







这篇主要介绍Object Detection一些经典的网络结构。顺序是RCNN->SPP->Fast RCNN->Faster RCNN->YOLO->SSD->YOLO2->Mask RCNN。这里只粗糙地介绍网络构型变化。更多细节强烈推荐阅读原文。
1. RCNN
核心思想包含在这幅图中:早期思想的典型代表,分段式处理每一个环节,输入图像首先使用selective search之类的方法选出2000个大小不一、形状多样的region proposals,统一缩放到指定尺寸(warp,这就是个很大的问题,另一种操作是crop,这些操作会让图像扭曲或不完整),对这些图片使用CNN提取特征然后分类。
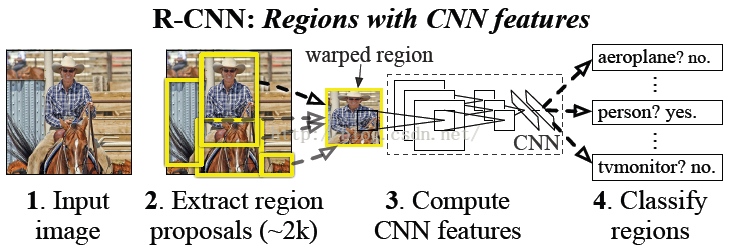
2.SPP-net
SPP的全称是Spatial Pyramid Pooling,意思很直观,主要为了解决RCNN的那个缩放问题。思路也是比较巧妙:
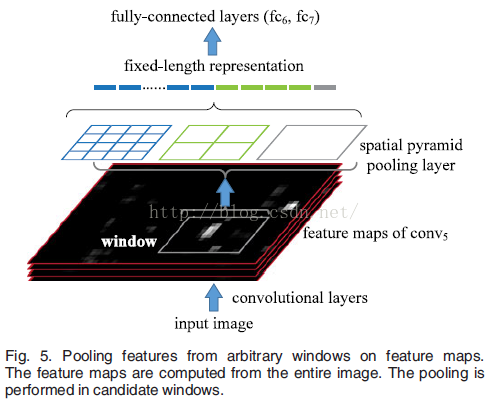
首先考虑为什么RCNN要把图像规整为固定大小?因为后边的全连接层是固定的,而前边的卷积层会因为图片尺寸不一致,输出尺寸也不一样,和全连接层就接不上了。那就只对region proposals映射在的feature map的区域做pooling(也就是图中的window中做pooling),这个区域定了之后做SPP,与一般的pooling不一样的是:一般的pooling是规定好的receptive field,SPP是先定“需要几个卷积滤波器”,然后计算receptive field的尺寸,每层都这样,然后就获得了固定尺寸的输出,然后就与通常的全连接层接上了。并且SPP分享了不同region proposals的权值,只需要做一次前向卷积,所以比RCNN很省时间。
3. Fast RCNN
SPP与RCNN的底层一样:都是必须使用selective search之类的方法先选出一些区域再谈后续的处理。而selective search之类的方法不是很给力,主要是速度慢,于是Fast RCNN就考虑抛开这一步。
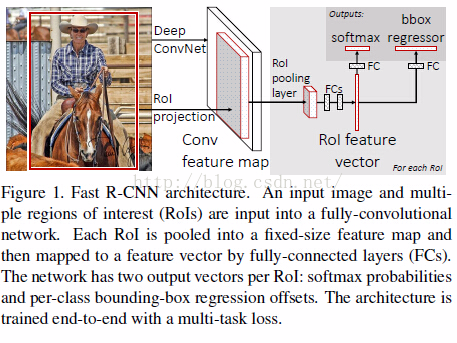
