClass("p-name").eq(0).text();
Content content = new Content();
content.setTitle(name);
content.setImg(src);
content.setPrice(price);
goodList.add(content);
}
return goodList;
}
}
开始写业务层的东西:
写写配置文件:
@Configuration
public class EsConfig {
@Bean
public RestHighLevelClient restHighLevelClient(){
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("localhost", 9200, "http")));
return client;
}
}
service:将遍历出来的数据,写入es中
@Service
public class ContentService {
public static void main(String[] args) throws Exception {
boolean java = new ContentService().parseContent("java");
}
@Autowired
private RestHighLevelClient restHighLevelClient;
//解析数据,放入es索引中
public boolean parseContent(String keyWord) throws Exception {
List<Content> contents = new HtmlParseUtil().parseJD(keyWord);
//把查询的数据批量放入es中
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.timeout("2m");
for (int i = 0; i < contents.size(); i++) {
IndexRequest request = new IndexRequest("jd_goods");
request.source(JSON.toJSONString(contents.get(i)), XContentType.JSON);
bulkRequest.add(request);
}
BulkResponse bulk = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
return !bulk.hasFailures();
}
}
controller:
@RestController
public class ContentController {
@Autowired
private ContentService contentService;
@GetMapping("/parse/{keyWord}")
public boolean parse(@PathVariable("keyWord") String keyWord) throws Exception {
return contentService.parseContent(keyWord);
}
}

service:获取这些数据,实现搜索功能
public List<Map<String,Object>> searchPage(String keyWord,int pageNo,int pageSize) throws IOException {
if(pageNo<=1){
pageNo = 1;
}
//条件搜索
SearchRequest request = new SearchRequest("jd_goods");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//分页
sourceBuilder.from(pageNo);
sourceBuilder.size(pageSize);
//精准查询
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("title",keyWord);
sourceBuilder.query(termQueryBuilder);
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
//执行搜索
request.source(sourceBuilder);
SearchResponse search = restHighLevelClient.search(request, RequestOptions.DEFAULT);
List<Map<String,Object>> list = new ArrayList<>();
//解析结果
for (SearchHit hit : search.getHits().getHits()) {
list.add(hit.getSourceAsMap());
}
return list;
}
}
controller:
@GetMapping("/search/{keyName}/{pageNo}/{pageSize}")
public List<Map<String,Object>> search(@PathVariable("keyName") String keyName,
@PathVariable("pageNo") int pageNo,
@PathVariable("pageSize") int pageSize) throws IOException {
return contentService.searchPage(keyName,pageNo,pageSize);
}
结果:
我们先在有后台的接口了,前端页面也有了。现在进行前后端交互!
- 前后端分离
新建文件夹,在文件夹下按出命令行窗口,初始化 :npm init
安装vue

安装axios

将对应的js拉入项目:

HTML导入js文件

- 搜索高亮
业务层代码修改如下,显示高亮:
public List<Map<String,Object>> searchPage(String keyWord,int pageNo,int pageSize) throws IOException {
if(pageNo<=1){
pageNo = 1;
}
//条件搜索
SearchRequest request = new SearchRequest("jd_goods");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//分页
sourceBuilder.from(pageNo);
sourceBuilder.size(pageSize);
//精准查询
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("title",keyWord);
sourceBuilder.query(termQueryBuilder);
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
//高亮
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("title");//需要哪个字段高亮?
highlightBuilder.preTags("<span style='color:red'>");//对应字段的前面的标签
highlightBuilder.postTags("</span>");
highlightBuilder.requireFieldMatch(false);//多个高亮关闭
sourceBuilder.highlighter(highlightBuilder);
//执行搜索
request.source(sourceBuilder);
SearchResponse search = restHighLevelClient.search(request, RequestOptions.DEFAULT);
List<Map<String,Object>> list = new ArrayList<>();
//解析结果
for (SearchHit hit : search.getHits().getHits()) {
//解析高亮字段
Map<String, HighlightField> highlightFields = hit.getHighlightFields();//获取到高亮字段
HighlightField title = highlightFields.get("title");//获取所有的标题出来
Map<String, Object> sourceAsMap = hit.getSourceAsMap();//原来的结果
//开始解析字段,将原来的字段替换成为我们的高亮字段即可
if(title!=null){
Text[] fragments = title.fragments();//如果原来的字段存在,那就取出来
String n_title = "";
for(Text text : fragments){
n_title += title;
}
sourceAsMap.put("title",n_title);
}
list.add(hit.getSourceAsMap());
}
return list;
}

前端已经有span标签了,只需要利用vue进行解析















 770
770











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









