






论文主要内容
论文参考文献
电子商务推荐算法的挑战:
- 数据量大
- 需要高质量实时推荐
- 新用户冷启动问题(同时,客户数据也不稳定)
三种常用解决方法:
- 传统的协同过滤
- 聚类模型
- 基于搜索的方法
文章提出:商品到商品的协同过滤(Item-to-Item Collaborative Filter)
传统的协同过滤
- 将客户表示为商品的N维向量,其中N是不同目录下商品的数量。购买或肯定评级的商品,向量分量为正,对于负面评级的商品,向量分量为负。补偿畅销商品,该算法通常将向量分量乘以反转频率(购买或评价该商品的客户数量的倒数)
- 常用的相似度计算方法:
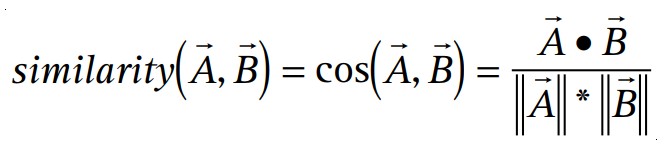
- 从相似客户的商品中选择推荐,也可以根据购买的相似客户的数量对每种商品进行排序
- 缺点:使用协同过滤来生成推荐的计算代价很高矩阵极其稀疏,性能和可伸缩问题较大
- 通过它使用降维、采样或划分,客户与用户的相似性都会降低,从而降低推荐质量。
聚类模型
- 将客户库划分为多个细分,并将寻找与用户相似的客户视为一个分类问题。该算法的目标是将用户分配到包含最相似客户的细分人群。然后,它使用细分人群中客户的购买和评级来生成推荐。
- 通常是使用聚类或其他无监督学习算法来创建的
- 在大型数据集上进行最佳聚类是不切实际的,大多数应用使用各种形式的贪婪聚类生成
- 与协同过滤相比,聚类模型具有更好的在线可扩展性和性能
- 缺点:复杂而昂贵,推荐质量不高
基于搜索的方法
- 将推荐问题视为搜索相关商品,给定用户购买和评级的物品,构建搜索查询以查找相同作者、艺术家或导演的其他流行物品
- 如果用户购买或评分很少,基于搜索的推荐算法规模和性能都很好,购买商品数量较多的用户,需要使用数据子集,这会降低推荐质量
- 对于大量购买和评级的客户,它们的可扩展性也很差
商品到商品的协同过滤
-
不是将用户与相似客户匹配,而是将用户购买和评级的每个商品与相似商品进行匹配,然后将这些相似商品组合到推荐列表中。

