






在提取干旱特征时往往采用游程理论法,而我没有找到合适的python包,只能用广泛使用的matlab游程理论的方法,参考http://t.csdn.cn/xoDpW博文。
但对于多个站点应该如何提取?修改后的matlab代码如下:
folder = 'G:\Python_\ghtz\data\';
cd(folder)
files = dir('*.csv')
for i = 1:length(files)
filename = files(i).name
data = csvread(filename,1.0);
ds_array = data(:,2:4);
threshold = -0.5;
ds_event_properties = DisasterEventExtra(ds_array,threshold); % 调用函数
disp(ds_event_properties) % 查看灾害事件提取结果
disp('Finished')
writetable(ds_event_properties,filename)
end
data(:,2:4)中2和4指的是第2列和第4列,这里数行列的方式和python不同,python从0开始,matlab从1开始
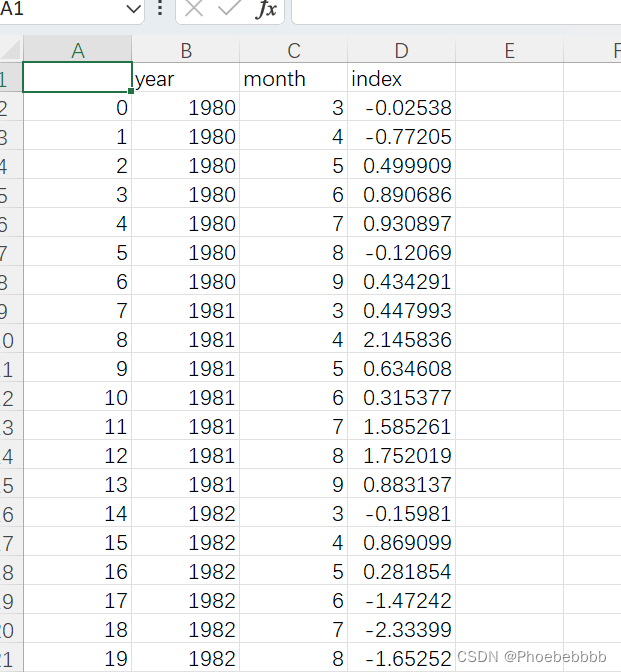
其中data的格式如下图,处理过程可以参考之前发布的http://t.csdn.cn/ZlH8L
处理后结果如下:
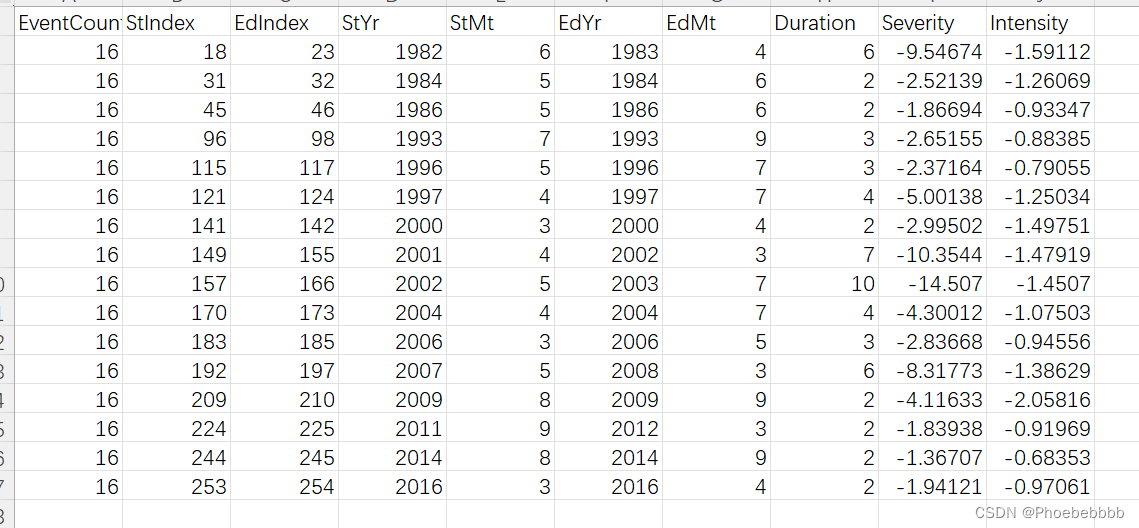

由此得出每个站点的干旱特征(每个csv文件名代表一个站点名),但需要将多个站点汇总进行arcgis画图,还需要以下代码。由于本人对matlab不太精通,所以选择用python处理。
import pandas as pd
import os
# 最大干旱历时
point_df = pd.DataFrame()
file=pd.read_csv("G:/Python_/ghtz/pointlocation.csv")
i=3305
j=0
while i < 13611:
data_path = "G:/Python_/ghtz/result"
if os.path.exists(data_path + "/" + str(i) + ".csv"):
data_1 = pd.read_csv(data_path + "/" + str(i) + ".csv")
for index, row in file.iterrows():
point_df.loc[j,'point_name'] = i
point_df.loc[j, 'duration'] = np.max(data_1['Duration'],axis=0)
#对于平均干旱历时,只需要把max改为mean即可
print(str(i) + '成功')
j += 1
i += 1
point_df.to_csv("G:/Python_/ghtz/max/duration.csv")对于干旱频率则需要先筛选index<-0.5的数,然后除以总数,我这里月份总数是266个月,所以除以266
# 干旱频率
point_df = pd.DataFrame()
file=pd.read_csv("G:/Python_/ghtz/pointlocation.csv")
i=3305
j=0
while i < 13611:
data_path = "G:/Python_/ghtz/data"
if os.path.exists(data_path + "/" + str(i) + ".csv"):
data_1 = pd.read_csv(data_path + "/" + str(i) + ".csv")
data_2 = data_1[data_1["index"] < -0.5]
fre = len(data_2) / 266
for index, row in file.iterrows():
point_df.loc[j,'point_name'] = i
point_df.loc[j, 'fre'] = fre
print(str(i) + '成功')
j += 1
i += 1
point_df.to_csv("G:/Python_/ghtz/fre/fre.csv")最后得出的数据如下,就可以导入arcgis进行绘图啦
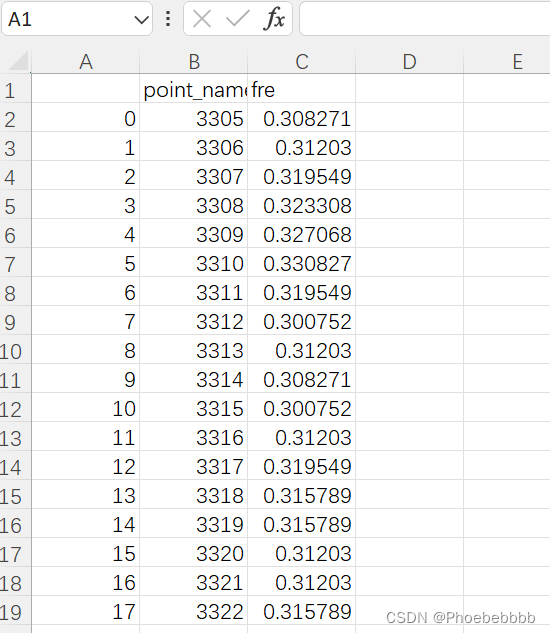
















 500
500











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









