







项目使用软件:Eclipse Mars,JDK1.7,Hadoop2.6,MySQL5.6,EasyUI1.3.6,jQuery2.0,Spring4.1.3,
Hibernate4.3.1,struts2.3.1,Tomcat7 ,Maven3.2.1。本项目是在参考fansy1990大神的两篇博客基础上完成的
http://blog.csdn.net/fansy1990/article/details/46943657
http://blog.csdn.net/fansy1990/article/details/47751747
我的目的是有个网上商城,里面有很多商品,某个用户在浏览一些商品后系统根据用户的浏览记录再结合其它广大用户的偏好记录,应用基于物品的协同过滤算法,为这个用户推荐合乎情理的其它商品,目的在于加深对算法的理解及更直观的展示算法的成果。
经过我前几篇博客的介绍,已经有网上商城了,为了和hadoop项目做整合已将Hibernate由3升级到4版本,既然是基于物品也为商城注入了十多个分类近三千件商品了,对于实验案例也足够了,算法及落地也选好了--直接调用Mahout中的itemcf算法, 还剩个一个问题就是没有用户的对商品的偏好记录,这个数据网上肯定是抓取不到的,也不合法规,那怎么办不能死在最后一步上呀,那只能造数据了,造得尽量自然,模拟100个用户,涵盖所有商品,比如其中10个用户是数码爱好者浏览的都是数码商品,后有就是用户的商品的偏爱程度即用户的评分,在此简化为1、0代表有兴趣和没兴趣,数据虽然比较粗糙,但不影响推荐结果。
项目下载地址:http://download.csdn.net/download/philics0725/9969284
先搭建个maven项目,配置依赖
<properties>
<org.springframework.version>4.1.3.RELEASE</org.springframework.version>
<struts2.version>2.3.1</struts2.version>
<log4j.version>2.0</log4j.version>
<mysql.jdbc.version>5.1.21</mysql.jdbc.version>
<hibernate.version>4.3.1.Final</hibernate.version>
<commons.fileupload.version>1.2.1</commons.fileupload.version>
<javassist.version>3.12.1.GA</javassist.version>
<cxf.version>3.0.2</cxf.version>
<fastjson.version>1.1.36</fastjson.version>
<hadoop.version>2.6.0</hadoop.version>
<mahout.version>0.10.0</mahout.version>
<hive.version>0.13.1</hive.version>
</properties>将网上商城程序迁移过来,调试进行正常,然后加入hadoop、mahout开发推荐功能,这时产生了两个报错折磨了我好久
1、java.lang.ClassNotFoundException,总是提示mahout.math中的某个类ClassNotFoundException,上网查了原因是maven依赖包冲突,处理方法,在pom.xml的Dependency Hierarchy中Exclude掉多余的就可以了。
2、org.apache.hadoop.util.Shell$ExitCodeException,调用mahout的mapreduce程序时报错,网上多说是classpath问题,但改了也没用,最后解决方法是将我虚拟机中的hadoop2.4.1改成和web项目中依赖的hadoop2.6.0版本就可以了,但我之前web项目2.6.0联虚拟机2.4.1调用自己写mapreduce程序都没有问题。
三、项目实现流程
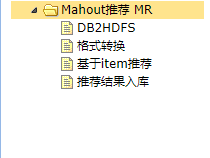
项目实现的流程按照系统首页左边导航栏的顺序从上到下运行,完成数据挖掘的各个步骤。
1、推荐数据由mysql上传至Hdfs
首先要加工好用户对商品偏好数据,放在表Recommenddata中
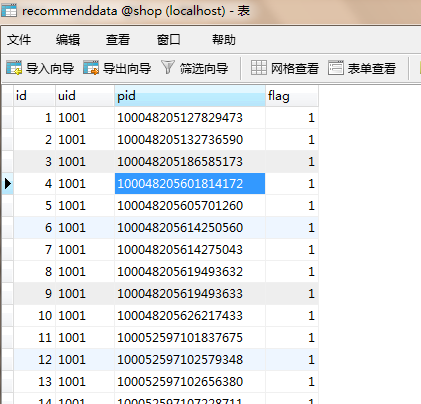