-
给定一个相似商品表,该算法查找与用户的每个购买和评级相似的商品,聚合这些商品,然后推荐最受欢迎或相关的商品。此计算非常快速,仅取决于用户购买或评级的商品数量。 可以扩展到海量数据集,并实时产生高质量的推荐。
-
离线计算花费大的物品相似度矩阵,在线部分只为用户购买或评分的物品寻找其相似的物品,这部分的计算与用户数量和物品数量无关,只与用户购买或者评价的物品数量有关。所以,即使在超大数据集上速度依然很快。因为推荐了相似度(相关性)很大的物品,推荐质量也很好。与传统的C协同过滤不同,在有限的用户数据集上表现也很好,可以基于用户购买的两三个物品提供高质量推荐(用户冷启动)。
原文翻译
推荐算法以其在电子商务网站上的使用而为人所知,在这些网站上,它们利用关于客户兴趣的输入来生成推荐商品的列表。许多应用只使用客户购买并明确评分的商品来表示他们的兴趣,但它们也可以使用其他属性,包括浏览的商品、人口统计数据、主题兴趣和最喜欢的艺术家.
在Amazon.com,我们使用推荐算法为每个客户提供在线商店个性化。这家商店根据顾客的兴趣进行了本质性的改变,向软件工程师展示编程类标题,向新妈妈展示婴儿玩具。点击率和转换率——基于网络和邮件广告有效性的两个重要衡量标准——远远超过横幅广告和畅销排行榜等无针对性内容的点击率和转换率。 电子商务推荐算法通常运行在具有挑战性的环境中。例如:
- 大型零售商可能拥有海量数据、数千万客户和数百万种不同的目录商品。
- 许多应用要求在不超过半秒的时间内实时返回结果集,同时仍能生成高质量的推荐。
- 从新用户那获得的信息极其有限,仅基于少量购买或产品评级。
- 基于数以千计的购买和评级,年长的客户可能会有更多的信息。
- 客户数据是不稳定的:每次交互都提供有价值的客户数据,算法必须立即响应新信息。
有三种常用的方法来解决推荐问题:传统的协同过滤、聚类模型和基于搜索的方法。在这里,我们将这些方法与我们的算法进行比较,我们称之为商品到商品的协同过滤(Item-to-Item Collaborative Filter)。与传统的协同过滤不同,我们算法的在线计算规模独立于客户数量和产品目录中的商品数量。我们的算法实时生成推荐,可扩展到海量数据集,并生成高质量的推荐。
推荐算法
大多数推荐算法都是从找到一组客户开始的,这些客户的购买和商品评级与用户购买和评级的商品重叠。该算法聚集来自这些相似客户的商品,剔除用户已经购买或评级的商品,并向用户推荐剩余的商品。这些算法的两个流行版本是协同过滤和聚类模型。其他算法——包括基于搜索的方法和我们自己的商品到商品协同过滤——专注于寻找相似的商品,而不是相似的客户。对于用户购买和评级的每个商品,算法尝试查找相似的商品。然后,它将相似的商品聚集起来并进行推荐。
传统的协同过滤
传统的协同过滤算法将客户表示为商品的N维向量,其中N是不同目录下商品的数量。对于购买或肯定评级的商品,向量的分量为正,对于负面评级的商品,向量的分量为负。为了补偿畅销商品,该算法通常将向量分量乘以反转频率(购买或评价该商品的客户数量的倒数),从而使不太知名的商品更加相关。对于几乎所有客户,此向量都非常稀疏。该算法基于与用户最相似的几个客户生成推荐。它可以用多种方式衡量两个客户A和B的相似度;常用的方法是测量两个矢量之间的角度的余弦:
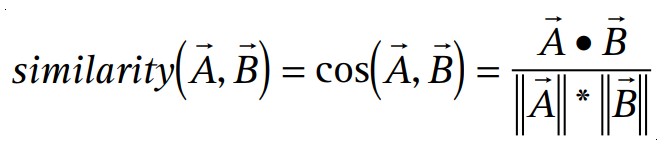
该算法还可以使用各种方法从相似客户的商品中选择推荐,一种常见的技术是根据购买的相似客户的数量对每种商品进行排序。使用协同过滤来生成推荐的计算代价很高。在最坏的情况下,它是O(MN),其中M是客户数量,N是产品目录商品的数量,因为它考察M个客户,每个客户最多计算N个商品。然而,由于平均客户向量是极其稀疏的,算法的性能趋向于更接近于O(M+N)。扫描每个客户大约是O(M),而不是O(MN),因为几乎所有的客户向量都包含少量的商品,无论目录的大小如何。但也有少数客户购买或评定了相当大比例的目录,需要O(N)个处理时间。因此,该算法的最终性能约为O(M+N)。即便如此,对于非常大的数据集——例如1000万或更多客户和100万或更多目录商品——算法仍会遇到严重的性能和可伸缩性问题。