如图所示,FRCNN训练的时候输入是image和ground truth bounding boxs,经过常规的CNN到feature map层并且b-box会有对应的区域,对这个区域也是用SPP类似的处理(只有单个尺度的SPP,文中起名字ROI pooling),这之后就把特征映射为固定尺寸,然后就可以正常连接全连接层了!经过全连接层,直接分为两路执行多目标训练,一路是模仿分类,另一路是模仿b-box的位置,作者精心设计了loss函数。
4. Faster RCNN
Fast RCNN和SPP在feature maps上的处理本质相同:都需要根据输出结果重新计算一个合适receptive field,对硬件来说不是一个固定尺寸的数据流,速度打折扣。Faster RCNN提出了一种新的多尺度方法:
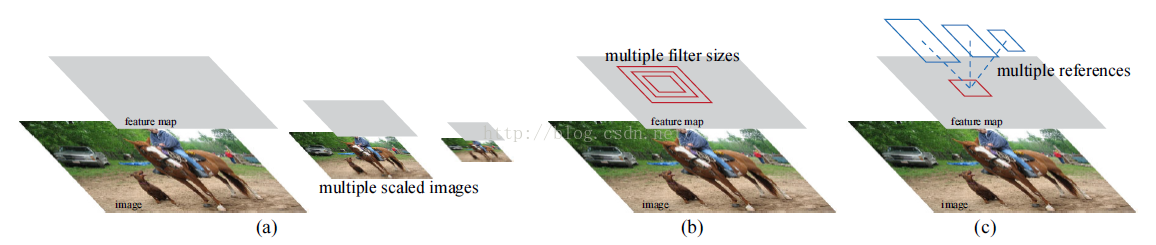
一般的多尺度是缩放图像(a),SPP的类的多尺度是改变receptive field(b),这个新的多尺度(c)是:在feature maps上规定几个不同形状的框(anchor box),这些框反射会图像中是有固定尺寸大小的,达到多尺度的目的。于是Faster RCNN的主要思路:
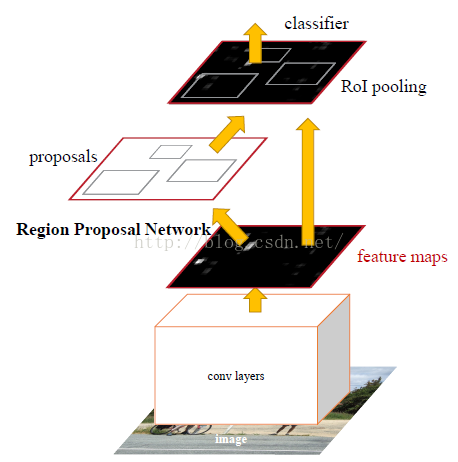
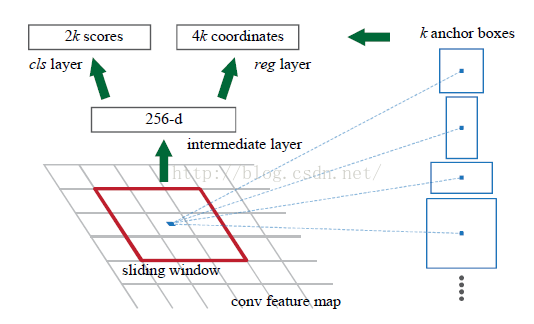
首先是一个region proposal单独判断的旁路(左图),常规的CNN后在feature map上加全连接层(中图),针对每个anchor box都评价对应图片中有无物体以及预测b-box的坐标是什么,当然需要设计精良的loss函数,把分类问题和位置判断全变成回归问题。后续的分类旁路就是和Fast R-CNN一样了。另外基础的网络都是使用现有的VGG16、ZF等,只是微调。
5. YOLO
这个名字很有意思(You Only Look Once),这个方法更加暴力。直接使用离散化思想:一个图片中的物体不会很多,把图片分成有限个数的格子,物体中心会落到某一个格子中,这个格子对这个物体负责即可,直接在格子的基础上映射出物体的分类和位置,非常的end-to-end。示意图如下:
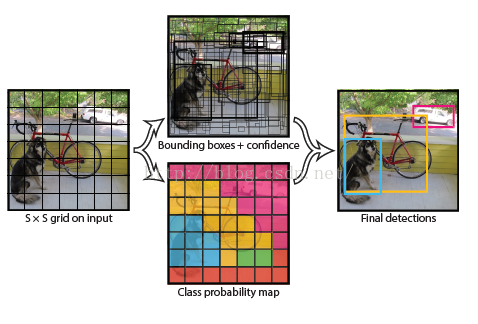
具体的网络如下:

最后的输出直接对应图片的格子,每个格子有30维度的信息:20个是分类评分,另外10个预测两个潜在的b-box的位置和置信度,每个5维度。如此的端到端、多任务的学习,loss函数当然需要更加仔细斟酌,如下

6. SSD
YOLO的速度可以非常快,但是对小物体的精度不佳,SSD结合了YOLO网格离散化的思想和Faster RCNN固定框的思想,增加了在多尺度feature map上映射特征的能力,结构如下:
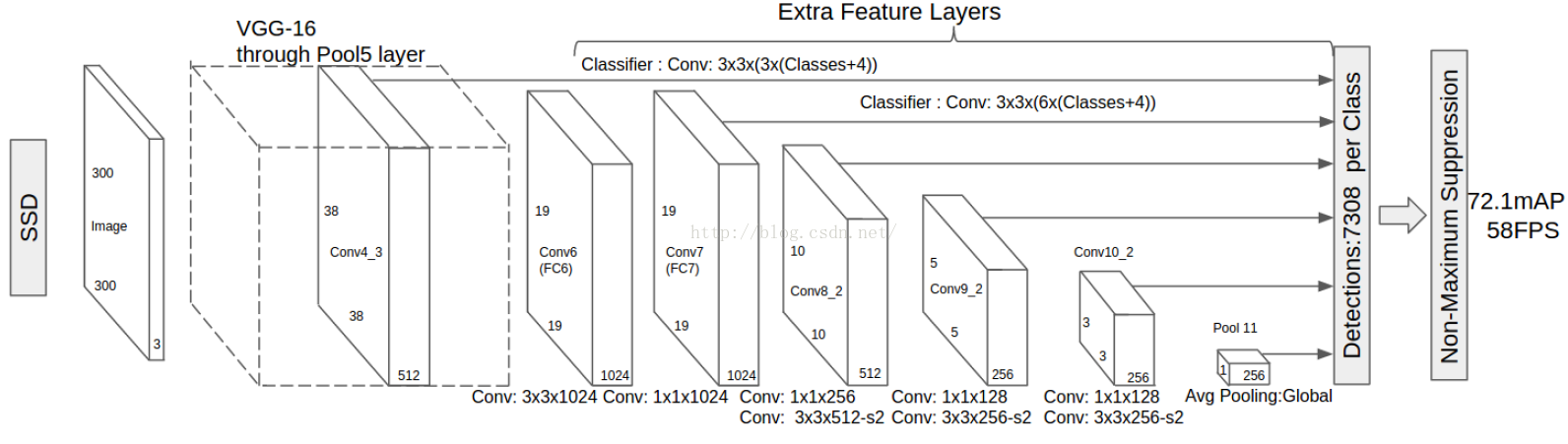
也是端到端,但是从中间层抽取了很多特征(类似多尺度),使用小的卷积模板直接预测规定box中物体的分类和位置,初步预测中会产生非常多的潜在目标,经过非极大值抑制处理后,输出最后的结果。从底层映射的特征增强了分辨小物体的能力。
7.YOLO2
从名字来看,很明显是在YOLO基础上改进获得的。
最主要的改进是:
1)把YOLO中的直接b-box位置预测改成了Faster R-CNN中的anchor box;
2)把原图尺寸改成416=32*13,这样就有个中间cell,对应于大物体的box,
3)把直接坐标预测改成了预测每个cell对应的5个anchor box的offset(这样更训练更稳定了),并把分类预测与anchor box绑定
4)最终cell也从7*7增加到13*13,并且借鉴ResNet,从倒数第二阶feature map层中添加了直接映射用于后续的计算,有助于提高小物体的检测能力。
其中比较重要的一点是作者认为anchor box 的尺寸有更好的选择,于是就把样本库中的所有b-box的尺寸做了统计,使用k-means找出最合适的一簇框,最终选择了5个类型。另一个重要表示是offset的形式,表示了一个anchor box在一个cell中的位置计算。


一个经典的工作原理示意图:

作者为了强调YOLO2的实时性,直接检测《007》中的各种物体(视频)。
8. Mask R-CNN
从结构上看,这个可以看做是在Faster RCNN上加了一个“头”:原先的只有分类和b-box回归两个“头”,现在加了个mask(用于像素分割的),这样就把上述的物体检测功能与分割融合在了一起。因为这两种工作都需要使用庞大的基础层提取特征,融合后在任务级别上有提升了速度。
先看一下结构:上图是整体结构,下图是添加的“头”(两种基础网络,两种头)


主要改进点:
1)基础网络的增强,ResNet和FPN
2)把一直使用的ROIpooling改成了ROIAlign:因为ROIpooling是一种有损失的变形,而在高层feature maps上损失一个“像素”,反映到底层图片上那就很大了。而ROIAlign使用了双线性插值(bilinear interpolation)解决这个问题,对最终效果有提升。
3)把mask单独作为一个头,每个类都有一个对应的mask(一个类占用最终feature map一个channel),这样就避免了分割问题中“类间竞争”
References:
1.Rich feature hierarchies for accurate object detection and semantic segmentation,2014,cvpr
2.Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition,2015,IEEE T PATTERN ANAL
3.Fast R-CNN,2015,iccv
4.Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks,2015,nips
5.You Only Look Once : Unified, Real-Time Object Detection,2016,cvpr
6.SSD: Single Shot MultiBox Detector,2016,eccv
7.YOLO9000:Better, Faster, Stronger,2016,arxiv
8.Mask R-CNN,2017,arxiv















 845
845

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