然后将表数据传至hdfs中
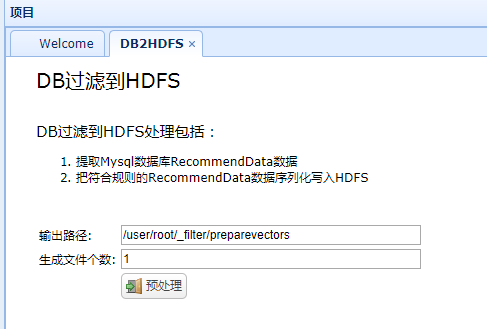
实现代码
public void db2hdfs(){
List<Object> list = dBService.getTableAllData("RecommendData");
Map<String,Object> map = new HashMap<String,Object>();
if(list.size()==0){
map.put("flag", "false");
Utils.write2PrintWriter(JSON.toJSONString(map));
return ;
}
try{
HUtils.db2hdfs(list,output,Integer.parseInt(record));
}catch(Exception e){
map.put("flag", "false");
map.put("msg", e.getMessage());
Utils.write2PrintWriter(JSON.toJSONString(map));
return ;
}
map.put("flag", "true");
Utils.write2PrintWriter(JSON.toJSONString(map));
return ;
}private static boolean db2hdfs(List<Object> list, Path path) throws IOException {
boolean flag =false;
int recordNum=0;
SequenceFile.Writer writer = null;
Configuration conf = getConf();
try {
Option optPath = SequenceFile.Writer.file(path);
Option optKey = SequenceFile.Writer
.keyClass(IntWritable.class);
Option optVal = SequenceFile.Writer.valueClass(LongWritable.class);
writer = SequenceFile.createWriter(conf, optPath, optKey, optVal);
LongWritable dVal = new LongWritable();
IntWritable dKey = new IntWritable();
for (Object recommenddata : list) {
dVal.set(getDoubleArr(recommenddata));
dKey.set(Integer.parseInt(getUidVal(recommenddata)));
writer.append(dKey, dVal);
recordNum++;
}
} catch (IOException e) {
Utils.simpleLog("db2HDFS失败,+hdfs file:"+path.toString());
e.printStackTrace();
flag =false;
throw e;
} finally {
IOUtils.closeStream(writer);
}
flag=true;
Utils.simpleLog("db2HDFS 完成,hdfs file:"+path.toString()+",records:"+recordNum);
return flag;
}

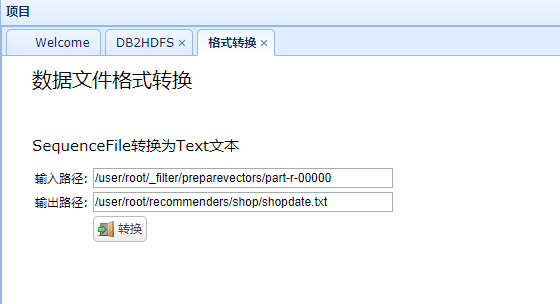
2、HDFS上数据格式进行转换
前台已经上传了文件,但还不能直接使用,上传的文本是SequenceFile格式不能直接查看,而且其内容格式为:
1[1001,100048205127829473,1],我们需要的是1001,100048205127829473,1并且是Text文本。
通过简单的mapreduce程序实现,只转出value中的值
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(String.class);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(String.class);