可以通过减小数据规模来部分解决这些扩展问题。我们可以通过对顾客随机抽样或丢弃购买较少的顾客来减少M,通过丢弃非常受欢迎或不受欢迎的商品来减少N。还可以通过基于产品类别或主题分类来划分商品空间,以较小的恒定因子来减少检查的商品的数量。聚类和主成分分析等降维技术可以大幅降低M或N。
不幸的是,所有这些方法也在几个方面降低了推荐质量。首先,如果算法只检查一小部分客户样本,则所选客户与用户的相似性会降低。其次,商品空间划分将推荐限制在特定的产品或主题领域。第三,如果算法丢弃了最受欢迎或不受欢迎的商品,它们将永远不会出现在推荐中,并且只购买了这些商品的客户将得不到推荐。应用于商品空间的降维技术通过消除低频商品往往具有相同的效果。应用于客户空间的降维有效地将相似的客户分组到聚类中;正如我们现在描述的那样,这样的聚类也会降低推荐质量。
聚类模型
为了找到与用户相似的客户,聚类模型将客户库划分为多个细分,并将任务视为一个分类问题。该算法的目标是将用户分配到包含最相似客户的细分人群。然后,它使用细分人群中客户的购买和评级来生成推荐。
这些分段通常是使用聚类或其他无监督学习算法来创建的,尽管一些应用使用手动确定的分段。使用相似性度量,群集算法将最相似的客户分组在一起以形成群集或细分。因为在大型数据集上进行最佳聚类是不切实际的,所以大多数应用程序使用各种形式的贪婪聚类生成。这些算法通常从一组初始细分人群开始,每个细分人群通常包含一个随机选择的客户。然后,他们反复将客户与现有细分人群相匹配,通常会提供一些用于创建新细分人群或合并现有细分人群的规定。对于非常大的数据集——尤其是高维的数据集——采样或降维也是必要的。
一旦算法生成了片段,它就会计算用户与汇总每个片段的向量的相似度,然后选择相似度最高的片段,并相应地对用户进行分类。一些算法将用户分类为多个细分人群,并描述每个关系的强度。
与协同过滤相比,聚类模型具有更好的在线可扩展性和性能,因为它们将用户与受控数量的细分人群(而不是整个客户)进行比较。复杂而昂贵的聚类计算是离线运行的。然而,推荐质量不高。
聚类模型将多个客户组合在一个细分人群中,将一个用户与一个细分人群相匹配,然后将该细分人群中的所有客户视为相似的客户,以便作出推荐。因为聚类模型找到的相似客户不是最相似的客户,所以它们生成的推荐相关性较小。可以通过使用大量细粒度划分来提高质量,但是这样在线用户细分分类就会变得几乎与使用协同过滤寻找相似客户一样昂贵。
基于搜索的方法
基于搜索或基于内容的方法将推荐问题视为搜索相关商品。给定用户购买和评级的物品,该算法构建搜索查询以查找相同作者、艺术家或导演的其他流行物品,或者具有相似的关键字或主题的其他流行物品。例如,如果客户购买了教父DVD收藏,系统可能会推荐其他犯罪剧标题,马龙·白兰度主演的其他标题,或弗朗西斯·福特·科波拉执导的其他电影。
如果用户购买或评分很少,基于搜索的推荐算法规模和性能都很好。然而,对于购买了数千件商品的用户来说,基于所有商品进行查询是不切实际的。算法必须使用数据的子集或摘要,这会降低质量。在所有情况下,推荐质量都相对较差。
在所有情况下,推荐质量都相对较差。推荐通常要么过于笼统(比如畅销电视剧DVD标题),要么过于狭隘(比如同一作者的所有书籍)。推荐应该帮助客户找到和发现新的、相关的和有趣的商品。由同一作者或同一主题类别的热门文章无法实现这一目标。
商品到商品的协同过滤
Amazon.com在许多电子邮件活动和大多数网站页面(包括高流量的Amazon.com主页)中使用推荐作为有针对性的营销工具。点击“您的推荐”链接,客户可以进入一个区域,在这里他们可以按产品线和主题区域过滤推荐,对推荐的产品进行评级,对他们以前购买的产品进行评级,并查看为什么商品被推荐。

