







1.1统计学习
统计学习方法由监督学习(supervised learning)、非监督学习(unsupervised learning)、半监督学习(semi-supervised learning)和强化学习(reinforcement learning)等组成。
其中监督学习的实现步骤:
①得到一个有限的训练集合。
②得到模型的假设空间。
③确定模型的选择准则,即学习策略。
④实现求解最优模型的算法。
⑤通过学习方法选择最优模型。
⑥利用学习的最优模型对新数据进行预测或者分析。
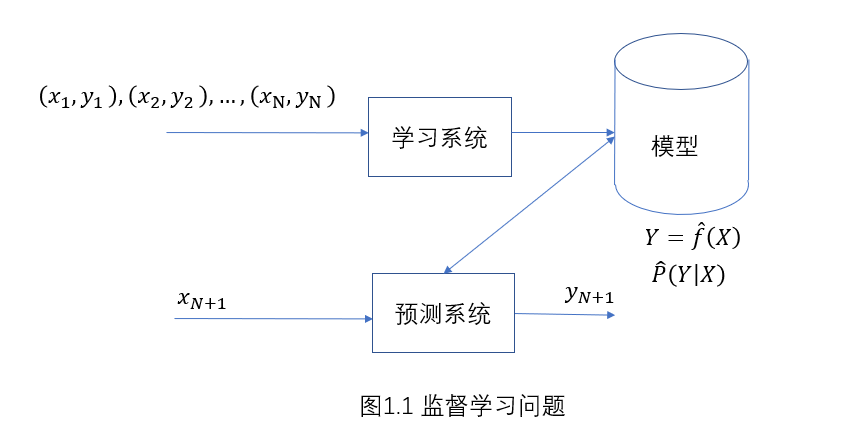
1.2监督学习
训练集:
T
=
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
.
.
.
,
(
x
N
,
y
N
)
T = {(x_1,y_1),(x_2,y_2),...,(x_N,y_N)}
T=(x1,y1),(x2,y2),...,(xN,yN)
实例
x
x
x的特征向量:
x
=
(
x
(
1
)
,
x
(
2
)
,
.
.
.
,
x
(
n
)
)
T
x = (x^ {(1)},x^ {(2)},...,x^ {(n)})^T
x=(x(1),x(2),...,x(n))T
模型:
1)决策函数
Y
=
f
(
X
)
Y = f(X)
Y=f(X)
预测形式
y
=
f
(
x
)
y = f(x)
y=f(x)
2)条件概率分布;
P
(
Y
∣
X
)
P(Y|X)
P(Y∣X)
预测形式
a
r
g
m
a
x
P
(
y
∣
x
)
argmax P(y|x)
argmaxP(y∣x)
1.3监督学习三要素
模型(model)
策略(strategy)
算法(algorithm)
1.3.1模型(假设空间):
决策函数
F
=
{
f
∣
Y
=
f
θ
(
X
)
,
θ
∈
R
n
}
F = \lbrace{f|Y=f_\theta(X),\theta\in{R^n}}\rbrace
F={f∣Y=fθ(X),θ∈Rn}
条件概率分布
F
=
{
P
∣
P
θ
(
Y
∣
X
)
,
θ
∈
R
n
}
F = \lbrace{P|P_\theta(Y|X),\theta\in{R^n}}\rbrace
F={P∣Pθ(Y∣X),θ∈Rn}
1.3.2策略
常见损失函数:
L
(
Y
,
f
(
X
)
)
=
{
1
,
Y
≠
f
(
X
)
0
,
Y
=
f
(
X
)
L(Y,f(X)) = \left\{\begin{aligned} 1 &,&Y \neq f(X)\\ 0 &, &Y = f(X) \end{aligned} \right.
L(Y,f(X))={10,,Y̸=f(X)Y=f(X)
L
(
Y
,
f
(
X
)
)
=
(
Y
−
f
(
X
)
)
2
L(Y,f(X)) =(Y-f(X))^2
L(Y,f(X))=(Y−f(X))2
L
(
Y
,
f
(
X
)
)
=
∣
Y
−
f
(
X
)
∣
L(Y,f(X)) = |Y-f(X)|
L(Y,f(X))=∣Y−f(X)∣
L
(
Y
,
P
(
Y
∣
X
)
=
log
(
P
(
Y
∣
X
)
)
L(Y,P(Y|X)=\log(P(Y|X))
L(Y,P(Y∣X)=log(P(Y∣X))
经验风险最小化:
m
i
n
(
f
∈
F
)
1
N
∑
i
=
1
N
L
(
y
i
,
f
(
x
i
)
)
{min\\({f\in F})} \frac{1}{N}\sum_{i=1}^{N}L(y_i,f(x_i))
min(f∈F)N1i=1∑NL(yi,f(xi))
结构风险最小化:
m
i
n
(
f
∈
F
)
1
N
∑
i
=
1
N
L
(
y
i
,
f
(
x
i
)
)
+
λ
J
(
f
)
min(f\in F) \frac{1}{N}\sum_{i=1}^{N}L(y_i,f(x_i))+\lambda J(f)
min(f∈F)N1i=1∑NL(yi,f(xi))+λJ(f)
1.3.3算法
1.4模型评估和模型选择
训练误差
1
N
∑
i
=
1
N
L
(
y
i
,
f
^
(
x
i
)
)
\frac{1}{N}\sum_{i=1}^{N}L(y_i,\hat{f} (x_i))
N1i=1∑NL(yi,f^(xi))
测试误差
1
N
′
∑
i
=
1
N
′
L
(
y
i
,
f
^
(
x
i
)
)
\frac{1}{N\prime}\sum_{i=1}^{N\prime}L(y_i,\hat{f} (x_i))
N′1i=1∑N′L(yi,f^(xi))
Markdown码公式真心累~o(╥﹏╥)o














 335
335











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