job.setInputFormatClass(SequenceFileInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);public class ExchangeMapper extends Mapper<IntWritable, LongWritable, NullWritable, String> {
public void map(IntWritable key, LongWritable value, Context cxt)throws InterruptedException,IOException{
cxt.write(null,key.toString()+','+value.toString()+",1");
}
}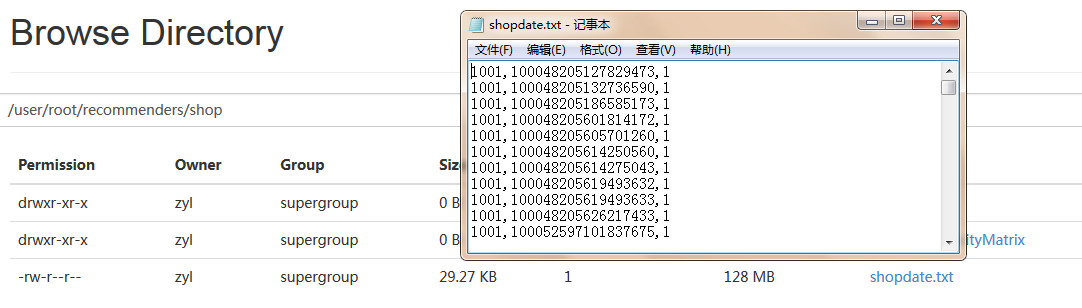
已经转换成了我想要的格式
3、调用mahout中Recommenderjob
有了输入数据就可以调用mahout中封装好的算法了
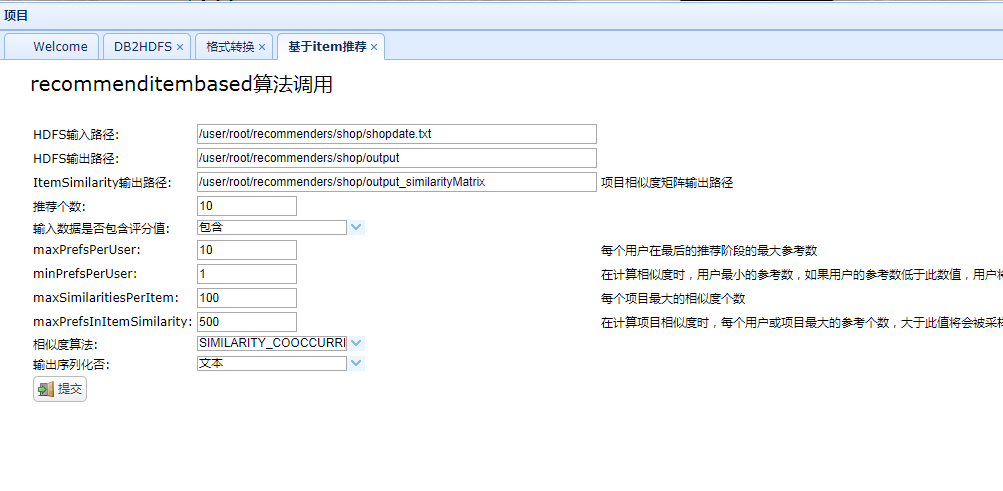
实现代码
public void run() {
String[] args=null;
if("true".equals(b)){// 包含评分值
if("true".equals(seq)){// true 序列化
args= new String[21];
args[20]="--sequencefileOutput";
}else{
args=new String[20];
// do nothing
}
}else{// 不包含评分值
if("true".equals(seq)){// 序列化
args= new String[22];
args[21]="--sequencefileOutput";
}else{// 输出不序列化
args=new String[21];
}
args[20]="-b";// 不包含评分值
}
args[0]="-i";
args[1]=input;
args[2]="-o";
args[3]=output;
args[4]="-opfsm";
args[5]=opfsm;
args[6]="-n";
args[7]=num;
args[8]="-mp";
args[9]=mp;
args[10]="-m";
args[11]=m;
args[12]="-mpiis";
args[13]=mpiis;
args[14]="-mxp";
args[15]=mxp;
args[16]="-s";
args[17]=s;
args[18]="--tempDir";
args[19]="temp";
Utils.printStringArr(args);
try {
HUtils.getFs().delete(new Path("temp"), true);
HUtils.getFs().delete(new Path(opfsm), true);
HUtils.getFs().delete(new Path(output), true);
int ret = ToolRunner.run(HUtils.getConf() ,new RecommenderJob() , args);
if(ret==0){// 所有任务运行完成
HUtils.setALLJOBSFINISHED(true);
}
} catch (Exception e) {
e.printStackTrace();
// 任务中,报错,需要在任务监控界面体现出来
HUtils.setRUNNINGJOBERROR(true);
Utils.simpleLog("RecommendItembased任务错误!");
}
}
File System Counters
FILE: Number of bytes read=62386
FILE: Number of bytes written=337931
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=685423
HDFS: Number of bytes written=1422
HDFS: Number of read operations=10
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=19752
Total time spent by all reduces in occupied slots (ms)=21456