我们的购物车推荐根据客户购物车中的商品向客户提供产品建议。该功能类似于超市结账队列中的冲动物品,但我们的冲动物品是针对每个顾客的。

Amazon.com广泛使用推荐算法来使其网站个性化,以满足每个客户的兴趣。由于现有的推荐算法无法扩展到Amazon.com的数千万客户和产品,我们开发了自己的推荐算法。我们的算法,商品到商品的协同过滤,可以扩展到海量数据集,并实时产生高质量的推荐。
如何运作
不是将用户与相似客户匹配,而是商品到商品协同过滤将用户购买和评级的每个项与相似项进行匹配,然后将这些相似项组合到推荐列表中。
为了确定给定商品的最相似匹配,该算法通过查找客户倾向于一起购买的商品来构建相似商品表。我们可以通过迭代所有商品对并计算每个商品对的相似性度量来构建产品到产品矩阵。然而,许多产品对没有共同的客户,因此该方法在处理时间和内存使用方面效率低下。以下迭代算法通过计算单个产品与所有相关产品之间的相似度提供了一种更好的方法:

可以通过各种方式计算两个商品之间的相似度,但一种常见的方法是使用我们前面描述的余弦度量,其中每个向量对应于一个商品而不是一个客户,向量的M维对应于购买了该商品的客户。
相似商品表格的这种离线计算非常耗时,O(N2M)是最坏的情况。然而,在实践中,它更接近O(NM),因为大多数客户的购买量很少。对购买畅销书的客户进行抽样,在质量几乎没有降低的情况下,甚至可以进一步缩短运行时间。
给定一个相似商品表,该算法查找与用户的每个购买和评级相似的商品,聚合这些商品,然后推荐最受欢迎或相关的商品。此计算非常快速,仅取决于用户购买或评级的商品数量。
可扩展性:比较
Amazon.com拥有超过2900万客户和数百万个目录商品。其他主要零售商拥有相对较大的数据源。虽然所有这些数据都提供了机会,但它也是一种诅咒,远远突破了那些针对小三个数量级的数据集所设计的算法的限度。几乎所有现有的算法都是在小数据集上进行评估的。例如,MovieLens数据集4包含35000个客户和3000个商品,而EachMovie数据集3包含4000个客户和1600个商品。
对于非常大的数据集,可伸缩的推荐算法必须离线执行最昂贵的计算。简单比较一下,现有的方法都有不足之处:
传统的协同过滤很少或根本不进行离线计算,其在线计算会随着客户数量和目录商品的增加而扩展。该算法在大数据集上是不切实际的,除非它使用降维、采样或划分——所有这些都会降低推荐质量。
聚类模型可以离线执行大部分计算,但推荐质量相对较差。要改善这一点,可以增加细分人群的数量,但这会使在线用户-细分人群分类变得昂贵。
基于搜索的模型离线构建关键字、类别和作者索引,但无法提供具有有趣的、有针对性的标题的推荐。对于大量购买和评级的客户,它们的可扩展性也很差。
商品到商品协同过滤的可伸缩性和性能的关键在于它离线创建昂贵的相似项表。该算法的在线部分——查找用户购买和评级的类似商品——独立于目录大小或客户总数进行缩放;它仅取决于用户购买或评级的图书数量。因此,即使对于非常大的数据集,该算法也是快速的。由于该算法推荐相关度高的相似项,因此推荐质量很好。与传统的协同过滤不同,该算法在有限的用户数据下也能很好地执行,仅基于两三个商品就能产生高质量的推荐。
结论
通过为每位顾客建立个性化的购物体验,推荐算法提供了一种有效的定向营销形式。对于像Amazon.com这样的大型零售商来说,一个好的推荐算法可以在非常大的客户群和产品目录上扩展,只需要亚秒级的处理时间就可以生成在线推荐,能够立即对用户数据的更改做出反应,并为所有用户提供有说服力的推荐,而不考虑购买数量和评级。与其他算法不同,商品到商品协同过滤能够应对这一挑战。
未来,我们预计零售业将更广泛地将推荐算法应用于线上和线下的定向营销。虽然电子商务企业拥有最容易的个性化工具,但与传统的大规模方法相比,这项技术的转换率提高了,这也将使其对线下零售商具有吸引力,用于邮政邮件、优惠券和其他形式的客户沟通。
参考文献
[1] J.B. Schafer, J.A. Konstan, and J. Reidl, “E-Commerce Recommendation Applications,” Data Mining and Knowledge Discovery, Kluwer Academic, 2001, pp. 115-153.
[3] J. Breese, D. Heckerman, and C. Kadie, “Empirical Analysis of Predictive Algorithms for Collaborative Filtering,” Proc. 14th Conf. Uncertainty in Artificial Intelligence, Morgan Kaufmann, 1998, pp. 43-52.
[4] B.M. Sarwarm et al., “Analysis of Recommendation Algorithms for E-Commerce,” ACM Conf. Electronic Commerce, ACM Press, 2000, pp.158-167.
[5] K. Goldberg et al., “Eigentaste: A Constant Time Collaborative Filtering Algorithm,” Information Retrieval J., vol. 4, no. 2, July 2001, pp. 133-151.
[8] M. Balabanovic and Y. Shoham, “Content-Based Collaborative Recommendation,” Comm. ACM, Mar. 1997, pp. 66-72.
[9] G.D. Linden, J.A. Jacobi, and E.A. Benson, Collaborative Recommendations Using Item-to-Item Similarity Mappings, US Patent 6,266,649 (to Amazon.com), Patent and Trademark Office, Washington, D.C., 2001.
[10] B.M. Sarwar et al., “Item-Based Collaborative Filtering Recommendation Algorithms,” 10th Int’l World Wide Web Conference, ACM Press, 2001, pp. 285-295.















 3190
3190











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