Total time spent by all map tasks (ms)=19752
Total time spent by all reduce tasks (ms)=21456
Total vcore-seconds taken by all map tasks=19752
Total vcore-seconds taken by all reduce tasks=21456
Total megabyte-seconds taken by all map tasks=20226048
Total megabyte-seconds taken by all reduce tasks=21970944
Map-Reduce Framework
Map input records=708
Map output records=1110
Map output bytes=1022936
Map output materialized bytes=62378
Input split bytes=135
Combine input records=0
Combine output records=0
Reduce input groups=7
Reduce shuffle bytes=62378
Reduce input records=1110
Reduce output records=6
Spilled Records=2220
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=242
CPU time spent (ms)=1690
Physical memory (bytes) snapshot=239534080
Virtual memory (bytes) snapshot=734052352
Total committed heap usage (bytes)=137498624
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=669470
File Output Format Counters
Bytes Written=1422
再进行较长一段时间后得到推荐结果数据
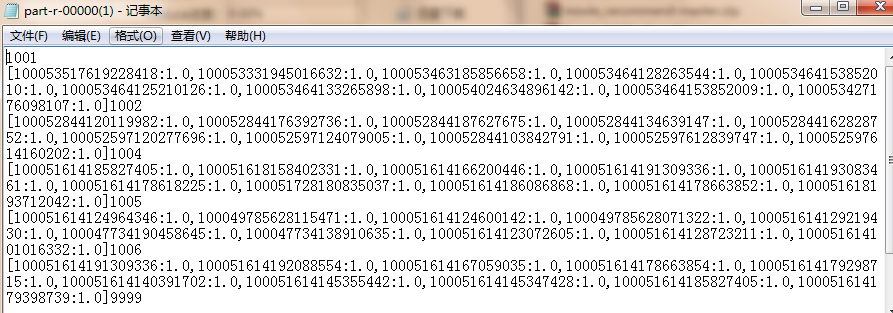
4、推荐结果解析入mysql
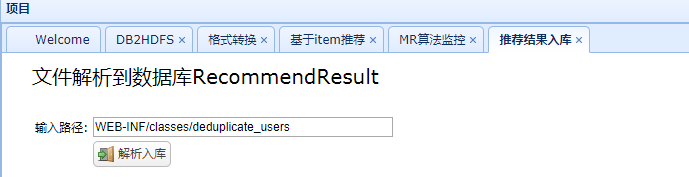
推荐结果数据先从HDFS上下载到本地再加载到mysql,原始数据是
9999 [100051614186086868:1.0,100051728630353203:1.0,100049785627281455:1.0,
100051618617622454:1.0,100051614641294949:1.0,100047734623818748:1.0,100051728180835037:1.0,
100051618167784461:1.0,100047734124747074:1.0,100051614623631023:1.0]
对9999这个用户推荐10件商品,数据需要再次转换成
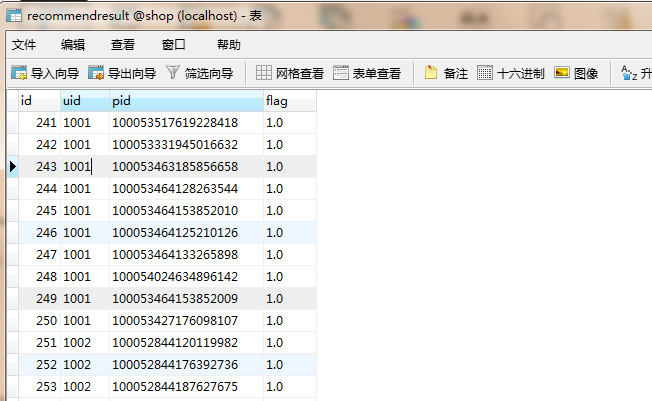
实现代码
public Map<String,Object> insertUserData(String xmlPath){
Map<String,Object> map = new HashMap<String,Object>();
try{
baseDao.executeHql("delete RecommendResult");
List<String[]>strings = Utils.parseDatFolder2StrArr(xmlPath);
List<Object> uds = new ArrayList<Object>();
for(String[] s:strings){
uds.add(new RecommendResult(s));
}
int ret =baseDao.saveBatch(uds);
log.info("推荐结果表批量插入了{}条记录!",ret);
}catch(Exception e){
e.printStackTrace();
map.put("flag", "false");
map.put("msg", e.getMessage());
return map;
}
map.put("flag", "true");
return map;
}public static List<String[]> parseDatFolder2StrArr(String datFolder) {
File folder = new File(datFolder);
List<String[]> list = new ArrayList<String[]>();
File[] files=null;
try{
files= folder.listFiles();
for(File f:files){
list.addAll(parseDat2StrArr(f.getAbsolutePath()));
}
}catch(Exception e){
e.printStackTrace();
}
return list;
}private static List<String[]> parseDat2StrArr(String datFile) throws IOException{
List<String[]> list = new ArrayList<String[]>();
FileReader reader = new FileReader(datFile);
BufferedReader br = new BufferedReader(reader);
Integer id = 1;
String line = null;
String[] arr= null;
while((line = br.readLine()) != null) {
String uid = line.substring(0, 4);
String results = line.substring(6,line.length()-1);
String[] resultstrs = results.split(",", -1);
for(int i=0;i< resultstrs.length;i++){
String[] resultdtstrs = resultstrs[i].split(":", -1);
arr=new String[userdata_attributes.length];
arr[0] = id.toString();
arr[1] = uid;
arr[2] = resultdtstrs[0];
arr[3] = resultdtstrs[1];
list.add(arr);
id ++ ;
}
}
br.close();
reader.close();
return list;
}首先登录用户,比如9999用户
在登录前不显示推荐商品,登录后展示推荐商品
登录9999用户

展示推荐结果
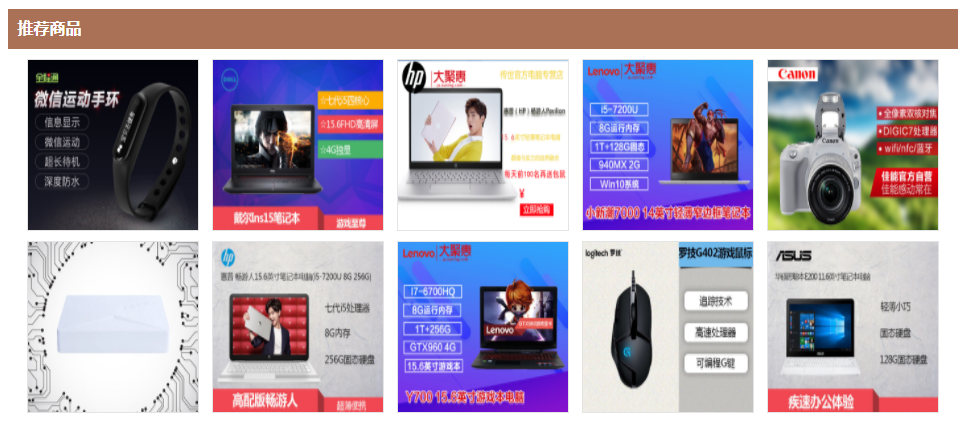
根据改用户的历史数据分析,推荐全理。
实现方式
// 查询推荐商品:
// 获得用户的id.
User existUser = (User) ServletActionContext.getRequest().getSession()
.getAttribute("existUser");
// 获得用户的id
if (existUser!= null){
Integer uid = existUser.getUid();
List<Product> rList = productService.findRecommend(uid);
// 保存到值栈中:
ActionContext.getContext().getValueStack().set("rList", rList);
} // 首页上推荐商品的查询
public List<Product> findRecommend(Integer uid) {
String hql = "select p from Product p,RecommendResult1 cs where p.pid = cs.pid and cs.uid = ?";
Query q = getSession().createQuery(hql).setInteger(0, uid);
List<Product> list = q.list();
if(list != null && list.size() > 0){
return list;
}
return null;
}实验结束!















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









